



 PCA是重要的降维方法,通过找到数据的主要成分来替代原始高维数据。PCA有两种等价推导:最小化样本点到超平面的投影距离和最大化投影方差。降维时选取XXT的最大n'个特征值对应的特征向量组成矩阵W,原始数据乘以W即可实现降维。PCA与谱聚类的优化目标相反,谱聚类求最小特征值,PCA求最大特征值。
PCA是重要的降维方法,通过找到数据的主要成分来替代原始高维数据。PCA有两种等价推导:最小化样本点到超平面的投影距离和最大化投影方差。降维时选取XXT的最大n'个特征值对应的特征向量组成矩阵W,原始数据乘以W即可实现降维。PCA与谱聚类的优化目标相反,谱聚类求最小特征值,PCA求最大特征值。
主成分分析(Principal components analysis,以下简称PCA)是最重要的降维方法之一。在数据压缩消除冗余和数据噪音消除等领域都有广泛的应用。一般我们提到降维最容易想到的算法就是PCA,下面我们就对PCA的原理做一个总结。
01
PCA的思想
PCA顾名思义,就是找出数据里最主要的方面,用数据里最主要的方面来代替原始数据。具体的,假如我们的数据集是n维的,共有m个数据(x(1),x(2),...,x(m))。我们希望将这m个数据的维度从n维降到n'维,希望这m个n'维的数据集尽可能的代表原始数据集。我们知道数据从n维降到n'维肯定会有损失,但是我们希望损失尽可能的小。那么如何让这n'维的数据尽可能表示原来的数据呢?
我们先看看最简单的情况,也就是n=2, n'=1,也就是将数据从二维降维到一维。数据如下图。我们希望找到某一个维度方向,它可以代表这两个维度的数据。图中列了两个向量方向,u1和u2,那么哪个向量可以更好的代表原始数据集呢?从直观上也可以看出,u1比u2好。
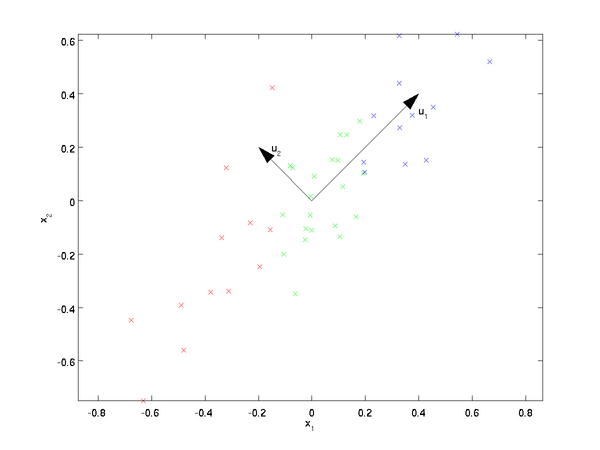
为什么u1比u2好呢?可以有两种解释,第一种解释是样本点到这个直线的距离足够近,第二种解释是样本点在这个直线上的投影能尽可能的分开。
假如我们把n'从1维推广到任意维,则我们的希望降维的标准为:样本点到这个超平面的距离足够近,或者说样本点在这个超平面上的投影能尽可能的分开。
基于上面的两种标准,我们可以得到PCA的两种等价推导。
02
PCA的推导:基于最小投影距离
我们首先看第一种解释的推导,即样本点到这个超平面的距离足够近。

现在我们考虑整个样本集,我们希望所有的样本到这个超平面的距离足够近,即最小化下式:
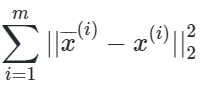
将这个式子进行整理,可以得到:
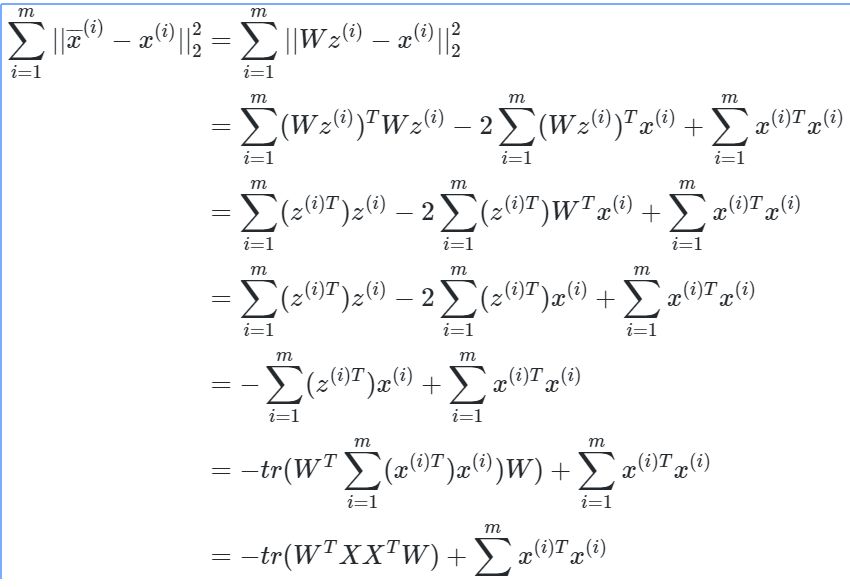

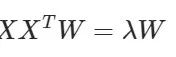
这样可以更清楚的看出,W为XXT的n'个特征向量组成的矩阵,而λ为XXT的若干特征值组成的矩阵,特征值在主对角线上,其余位置为0。当我们将数据集从n维降到n'维时,需要找到最大的n'个特征值对应的特征向量。这n'个特征向量组成的矩阵W即为我们需要的矩阵。对于原始数据集,我们只需要用
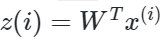
就可以把原始数据集降维到最小投影距离的n'维数据集。
如果你熟悉谱聚类的优化过程,就会发现和PCA的非常类似,只不过谱聚类是求前k个最小的特征值对应的特征向量,而PCA是求前k个最大的特征值对应的特征向量。
03
PCA的推导:基于最大投影方差
现在我们再来看看基于最大投影方差的推导。

观察第二节的基于最小投影距离的优化目标,可以发现完全一样,只是一个是加负号的最小化,一个是最大化。
利用拉格朗日函数可以得到
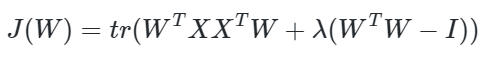
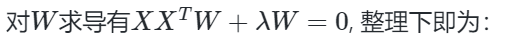
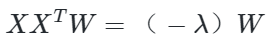
和上面一样可以看出,W为XXT的n'个特征向量组成的矩阵,而−λ为XXT的若干特征值组成的矩阵,特征值在主对角线上,其余位置为0。当我们将数据集从n维降到n'维时,需要找到最大的n'个特征值对应的特征向量。这n'个特征向量组成的矩阵W即为我们需要的矩阵。对于原始数据集,我们只需要用
就可以把原始数据集降维到最小投影距离的n'维数据集。

点击下方图片即可阅读

决策树算法原理(上)
决策树算法原理(下)

最常使用的数据挖掘算法——决策树

如果你也有想分享的干货,可以登录天池实验室(notebook),包括赛题的理解、数据分析及可视化、算法模型的分析以及一些核心的思路等内容。
小天会根据你分享内容的数量以及程度,给予丰富的神秘天池大礼以及粮票奖励。分享成功后你也可以通过下方钉钉群?主动联系我们的社区运营同学(钉钉号: yiwen1991)
天池宝贝们有任何问题,可在戳“留言”评论或加入钉钉群留言,小天会认真倾听每一个你的建议!


?

















 957
957

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









