



 本文介绍了R语言中dplyr包的使用,包括选择列、筛选行、对行排序、修改列和分组汇总等基本数据操作。通过dplyr的函数,如select、filter、arrange、mutate和summarize,可以实现复杂的数据处理任务。文章还提到了如何使用rowsums函数与其他函数结合,进行多列的选择和修改。此外,还探讨了如何删除重复行、按条件筛选行、对行排序和创建新列的方法。文章强调了dplyr函数的管道操作和不改变原始数据的特点,使数据操作更加便捷。
本文介绍了R语言中dplyr包的使用,包括选择列、筛选行、对行排序、修改列和分组汇总等基本数据操作。通过dplyr的函数,如select、filter、arrange、mutate和summarize,可以实现复杂的数据处理任务。文章还提到了如何使用rowsums函数与其他函数结合,进行多列的选择和修改。此外,还探讨了如何删除重复行、按条件筛选行、对行排序和创建新列的方法。文章强调了dplyr函数的管道操作和不改变原始数据的特点,使数据操作更加便捷。


用 dplyr 包实现各种数据操作,通常的数据操作无论多么复杂,往往都可以分解为若干基本数据操作步骤的组合。
共有 5 种基本数据操作:
select()——选择列filter()/slice()——筛选行arrange()—— 对行排序mutate()——修改列/创建新列summarize()——汇总
这些函数都可以与
group_by()——分组
连用,以改变数据操作的作用域:作用在整个数据框,或数据框的每个分组。
这些函数组合使用就足以完成各种数据操作,它们的相同之处是:
- 第 1 个参数是数据框,方便管道操作
- 根据列名访问数据框的列,且列名不用加引号
- 返回结果是一个新数据框,不改变原数据框
从而,可以方便地实现:"将多个简单操作,依次用管道连接,实现复杂的数据操
作"。
另外,若要同时对所选择的多列应用函数,还有强大的 across() 函数,它支持各种选择列语法,搭配 mutate() 和 summarise() 使用,产生非常强大同时修改/汇总多列的效果。
2.5.1 选择列
选择列,包括对数据框做选择列、调整列序、重命名列。
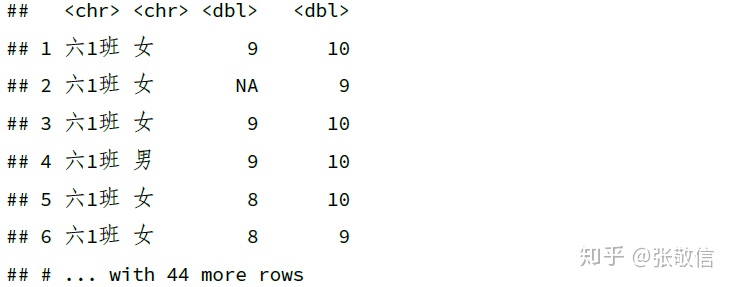
下面以虚拟的学生成绩数据来演示,包含随机生成的 20 个 NA:
df = read_xlsx("datas/ExamDatas_NAs.xlsx")
