









学习beautifulsoup
介绍
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间.
Beautiful Soup 官方文档(中文):
https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, 'html.parser')
print(soup.prettify())
>>>
# <html>
# <head>
# <title>
# The Dormouse's story
# </title>
# </head>
# <body>
# <p class="title">
# <b>
# The Dormouse's story
# </b>
# </p>
# <p class="story">
# Once upon a time there were three little sisters; and their names were
# <a class="sister" href="http://example.com/elsie" id="link1">
# Elsie
# </a>
# ,
# <a class="sister" href="http://example.com/lacie" id="link2">
# Lacie
# </a>
# and
# <a class="sister" href="http://example.com/tillie" id="link2">
# Tillie
# </a>
# ; and they lived at the bottom of a well.
# </p>
# <p class="story">
# ...
# </p>
# </body>
# </html>
使用BeautifulSoup解析这段代码,能够得到一个 BeautifulSoup 的对象,并能按照标准的缩进格式的结构输出。
小练习
任务:使用beautifulsoup提取丁香园论坛的回复内容
BeautifulSoup是一个可以将复杂的HTML文档转换成一个复杂的树形结构,每个节点都是python对象,所有对象可以归纳为4种:Tag、NavigableString、BeautifuSoup和Comment。
Step1 用户浏览器访问目标网站并检查目标内容所在标签
目标网址:http://www.dxy.cn/bbs/thread/626626
按F12可看见网站结构及回复内容所在标签如下图:
选中某一部分评论然后右键 -> 检查
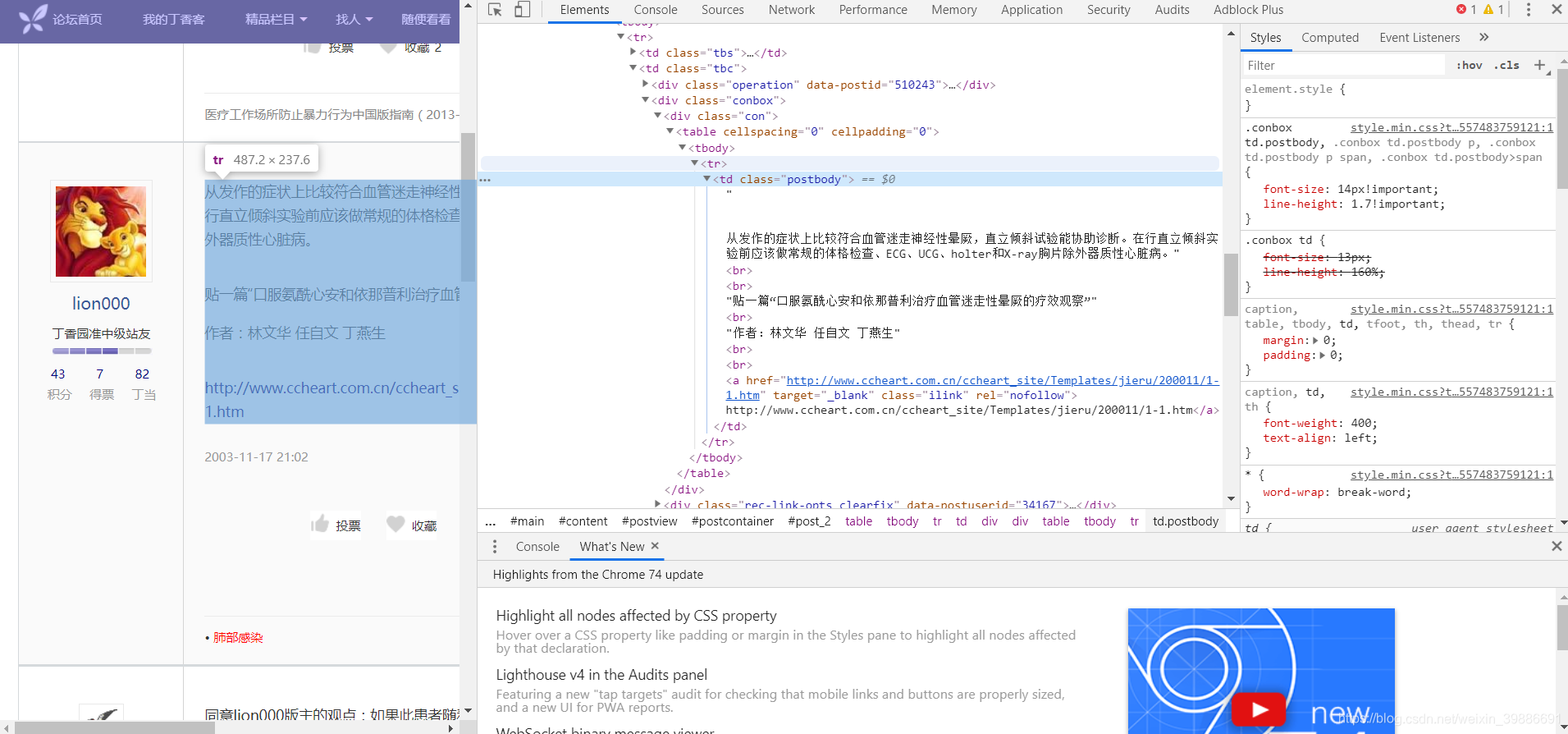
Tag 其实就是HTML 中的一个个标签,例如上面的td、a 等等HTML 标签加上里面包括的内容就是Tag。
Step2 获取回复内容
我们所需的评论内容就在td class="postbody"标签下,利用BeautifulSoup获取内容
content = data.find("td", class_="postbody").text
同样,我们可以获取用户名和其他信息
主要是BeautifulSoup的用法要掌握。
find函数用法:
find(name, attrs, recursive, text, **wargs) # recursive 递归的,循环的
这些参数相当于过滤器一样可以进行筛选处理。
不同的参数过滤可以应用到以下情况:
查找标签,基于name参数
查找文本,基于text参数
基于正则表达式的查找
查找标签的属性,基于attrs参数
基于函数的查找
import urllib.request
from bs4 import BeautifulSoup as bs
def main():
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0"
}
url = 'http://www.dxy.cn/bbs/thread/626626'
request = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(request).read().decode("utf-8")
html = bs(response, 'lxml')
getItem(html)
def getItem(html):
datas = [] # 用来存放获取的用户名和评论
for data in html.find_all("tbody"):
try:
userid = data.find("div", class_="auth").get_text(strip=True)
print(userid)
