 K-means聚类算法详解及实战应用
K-means聚类算法详解及实战应用





 本文介绍了K-means聚类算法的基本概念,包括其工作流程和选择K值的方法。通过实战部分,详细展示了算法的可视化过程以及如何在客户分层问题中应用K-means。
本文介绍了K-means聚类算法的基本概念,包括其工作流程和选择K值的方法。通过实战部分,详细展示了算法的可视化过程以及如何在客户分层问题中应用K-means。
聚类是一种无监督的学习,它将相似的对象归到同一个簇中。它有点像全自动分类。聚类与分类的最大不同在于,分类的目标事先已知,而聚类则不一样。因为其产生的结果与分类相同,而只是类别没有预先定义。聚类方法几乎可以应用于所有对象,簇内的对象越相似,聚类的效果越好。
本章要介绍一种称为K-均值(K-means)聚类的算法。这种算法可以发现k个不同的簇,且每个簇的中心采用簇中所含值的均值计算而成。
1. 基本介绍
K-均值是发现给定数据集的k个簇的算法。簇个数k是用户给定的,每一个簇通过其质心(centroid),即簇中所有点的中心来描述。该算法是循环迭代式的。
1.1 算法的工作流程
- 初始化:随机选择K个点作为初始中心点,每个点代表一个group
- 交替更新:计算每个点到所有中心点的距离,把最近的距离记录下来并把group赋给当前点;针对每一个group里的点,计算其平均并作为这个group的新的中心点
1.2 选择K值
首先画出K-means目标函数的图像,找到斜率开始变小所对应的K值。
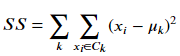
2. 实战
2.1 算法可视化
2.1.1 导入各种包和数据
# 导入相应的包
from copy import deepcopy
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
# 导入数据
data = pd.read_csv('data.csv')
#打印数据的大小和头五行
print("Input Data and Shape")
print(data.shape)
data.head() 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1075
1075

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