df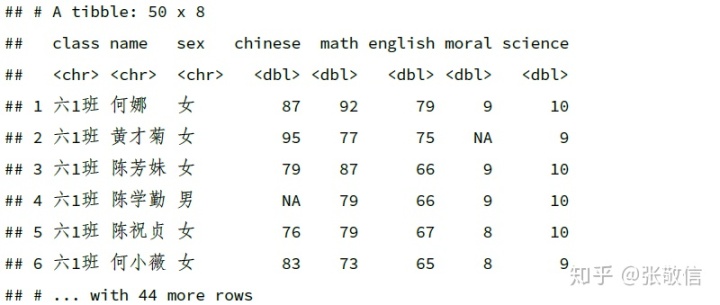
1. 选择列语法
(1) 用列名或索引选择列
df %>%
select(name, sex, math) # 或者select(2, 3, 5)
(2) 借助运算符选择列
- 用
:选择连续的若干列 - 用
!选择变量集合的余集(反选) &和|选择变量集合的交或并c()合并多个选择
(3) 借助选择助手函数
选择指定列:
everything(): 选择所有列last_col(): 选择最后一列,可以带参数,如last_col(5)选择倒数第 6 列
选择列名匹配的列:
starts_with(): 以某前缀开头的列名ends_with(): 以某后缀结尾的列名contains(): 包含某字符串的列名matches(): 匹配正则表达式的列名num_range(): 匹配数值范围的列名,如num_range("x", 1:3)匹配x1, x2, x3
结合函数选择列:
where(): 应用一个函数到所有列,选择返回结果为TRUE的列,比如与is.numeric等函数连用
2. 一些选择列的示例
df %>%
select(starts_with("m"))
df %>%
select(ends_with("e"))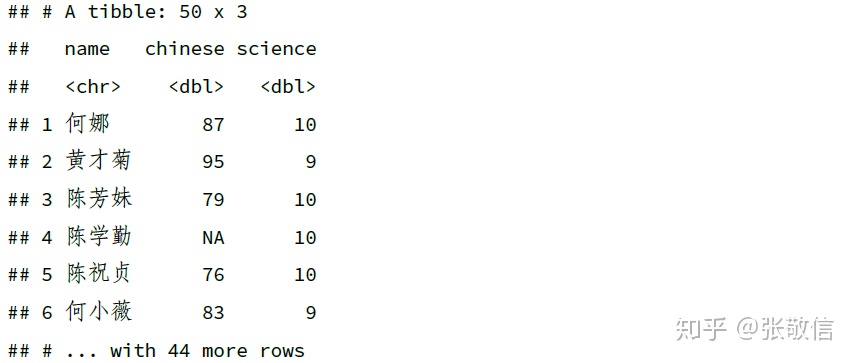
df %>%
select(contains("a"))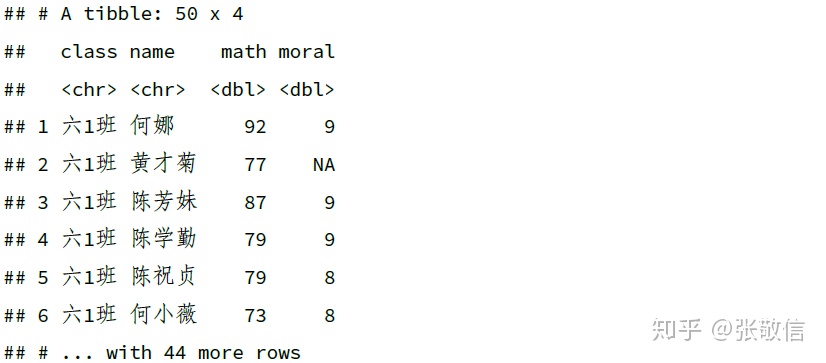
- 根据正则表达式匹配选择列:
df %>%
select(matches("m.*a"))

- 根据条件(逻辑判断)选择列,例如选择所有数值型的列:
df %>%
select(where(is.numeric))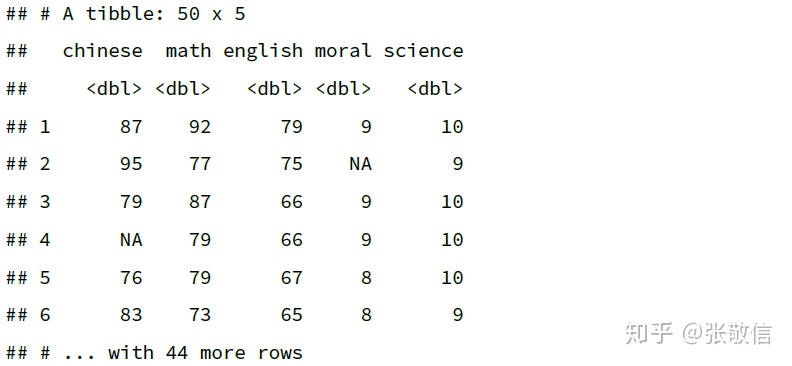
也可以自定义返回 TURE 或 FALSE 的判断函数,支持 purrr 风格公式写法。例如,选择列和 > 3000 的列:
df[, 4:8] %>%
select(where(~ sum(.x, na.rm = TRUE) > 3000))
再比如,结合 n_distinct() 选择唯一值数目 < 10 的列:
df %>%
