






 提出一种统一资源定位符URL的去重方法,通过预处理分析参数并计数,根据计数结果决定是否启动强制去重,有效提升爬虫抓取及漏洞扫描效率。
提出一种统一资源定位符URL的去重方法,通过预处理分析参数并计数,根据计数结果决定是否启动强制去重,有效提升爬虫抓取及漏洞扫描效率。
本发明属于通信与计算机技术领域,尤其是涉及一种统一资源定位符url的去重方法。
背景技术:
统一资源定位符(uniformresourcelocator,url)爬虫是漏洞扫描系统的技术要点,网络爬虫是一个自动提取网页的程序,它可以自动地从网络中抓取网页,是搜索引擎的重要组成。其工作原理是:网页爬虫从初始设定的一个或者多个初始网页的url开始,获得初始网页上的url,在抓取网页的过程中,不断从当前网页上抽取新的url,然后根据网页分析算法过滤掉与无关链接,保留与策略一致的链接并将其存入url队列中,直到满足一定的停止条件。
去重是爬虫的核心,也是最影响爬虫效率和结果的部分。url去重指的是将重复抓取的url去除,避免多次抓取同一网页。去重过于粗放,在遇到页面比较多的网站时爬不完;而去重过于严格的话,爬取的结果太少,则会影响到后续漏洞扫描的效果。
现实中,存在一些不适用于常规去重的情况,例如:
…
当允许用户名参数(name)值可以为自定义的各种形式,且有成千上万个用户时,常规的去重策略,如简单的域名与参数对比、参数值匹配,以及字符串过滤等都过于粗略,直接把所有的纯英文字符串放过了,而且目前也缺乏更好的解决方案,去重效率不理想,影响爬虫与漏洞扫描的结果。
技术实现要素:
基于以上背景,特提出一种统一资源定位符url的去重方法,进行两次循环,在预处理中分析参数列表并计数,然后根据计数结果决定是否启动强制去重。
具体的技术方案是,一种统一资源定位符url的去重方法,包括以下步骤:
s1将第一待去重url数据加入去重任务队列,执行预处理,分析参数并计数,保存为第二待去重url数据;
s2判断第二待去重url数据,参数是否超过预设限定,若超过进行强制去重,若未超过则正常处理参数;
s3处理url的路径,判断当前url特征是否已存在,若已存在则回到s2,若不存在则保存特征并将去重结果输出。
作为优选的,s2中,所述强制去重包括:
分析参数列表并统计去重任务队列中的任务数,若任务数大于预设值,对参数列表或根路径相同的url,执行强制去重;
和/或,
分析参数列表并统计重复url的个数与具有相同参数值的url个数;若重复url个数大于预设值,且具有特定参数值的url个数大于预设值,将所述参数值替换为统一的指定字符串,执行强制去重。
s1中,所述对第一待去重url数据进行预处理,包括:对第一待去重url数据进行全局正则替换,处理得到参数列表;
若url属于非目标站点或完全重复的url,提取url的域名与参数,进行对比去重;所述完全重复的url包括参数被打乱但值仍相同的url。
预处理进行参数分析与路径拆分之前,将干扰字符替换为统一的指定字符串;优选的,将url中的数字替换为“{int}”,所述数字包括表示日期的字符串组合;将url中的英文-数字组合替换为“{mix_str}”。
所述预处理还包括:根据定义的路径去重策略,分隔伪静态url的路径,将符合策略规则的参数值替换为指定字符串,将不符合策略规则的参数值原样返回,再执行去重处理。
进一步的,所述伪静态url的去重,包括:分隔各参数,放入栈中,进行退栈操作,对比并判断倒数第二参数是否相同,若相同则为相同url、执行去重处理;若不同则继续向前递进、依次对比各参数并判断是否相同;直至所有参数对比完成并去重结束。
