






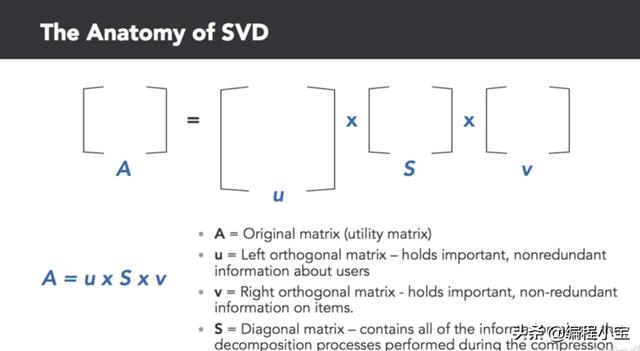
 本文介绍了一个使用截断奇异值分解(TruncatedSVD)的协同过滤系统,详细步骤包括数据准备、构建效用矩阵、矩阵分解、生成相关矩阵等。通过分析MovieLens数据集,演示如何推荐与《星球大战》(1977)高度相关的电影。
本文介绍了一个使用截断奇异值分解(TruncatedSVD)的协同过滤系统,详细步骤包括数据准备、构建效用矩阵、矩阵分解、生成相关矩阵等。通过分析MovieLens数据集,演示如何推荐与《星球大战》(1977)高度相关的电影。