select(where(~ n_distinct(.x) < 10))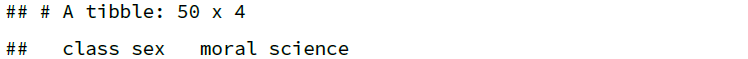
3. 用 - 删除列
df %>%
select(-c(name, chinese, science)) # 或者select(-ends_with("e"))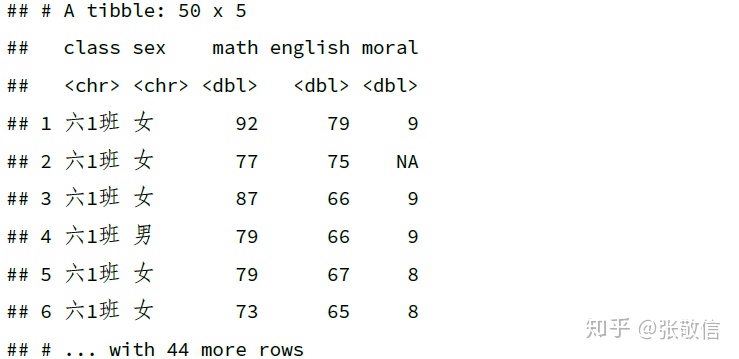
df %>%
select(math, everything(), -ends_with("e"))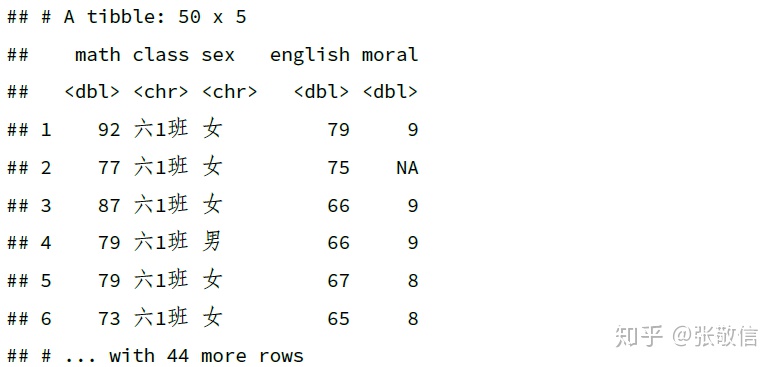
注意: -ends_with() 要放在 everything() 后面,否则删除的列就全回来了。
4. 调整列的顺序
列是根据被选择的顺序排列:
df %>%
select(ends_with("e"), math, name, class, sex)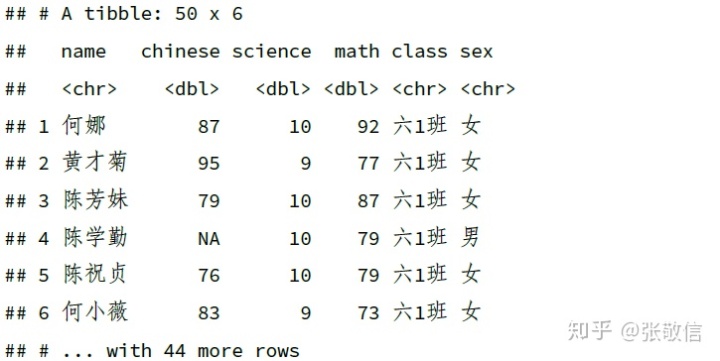
everything() 返回未被选择的所有列,将某一列移到第一列时很方便:
df %>%
select(math, everything())
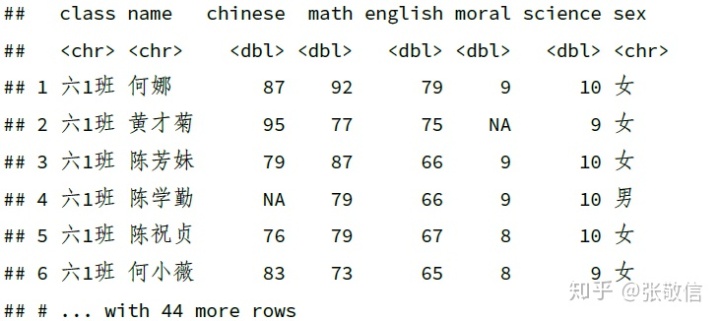
用 relocate() 函数,将选择的列移到某列之前或之后,基本语法为:
relocate(.data, ..., .before, .after)例如,将数值列移到 name 列的后面:
df %>%
relocate(where(is.numeric), .after = name)
5. 重命名列
set_names() 为所有列设置新列名:
df %>%
set_names(" 班级", " 姓名", " 性别", " 语文", " 数学", " 英语", " 品德", " 科学")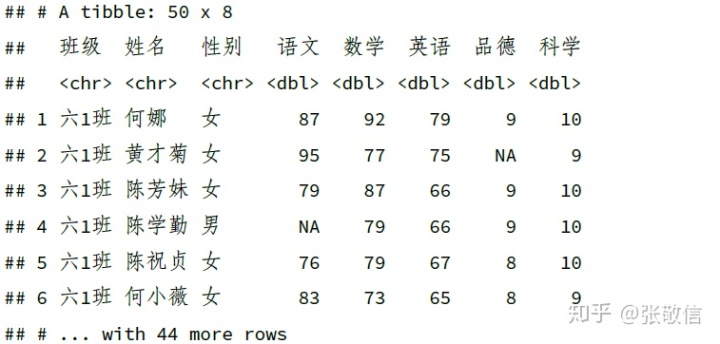
rename() 只修改部分列名,格式为:新名= 旧名
df %>%
rename(数学= math, 科学= science)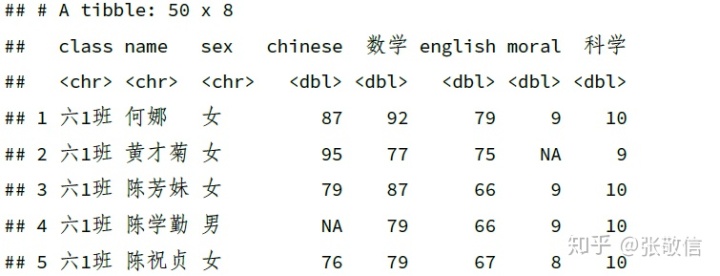
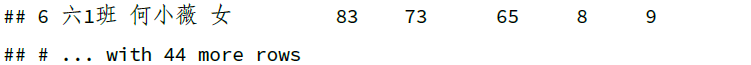

2.5.2 筛选行
筛选行,即按行选择数据子集,包括删除行、对行切片、过滤行。
先创建一个包含重复行的数据框:
set.seed(123)