以上的技术方案,实现了以下有益效果:第一次循环只进行预处理,分析当前的参数列表,并计数;第二次循环,根据参数列表的计数值判断当前参数是否需要强制去重。一方面可以避免系统资源过多的消耗;另一方面可以根据去重策略调整去重粒度,针对特定的参数进行强制去重,保证去重效果,有利于提高爬虫抓取以及后续的漏洞扫描的效率。
附图说明
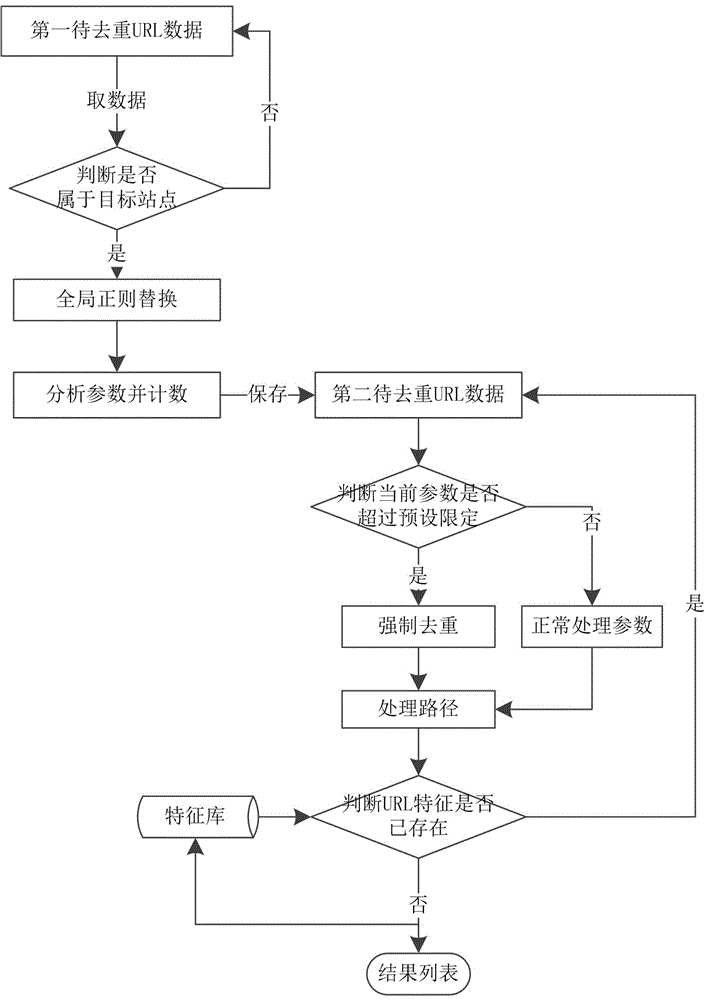
图1为url去重方法实施例的工作流程示意图。
具体实施方式
下面结合附图和实施例对本发明的具体技术方案进行详细说明。
去重一般分为任务队列的去重与结果队列的去重。这两种去重的区别在于,在爬虫运行过程中,任务队列是一直变动的(增加或减少),而结果队列是不断的增加的。对任务队列的去重,是在扫描过程中重复的进行,即某个页面爬取结束后,在获取的结果加入任务队列进行下一次爬虫任务之前,需要做一次去重(或者每完成一个深度的爬虫任务,进行一次去重);而结果队列是在所有的任务结束后进行去重,不会影响爬虫运行的效率,只影响最后的结果输出。这两种去重可以使用相同的去重策略,也可以使用不同的策略;也正因为如此,对任务队列的去重,可以根据当前的任务量,进行去重力度的调整。
如图1所示,url去重方法实施例的工作流程,包括以下步骤:
步骤一,将第一待去重url数据加入去重任务队列,执行预处理。
所述预处理包括判断url是否属于目标站点的链接,若url属于非目标站点,提取url的域名与参数,进行对比去重。
具体的步骤包括:
(1)从数据库取爬取的初始目标链接,用一个全局变量进行接收;
(2)使用字符串切割方法把初始目标链接的域名取出来;
(3)之后爬下来的每一条链接都与已处理好的域名进行比较,如果爬取下来的链接不含有初始链接的域名,则我们认为该链接为非目标站点的链接,进行过滤处理。
上述过程还需要考虑到多级域名的情况,比如,https://zhidao.baidu.com/,https://www.baidu.com/,可以直接取一级域名进行比较。
作为另一种实施方式,判断url是否属于重复的url,若属于完全重复的url,提取url的域名与参数,进行对比去重;所述完全重复的url包括参数被打乱但值仍相同的url。
所述预处理还包括对第一待去重url数据进行全局正则替换,处理得到参数列表。
常规的去重方式包括url参数值的匹配,例如int、hash、中文、url编码等。此处需要注意的是,不可以直接用匹配的方式处理英文的参数值。如:
其中m、c、a参数分别代表了不同的module、controller、action,属于“功能型参数”,需要保留。功能性参数的值在大多数情况下是字母(有意义的单词),有些情况下也会是数字或者数字字母的混合。
如果参数值为纯英文字母,那么就不能直接以参数类型进行去重,需要将参数值也一并取出来。如果是纯数字,则可以用int这一类型来代替,如下,如果是32位的字符数字,则用hash来代替,如果是混合参数值,则用mix_str代替并根据任务量的多少进行去重。
具体的步骤是:
(1)以‘’切割获取链接的所有参数
(2)用正则匹配参数值是否为纯英文,如果为纯英文,则留下,如果是纯数字则用{int}代替,如果是混合的,则用mix_str代替。
上述的正则,匹配参数值为全英文:stringregex4="[a-z|a-z]+";匹配全数字正则:stringregex5="[0-9]+";匹配混合非空字符正则:stringregex6=\\s+.举例如下,
去重处理前:
处理过程:
{"m":"home","c":"test","id":"{{int}}"}
{"m":"home","c":"test","id":"{{int}}"}
{"m":"home","c":"test","type":"friday"}