在这篇文章中,我将逐步提供一个基于模型的协同过滤系统,该系统使用截断奇异值分解。
我们将从Sci-Kit Learn导入numpy,pandas和TruncatedSVD开始。SVD是一种线性代数方法,可用于将效用矩阵分解为三个压缩矩阵。SVD提供了可用的新变量并影响数据集的行为。
import numpy as npimport pandas as pdimport sklearnfrom sklearn.decomposition import TruncatedSVD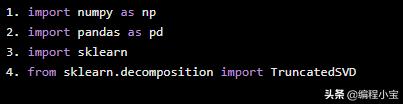
在本教程中,我们将使用由明尼苏达大学GroupLens研究项目收集的MovieLens数据集。请在此链接下载数据集。
准备数据
首先,我们将创建一个由user_id,item_id,rating和timestamp组成的columns。我们将把csv文件中的数据提取到我们创建的表中。Python代码如下:
## separate the data fetched from csv file with tab ''## fetched from u.datacolumns = ['user_id', 'item_id', 'rating', 'timestamp']frame = pd.read_csv('ml-100k/u.data', sep='', names=columns)frame.head()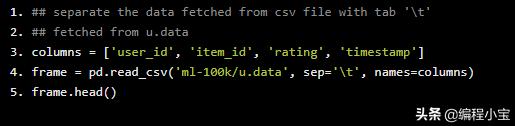
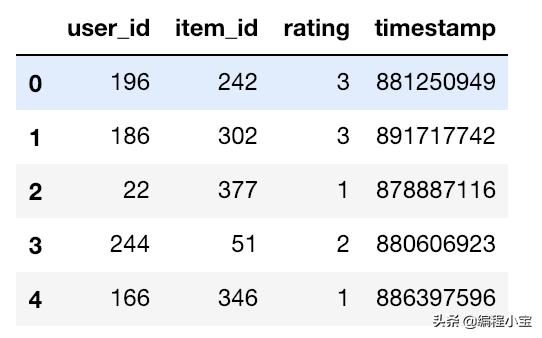
显示每个用户和他们所评论的电影的等级
然后,我们将创建一个名为columns的列表,其中包括item_id, movie title, release date, video release datas, IMDB IRL, unknown, action, adventure, animation, children和其电影类别。
## fetched from u.itemcolumns = ['item_id', 'movie title', 'release date', 'video release date', 'IMDb URL', 'unknown', 'Action', 'Adventure', 'Animation', 'Childrens', 'Comedy', 'Crime', 'Documentary', 'Drama', 'Fantasy', 'Film-Noir', 'Horror', 'Musical', 'Mystery', 'Romance', 'Sci-Fi', 'Thriller', 'War', 'Western']movies = pd.read_csv('ml-100k/u.item', sep='|', names=columns, encoding='latin-1')movie_names = movies[['item_id', 'movie title']]movie_names.head()
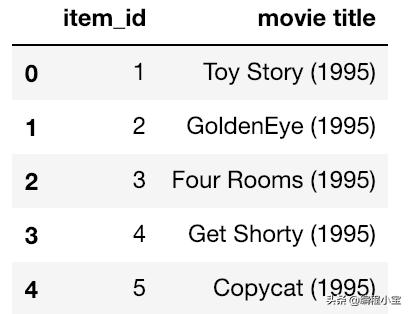
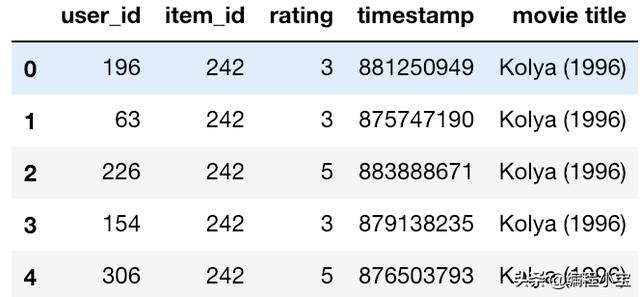
然后,我们将这些全部组合到一个名为combined_movies_data的表中,这个表由一个frame和电影名称组成,然后我们将传递参数。
combined_movies_data = pd.merge(frame, movie_names, on='item_id')combined_movies_data.head()
现在我们将检查评论次数最多的电影。
combined_movies_data.groupby('item_id')['rating'].count().sort_values(ascending=False).head()
然后我们将检查item_id为50的影片是什么。因为我们只想要唯一的记录,而不是每个条目ID = 50的记录,所以我们将使用.unique()函数。
filter = combined_movies_data['item_id']==50combined_movies_data[filter]['movie title'].unique()
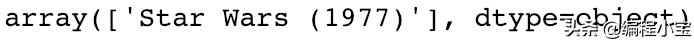
构建效用矩阵
在本节中,我们将创建一个矩阵,它将是一个交叉表矩阵,它将从组合的电影数据生成。
rating_crosstab = combined_movies_data.pivot_table(values='rating', index='user_id', columns='movie title', fill_value=0)rating_crosstab.head()
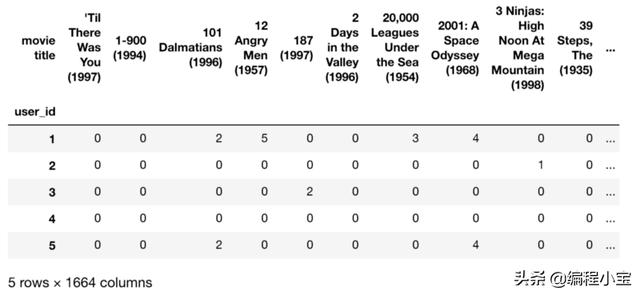
转置矩阵
接下来,我们将对这个实用程序矩阵进行转置,稍后我们将使用SVD将其分解为用户评论的合成表示。我们要把这个叫做X。
rating_crosstab.shape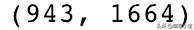
X = rating_crosstab.TX.shape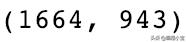
分解矩阵
现在让我们分解它。我们将结果矩阵设置为12维。
## passing random_state = 17 to get the same repeatable resultsSVD = TruncatedSVD(n_components=12, random_state=17)resultant_matrix = SVD.fit_transform(X)resultant_matrix.shape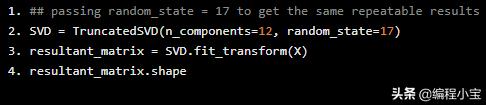
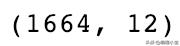
生成相关矩阵
我们想要根据用户的口味了解每部电影与其他电影的相似程度。我们使用Pearson的R相关系数来做到这一点。相关矩阵将返回1,664x1,664矩阵。我们关注一下Star Wars(1977)。
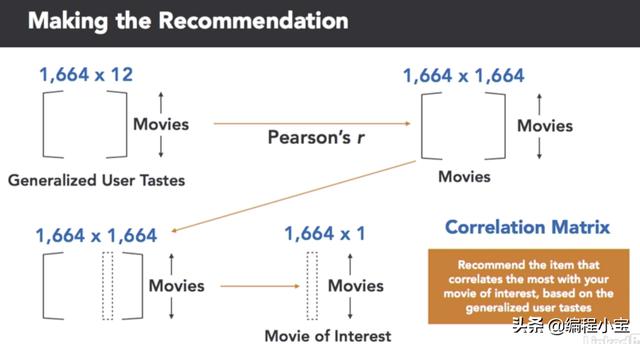
对于矩阵中的每个电影对,我们将基于用户视角计算它们之间的关联。为此,我们将使用numpy的corrcoef函数,并将其传递给resultant_matrix。
corr_mat = np.corrcoef(resultant_matrix)corr_mat.shape
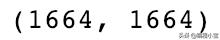
从相关矩阵中分离Star Wars
我们已经有了一个1664×1664的相关矩阵,现在我们把Star Wars从这个相关矩阵中分离出来。首先,我们将生成一个电影名称索引。
## pulling the movie names from ratings crosstab columns## convert numpy array to a list then retrieve index of Star Wars, 1977movie_names = rating_crosstab.columnsmovies_list = list(movie_names)star_wars = movies_list.index('Star Wars (1977)')star_wars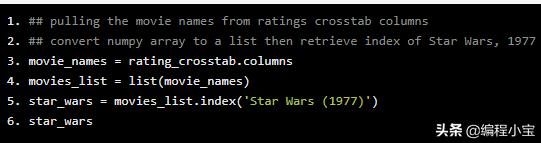
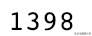
index for Star Wars (1977)
## isolating the array that represents Star Warscorr_star_wars = corr_mat[1398]corr_star_wars.shapeoutput -> (1664,)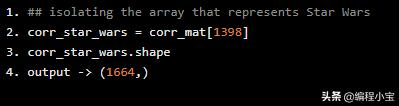
推荐高度相关的电影
现在让我们生成与Star Wars相关的电影名称列表。
list(movie_names[(corr_star_wars<1.0) & (corr_star_wars > 0.9)])
最后,我们将仅检索Pearson R系数接近1的电影。
list(movie_names[(corr_star_wars<1.0) & (corr_star_wars > 0.95)])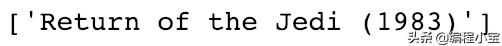


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