df_dup <- df %>%
slice_sample(n = 60, replace = TRUE)1. 删除行
(1) 删除重复行
用 dplyr 包中的 distinct() 删除重复行(只保留第 1 个,删除其余)。
df_dup %>%
distinct()
也可以只根据某些列判定重复:
df_dup %>%
distinct(sex, math, .keep_all = TRUE) # 只根据sex 和math 判定重复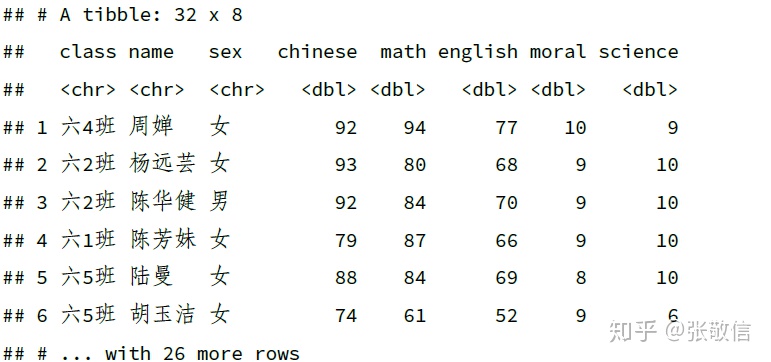
注:默认只返回选择的列,要返回所有列,需要设置参数 .keep_all = TRUE。
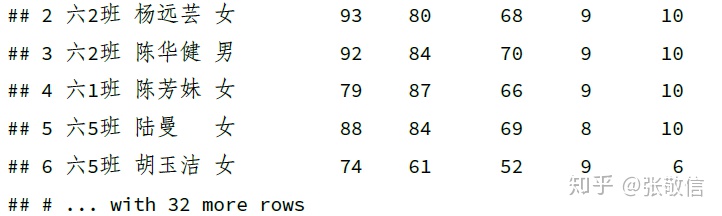
(2) 删除包含 NA 的行
用 tidyr 包中的 drop_na() 删除所有包含 NA 的行:
df_dup %>%
drop_na()
也可以只删除某些列包含 NA 的行:
df_dup %>%
drop_na(sex:math)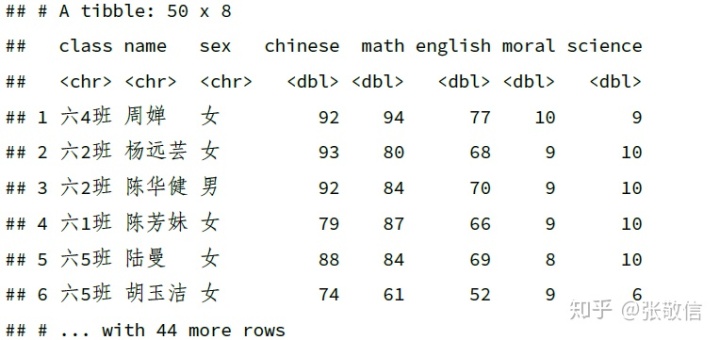
2. 对行切片:slice_*()
slice 就是对行切片的意思,该系列函数的共同参数:
n: 用来指定要选择的行数prop: 用来指定选择的行比例
slice(df, 3:7) # 选择3-7 行
slice_head(df, n, prop) # 从前面开始选择若干行
slice_tail(df, n, prop) # 从后面开始选择若干行
slice_min(df, order_by, n, prop) # 根据order_by 选择最小的若干行
slice_max(df, order_by, n, prop) # 根据order_by 选择最大的若干行
slice_sample(df, n, prop) # 随机选择若干行选择 math 列值中前 5 大的行:
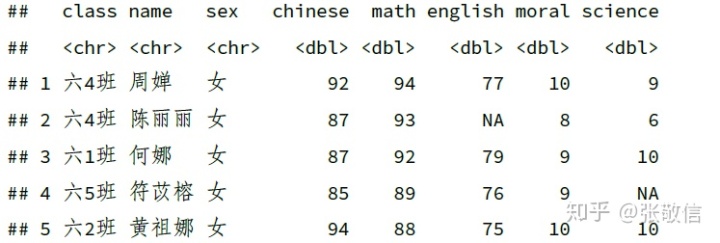
df %>%
slice_max(math, n = 5)
3. 用 filter() 根据值或条件筛选行
df_dup %>%
filter(sex == " 男", math > 80)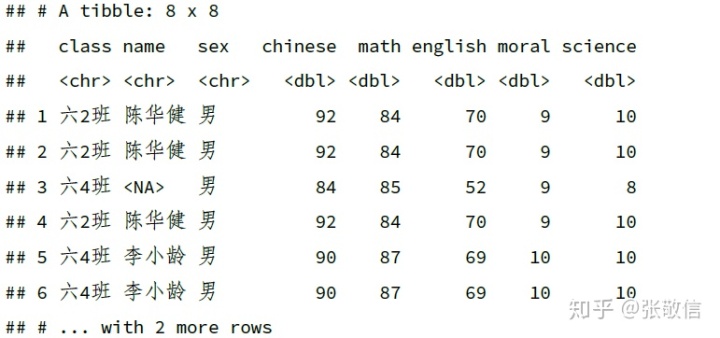
注:多个条件之间用“,” 隔开,相当于 and.