{"m":"home","c":"test","type":"{{hash}}"}
{"m":"home","c":"test","type":"{{hash}}"}
去重结果:
以上列表只是抽取参数的直观体现,并不一定要按照这个格式去实现编码,可以以其他更简单的形式进行组装,之后直接生成一个唯一串,用于后面的比较。
步骤一中所述的预处理,还包括:根据定义的路径去重策略,分隔伪静态url的路径,将符合策略规则的参数值替换为指定字符串,将不符合策略规则的参数值原样返回,再执行去重处理。
所述伪静态url的去重,包括:分隔各参数,放入栈中,进行退栈操作,对比并判断倒数第二参数是否相同,若相同则为相同url、执行去重处理;若不同则继续向前递进、依次对比各参数并判断是否相同;直至所有参数对比完成并去重结束。
作为优选实施方式,对常见的伪静态链接,分别使用不同的方法进行处理:
(1)没有具体的如.html或php的文件后缀且具有“/”,例如:
以“/”分割参数,去掉最后一个元素后生成字符串,存入集合进行比较去重。
(2)具有“/”但后面带日期格式:
使用正则:,进行匹配;若最后为日期格式(或数字),则用{int}类型代替。
(3)同一级目录下有很多相似数字命名的链接:
http://xue.zbj.com/live/cat17/11.html;
http://xue.zbj.com/live/cat17/12.html.
最多匹配三层数字名录;
使用的正则为:
(4)具有后缀且带有“-”的日期或连续数字格式
使用的正则为:.
对于以上所述的预处理,进行参数分析与路径拆分之前,优选的将干扰字符替换为统一的指定字符串;将url中的数字替换为“{int}”,所述数字包括表示日期的字符串组合,例如2017-03-27或者2017/03/27;将url中的英文-数字组合替换为“{mix_str}”;例如:
处理前:
替换后:
在有些情况下,上述的各种去重套路都不好用,比如:
当用户名为自定义,且有成千上万个用户的时候,上述的预处理策略过于粗略了,直接把所有的纯英文字符串放过了。此时在前述预处理基础上,增加一次强制去重,即执行步骤二。
步骤二,从预处理的参数列表取数据,分析参数并计数,保存为第二待去重url数据,判断当前参数是否超过预设限定,若超过进行强制去重,若未超过则正常处理参数;
作为优选实施方式,分析参数列表并统计去重任务队列中的任务数,若任务数大于预设值,对参数列表或根路径相同的url,执行强制去重;这种方案会误杀伪静态url。
而另一种实施方式是:
分析参数列表并统计重复url的个数与具有相同参数值的url个数;若重复url个数大于预设值,且具有特定参数值的url个数大于预设值,将所述参数值替换为统一的指定字符串,执行强制去重。
经过步骤二的强制去重,保证了url的去重效果,减少了资源消耗,从而有利于提高爬虫抓取以及后续的漏洞扫描的效率。
步骤三,处理url的路径,判断当前url特征是否已存在,若已存在则继续进行参数判断,若不存在则保存特征并将去重结果输出。
以上的技术方案,先进行预处理,分析当前的参数列表,并计数;再根据参数列表的计数值判断当前参数是否需要强制去重。一方面可以避免系统资源过多的消耗;另一方面可以根据去重策略调整去重粒度,针对特定的参数进行强制去重,保证去重效果,有利于提高爬虫抓取以及后续的漏洞扫描的效率。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。

















 303
303

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