content = data.find("td", class_="postbody").get_text(strip=True)
print(content)
datas.append((userid,content))
except:
pass
print(datas)
if __name__ == '__main__':
main()
报错!!!
Failed to establish a new connection: [WinError 10061] 由于目标计算机积极拒绝,无法连接。
解决:
找到自己默认的浏览器(我用的是chrome),打开浏览器设置中的代理设置,接着再打开局域网设置,将代理服务器下面的勾给去掉,OK。就是这么nice
输出:
楼医生
我遇到一个“怪”病人,向大家请教。她,42岁。反复惊吓后晕厥30余年。每次受响声惊吓后发生跌倒,短暂意识丧失。无逆行性遗忘,无抽搐,无口吐白沫,无大小便失禁。多次跌倒致外伤。婴儿时有惊厥史。入院查体无殊。ECG、24小时动态心电图无殊;头颅MRI示小软化灶;脑电图无殊。入院后有数次类似发作。请问该患者该做何诊断,还需做什么检查,治疗方案怎样?
lion000
从发作的症状上比较符合血管迷走神经性晕厥,直立倾斜试验能协助诊断。在行直立倾斜实验前应该做常规的体格检查、ECG、UCG、holter和X-ray胸片除外器质性心脏病。贴一篇“口服氨酰心安和依那普利治疗血管迷走性晕厥的疗效观察”作者:林文华 任自文 丁燕生http://www.ccheart.com.cn/ccheart_site/Templates/jieru/200011/1-1.htm
xghrh
同意lion000版主的观点:如果此患者随着年龄的增长,其发作频率逐渐减少且更加支持,不知此患者有无这一特点。入院后的HOLTER及血压监测对此患者只能是一种安慰性的检查,因在这些检查过程中患者发病的机会不是太大,当然不排除正好发作的情况。对此患者应常规作直立倾斜试验,如果没有诱发出,再考虑有无可能是其他原因所致的意识障碍,如室性心动过速等,但这需要电生理尤其是心腔内电生理的检查,毕竟是有一种创伤性方法。因在外地,下面一篇文章可能对您有助,请您自己查找一下。心理应激事件诱发血管迷走性晕厥1例 ,杨峻青、吴沃栋、张瑞云,中国神经精神疾病杂志, 2002 Vol.28 No.2
keys
该例不排除精神因素导致的,因为每次均在受惊吓后出现。当然,在作出此诊断前,应完善相关检查,如头颅MIR(MRA),直立倾斜试验等。
[('楼医生', '我遇到一个“怪”病人,向大家请教。她,42岁。反复惊吓后晕厥30余年。每次受响声惊吓后发生跌倒,短暂意识丧失。无逆行性遗忘,无抽搐,无口吐白沫,无大小便失禁。多次跌倒致外伤。婴儿时有惊厥史。入院查体无殊。ECG、24小时动态心电图无殊;头颅MRI示小软化灶;脑电图无殊。入院后有数次类似发作。请问该患者该做何诊断,还需做什么检查,治疗方案怎样?'), ('lion000', '从发作的症状上比较符合血管迷走神经性晕厥,直立倾斜试验能协助诊断。在行直立倾斜实验前应该做常规的体格检查、ECG、UCG、holter和X-ray胸片除外器质性心脏病。贴一篇“口服氨酰心安和依那普利治疗血管迷走性晕厥的疗效观察”作者:林文华 任自文 丁燕生http://www.ccheart.com.cn/ccheart_site/Templates/jieru/200011/1-1.htm'), ('xghrh', '同意lion000版主的观点:如果此患者随着年龄的增长,其发作频率逐渐减少且更加支持,不知此患者有无这一特点。入院后的HOLTER及血压监测对此患者只能是一种安慰性的检查,因在这些检查过程中患者发病的机会不是太大,当然不排除正好发作的情况。对此患者应常规作直立倾斜试验,如果没有诱发出,再考虑有无可能是其他原因所致的意识障碍,如室性心动过速等,但这需要电生理尤其是心腔内电生理的检查,毕竟是有一种创伤性方法。因在外地,下面一篇文章可能对您有助,请您自己查找一下。心理应激事件诱发血管迷走性晕厥1例 ,杨峻青、吴沃栋、张瑞云,中国神经精神疾病杂志, 2002 Vol.28 No.2'), ('keys', '该例不排除精神因素导致的,因为每次均在受惊吓后出现。当然,在作出此诊断前,应完善相关检查,如头颅MIR(MRA),直立倾斜试验等。')]
学习xpath
什么是 XPath?
XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。
在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。XML 文档是被作为节点树来对待的。
选取节点
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。
下面列出了最有用的路径表达式:

实例
在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:

小练习
任务:使用xpath提取丁香园论坛的回复内容。
解决:
import requests
from lxml import etree
class getUrl(object):
def __init__(self):
self.headers = {
"Connection": "keep-alive",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0"
}
def run(self):
url = 'http://www.dxy.cn/bbs/thread/626626'
req = requests.get(url, headers = self.headers)
html = req.text
tree = etree.HTML(html)
user = tree.xpath('//div[@class="auth"]/a/text()')
content = tree.xpath('//td[@class="postbody"]')
for i in range(len(user)):
print(user[i].strip() + ":" + content[i].xpath('string(.)').strip())
print('*' * 80)
if __name__ == "__main__":
getUrl = getUrl()
getUrl.run()
输出:
楼医生:我遇到一个“怪”病人,向大家请教。她,42岁。反复惊吓后晕厥30余年。每次受响声惊吓后发生跌倒,短暂意识丧失。无逆行性遗忘,无抽搐,无口吐白沫,无大小便失禁。多次跌倒致外伤。婴儿时有惊厥史。入院查体无殊。ECG、24小时动态心电图无殊;头颅MRI示小软化灶;脑电图无殊。入院后有数次类似发作。请问该患者该做何诊断,还需做什么检查,治疗方案怎样?
********************************************************************************
lion000:从发作的症状上比较符合血管迷走神经性晕厥,直立倾斜试验能协助诊断。在行直立倾斜实验前应该做常规的体格检查、ECG、UCG、holter和X-ray胸片除外器质性心脏病。贴一篇“口服氨酰心安和依那普利治疗血管迷走性晕厥的疗效观察”作者:林文华 任自文 丁燕生http://www.ccheart.com.cn/ccheart_site/Templates/jieru/200011/1-1.htm
********************************************************************************
xghrh:同意lion000版主的观点:如果此患者随着年龄的增长,其发作频率逐渐减少且更加支持,不知此患者有无这一特点。入院后的HOLTER及血压监测对此患者只能是一种安慰性的检查,因在这些检查过程中患者发病的机会不是太大,当然不排除正好发作的情况。对此患者应常规作直立倾斜试验,如果没有诱发出,再考虑有无可能是其他原因所致的意识障碍,如室性心动过速等,但这需要电生理尤其是心腔内电生理的检查,毕竟是有一种创伤性方法。因在外地,下面一篇文章可能对您有助,请您自己查找一下。心理应激事件诱发血管迷走性晕厥1例 ,杨峻青、吴沃栋、张瑞云,中国神经精神疾病杂志, 2002 Vol.28 No.2
********************************************************************************
keys:该例不排除精神因素导致的,因为每次均在受惊吓后出现。当然,在作出此诊断前,应完善相关检查,如头颅MIR(MRA),直立倾斜试验等。
********************************************************************************
补充
Xpath中 text()、string()的区别
t
e
x
t
(
)
是
一
个
n
o
d
e
t
e
s
t
,
而
s
t
r
i
n
g
(
)
是
一
个
函
数
,
d
a
t
a
(
)
是
一
个
函
数
且
可
以
保
留
数
据
类
型
。
此
外
,
还
有
点
号
(
.
)
表
示
当
前
节
点
。
text()是一个node test,而string()是一个函数,data()是一个函数且可以保留数据类型。此外,还有点号(.)表示当前节点。
text()是一个nodetest,而string()是一个函数,data()是一个函数且可以保留数据类型。此外,还有点号(.)表示当前节点。
参考:https://blog.youkuaiyun.com/weixin_39285616/article/details/78463091

















 931
931

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