df_dup %>%
filter(sex == " 女", (is.na(english) | math > 80))
df_dup %>%
filter(between(math, 70, 80)) # 闭区间
4. 在限定列范围内根据条件筛选行
结合 across() 及选择列语法,可以在限定列范围内,根据应用函数得到的结果作为条件筛选行。
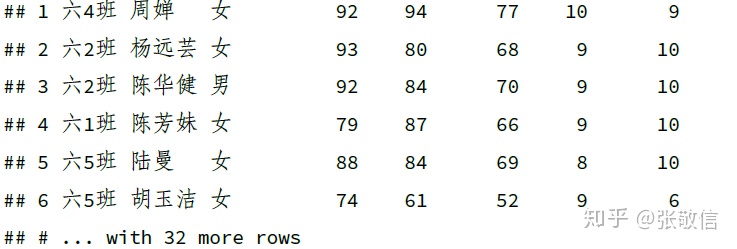
(1) 限定列范围内,筛选“所有值都满足某条件的行”
- 选出所有列范围内,所有值都
> 75的行:
df[, 4:6] %>%
filter(across(everything(), ~ .x > 75)) # 不能套all_var
注:across() 等价于 all_var()
- 选出所有列范围内,所有值都不是
NA的行
df_dup %>%
filter(across(everything(), ~ !is.na(.x)))
(2) 限定列范围内,筛选“存在值满足某条件的行”
在限定的列范围内,选择“存在值满足某条件的行",目前的支持还不好,暂时需要借助如下函数实现:
rowAny = function(x) rowSums(x, na.rm = TRUE) > 0选出所有列范围内,存在值包含“bl” 的行
starwars %>%
filter(rowAny(across(everything(), ~ str_detect(.x, "bl"))))
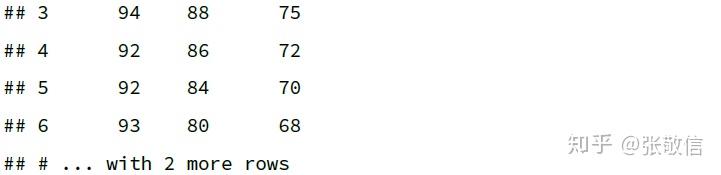
- 选出所有列范围内,存在值
> 90的行
df[, 4:6] %>%
filter(rowAny(across(everything(), ~ .x > 90)))

从字符列范围内,选择包含(存在)NA 的行:
df_dup %>%
filter(rowAny(across(where(is.character), any_vars(is.na(.)))))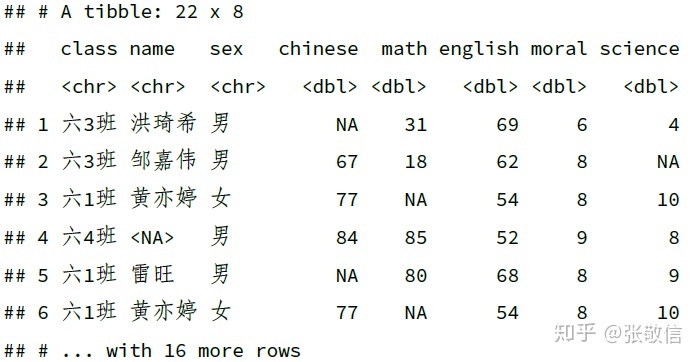
2.5.3 对行排序
用 dplyr 包中的 arrange() 对行排序,默认是递增。
df_dup %>%
arrange(math, sex)
若要递减排序,套一个 desc():
df_dup %>%
arrange(desc(math)) # 递减排序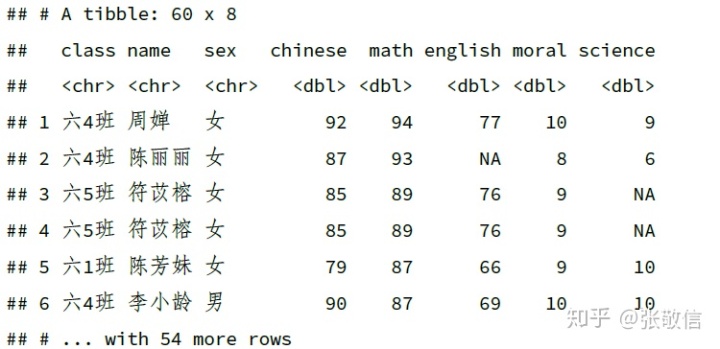
2.5.4 修改列
修改列,即修改数据框的列,计算新列。
1. 创建新列
用 dplyr 包中的 mutate() 创建或修改列,返回原数据框并增加新列;若改用transmute() 则只返回增加的新列。
若只给新列 1 个值,则循环使用得到值相同的一列:
df %>%
mutate(new_col = 5)
正常是以长度等于行数的向量赋值:
df %>%
mutate(new_col = 1:n())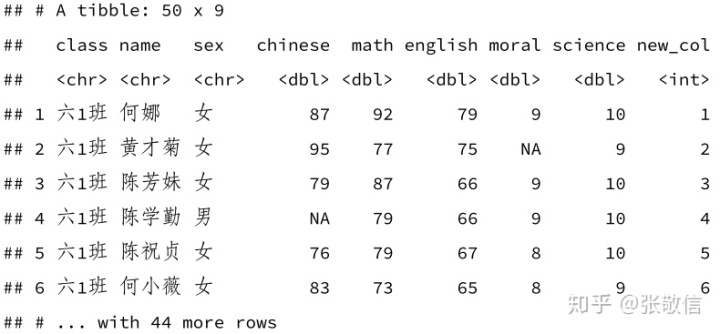
注: n() 返回当前分组的样本数, 未分组则为总行数。
2. 计算新列
用数据框的列计算新列,若修改当前列,只需要赋值给原列名。
df %>%
mutate(total = chinese + math + english + moral + science)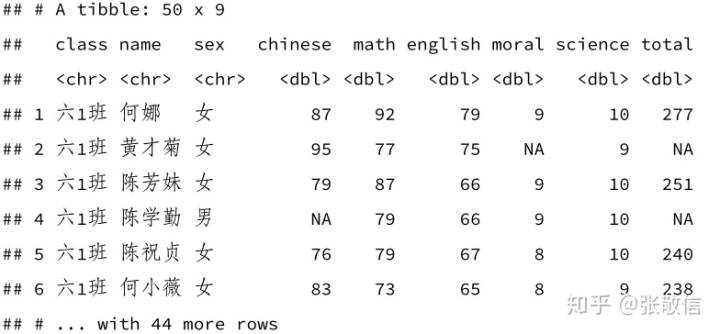
注意:不能用 sum(), 它会将整个列的内容都加起来,类似的还有 mean().
在同一个 mutate() 中可以同时创建或计算多个列,它们是从前往后依次计算,所以可以使用前面新创建的列,例如
- 计算
df中math列的中位数 - 创建标记
math是否大于中位数的逻辑值列 - 用
as.numeric()将TRUE/FALSE转化为1/0
df %>%
mutate(med = median(math, na.rm = TRUE),
label = math > med,
label = as.numeric(label))
3. 修改多列
结合 across() 和选择列语法可以应用函数到多列,从而实现同时修改多列。
(1) 应用函数到所有列
- 将所有列转化为字符型:
df %>%
mutate(across(everything(), as.character))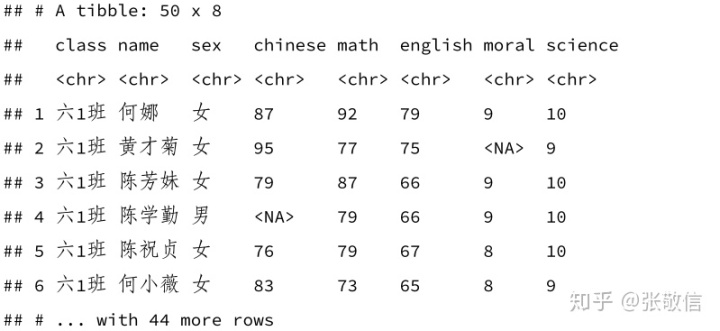
(2) 应用函数到满足条件的列
- 对所有数值列做归一化:
rescale = function(x) {
rng = range(x, na.rm = TRUE)
(x - rng[1]) / (rng[2] - rng[1])
}
df %>%
mutate(across(where(is.numeric), rescale))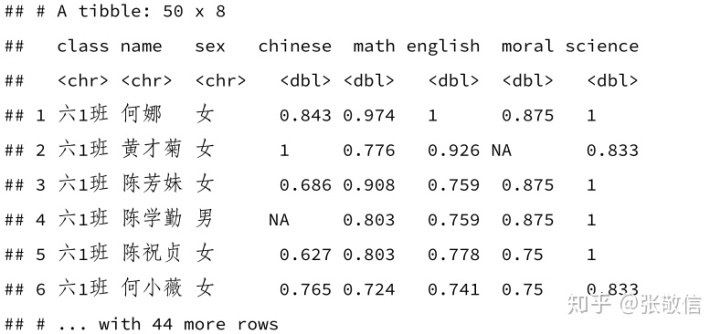
(3) 应用函数到指定的列
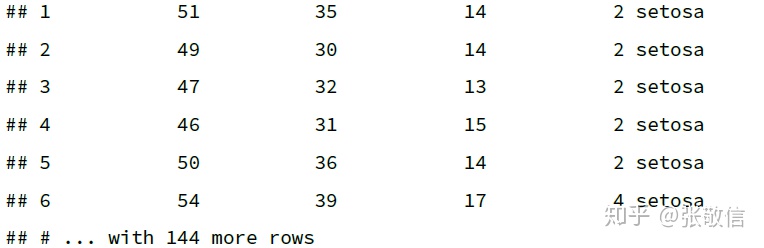
将 iris 中的 length 和 width 测量单位从厘米变成毫米:
as_tibble(iris) %>%
mutate(across(contains("Length") | contains("Width"), ~ .x * 10))
4. 替换 NA
(1) replace_na()
实现用某个值替换一列中的所有 NA 值,该函数接受一个命名列表,其成分为列名 = 替换值:
starwars %>%
replace_na(list(hair_color = "UNKNOWN", height = mean(.$height, na.rm = TRUE)))
(2) fill()
用前一个(或后一个)非缺失值填充 NA。有些表在记录时,会省略与上一条记录相同的内容,如下表:
load("datas/gap_data.rda")
knitr::kable(gap_data, align="c")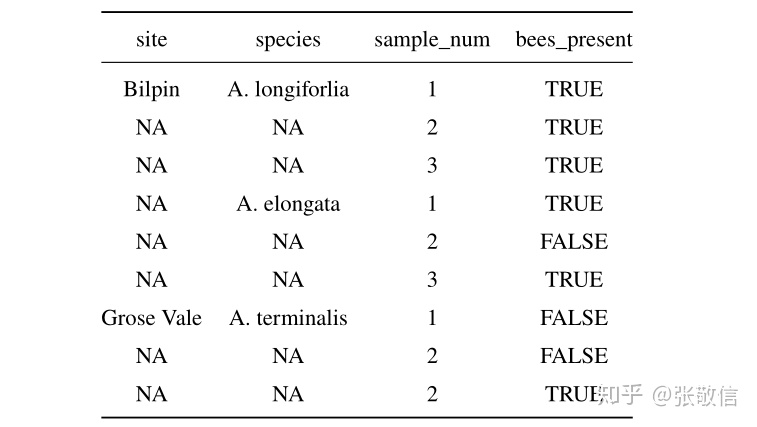
tidyr 包中的 fill() 适合处理这种结构的缺失值, 默认是向下填充,即用上一个非缺失值填充:
gap_data %>%
fill(site, species)
5. 重新编码
实际中,经常需要对列中的值进行重新编码。
(1) 两类别情形:if_else()
用 if_else() 作是/否决策以确定用哪个值做重新编码:
df %>%
mutate(sex = if_else(sex == " 男", "M", "F"))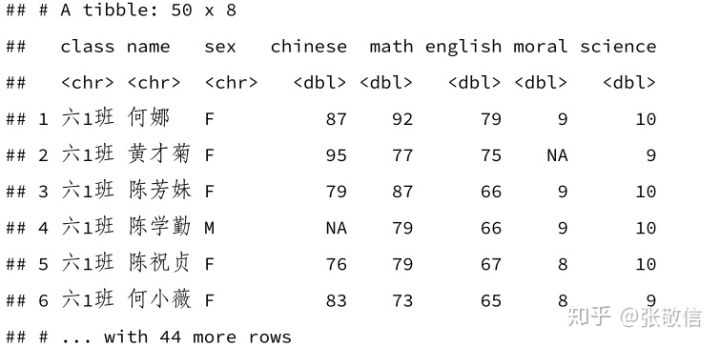
(2) 多类别情形:case_when()
用 case_when() 做更多条件下的重新编码,避免使用很多 if_else() 嵌套:
df %>%
mutate(math = case_when(math >= 75 ~ "High",
math >= 60 ~ "Middle",
TRUE ~ "Low"))
case_when() 中用的是公式形式,
- 左边是返回
TRUE或FALSE的表达式或函数 - 右边是若左边表达式为
TRUE,则重新编码的值,也可以是表达式或函数 - 每个分支条件将从上到下的计算,并接受第一个
TURE条件 - 最后一个分支直接用
TRUE表示若其它条件都不为TRUE时怎么做
(3) 更强大的重新编码函数
基于 tidyverse 设计哲学, sjmisc 包实现了对变量做数据变换,如重新编码、二分或分组变量、设置与替换缺失值等; sjmisc 包也支持标签化数据,这对操作 SPSS 或 Stata 数据集特别有用。

library(sjmisc)
df %>%
rec(math, rec = "min:59= 不及格 ; 60:74= 中 ; 75:85= 良 ; 85:max= 优 ",
append = FALSE) %>%
frq() # 频率表
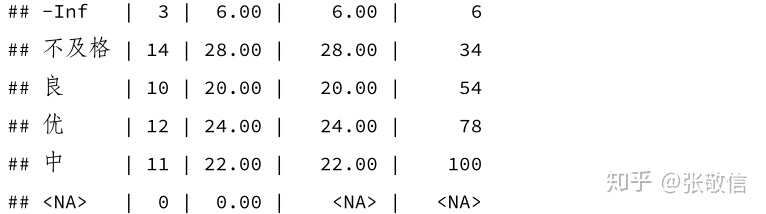
注: 新值的值标签可以在重新编码时一起设置,只需要在每个重编码对后接上中括号标签。
2.5.5 分组汇总
分组汇总,相当于 Excel 的透视表功能
对未分组的数据框,一些操作如 mutate() 是在所有行上执行 —--- 或者说,整个数据框是一个分组,所有行都属于它。
若数据框被分组,则这些操作是分别在每个分组上独立执行。可以认为是,将数据框拆分为更小的多个数据框。在每个更小的数据框上执行操作,最后再将结果合并回来。
1. 创建分组
用 group_by() 创建分组,只是对数据框增加了分组信息(用 group_keys() 查看),
并不是真的将数据分割为多个数据框。
df_grp = df %>%
group_by(sex)
group_keys(df_grp) # 分组键值 ( 唯一识别分组 )
group_indices(df_grp) # 查看每一行属于哪一分组
group_rows(df_grp) # 查看每一组包含哪些行
ungroup(df_grp) # 解除分组- 其它分组函数
真正将数据框分割为多个分组: group_split() , 返回列表,其每个成分是一个分组数据框
将数据框分组( group_by ),再做嵌套( nest ),生成嵌套数据框: group_nest()
iris %>%
group_nest(Species)

purrr风格的分组迭代:将函数.f依次应用到分组数据框.data的每个分组上
- group_map(.data, .f, ...) : 返回列表
- group_walk(.data, .f, ...) : 不返回,只关心副作用
- group_modify(.data, .f, ...) : 返回修改后的分组数据框
2. 分组汇总
对数据框做分组最主要的目的就是做分组汇总,汇总就是以某种方式组合行,用 dplyr 包中的 summarise() 函数实现,结果只保留分组列唯一值和新创建的汇总列。
(1) summarise()
可以与很多自带或自定义的汇总函数连用,常用的汇总函数有:
n(): 观测数n_distinct(var): 变量 var 的唯一值数目sum(var) , max(var) , min(var), . . .mean(var) , median(var) , sd(var) , IQR(var), .. .
df %>%
group_by(sex) %>%
summarise(n = n(),
math_avg = mean(math, na.rm = TRUE),
math_med = median(math))
函数 summarise() ,配合 across() 可以对所选择的列做汇总。好处是可以借助辅助选择器或判断条件选择多列,还能在这些列上执行多个函数,只需要将它们放入一个列表。
(2) 对某些列做汇总
df %>%
group_by(class, sex) %>%
summarise(across(contains("h"), mean, na.rm = TRUE))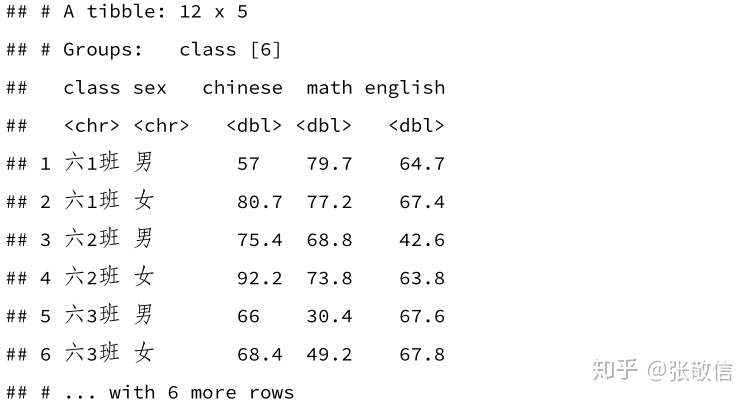
(3) 对所有列做汇总
df %>%
select(-name) %>%
group_by(class, sex) %>%
summarise(across(everything(), mean, na.rm = TRUE))
(4) 对满足条件的列做多种汇总
df_grp = df %>%
group_by(class) %>%
summarise(across(where(is.numeric),
list(sum = sum, mean = mean, min = min, na.rm = TRUE)))
df_grp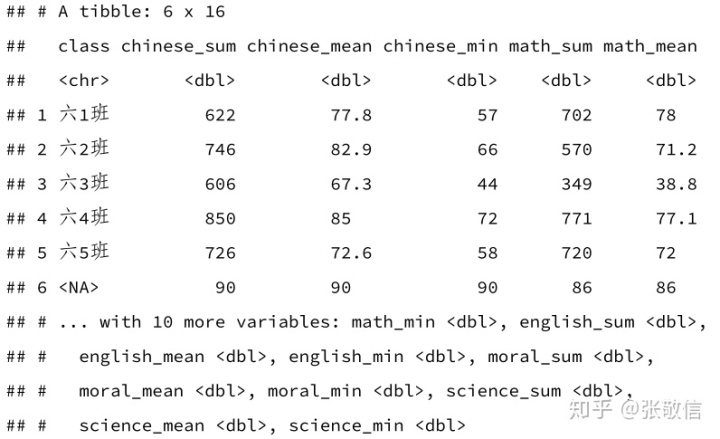
可读性不好,再来个宽变长:
df_grp %>%
pivot_longer(-class, names_to = c("Vars", ".value"), names_sep = "_")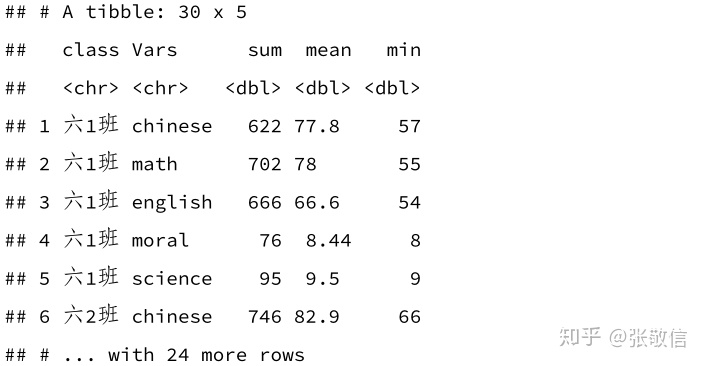
(5) 支持多返回值的汇总函数
summarise() 以前只支持一个返回值的汇总函数,如 sum, mean 等。现在也支持多返回值(返回向量值、甚至是数据框)的汇总函数,如 range(), quantile() 等。
qs = c(0.25, 0.5, 0.75)
df_q = df %>%
group_by(sex) %>%
summarise(math_qs = quantile(math, qs, na.rm = TRUE), q = qs)
df_q
可读性不好,再来个长变宽:
df_q %>%
pivot_wider(names_from = q, values_from = math_qs, names_prefix = "q_")
3. 分组计数
用 count() 按分类变量 class 和 sex 分组,并按分组大小排序:
df %>%
count(class, sex, sort = TRUE)
对已分组的数据框,用 tally() 计数:
df %>%
group_by(math_level = cut(math,
breaks = c(0, 60, 75, 80, 100),
right = FALSE)) %>%
tally()

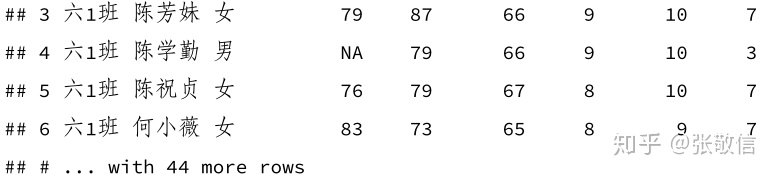
用 add_count() 和 add_tally() 可为数据集增加一列按分组变量分组的计数:
df %>%
add_count(class, sex)
本节部分内容参阅 (Hadley Wickham 2017), (Desi Quintans 2019), Vignettes of dplyr.
主要参考文献:
- Hadley Wickham. R for Data Science,2017.
- Desi Quintans, Jeff Powell. Working in the Tidyverse.http://www.hiercourse.com/
- Vignettes of dplyr package.
________________________________
版权声明:原创作品,版权所有,禁止用于一切出版。


















 1544
1544

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









