



一、DeepLearning4J框架简介
DeepLearning4J(DL4J)是一个Java编写的、基于深度学习算法的神经网络框架。它独立、分布式地运行于Hadoop和Spark之上,可以实现大规模数据的并行处理和分布式训练。
二、DeepLearning4J环境搭建
截至当前时间(2023.06.16),DL4J的最新版本为1.0.0-M2.1,本文目前也使用的是该版本。M2.1版本需要JDK11以上的运行环境,请确保电脑的JDK版本大于11。
由于DL4J的包较大,建议先把maven的源地址配置为国内的地址。
1.CPU部署
本方法适用于没有显卡或显卡不支持CUAD,如果电脑有显卡且以及安装好驱动和CUDA,可以使用GPU部署方式去部署。
<!--DL4J核心包-->
<dependency>
<groupId>org.deeplearning4j</groupId>
<artifactId>deeplearning4j-core</artifactId>
<version>1.0.0-M2.1</version>
</dependency>
<!--DL4J CPU计算包-->
<dependency>
<groupId>org.nd4j</groupId>
<artifactId>nd4j-native-platform</artifactId>
<version>1.0.0-M2.1</version>
</dependency>
<!--DL4J 模型库包-->
<dependency>
<groupId>org.deeplearning4j</groupId>
<artifactId>deeplearning4j-zoo</artifactId>
<version>1.0.0-M2.1</version>
</dependency>2.GPU部署
请根据电脑上的CUDA版本引入对应的包,我电脑上CUDA版本是11.6,所有下面引用的是nd4j-cuda-11.6-platform,具体支持哪些CUDA版本请查阅 : https://mvnrepository.com/
<!--DL4J核心包-->
<dependency>
<groupId>org.deeplearning4j</groupId>
<artifactId>deeplearning4j-core</artifactId>
<version>1.0.0-M2.1</version>
</dependency>
<!--DL4J GPU计算包-->
<dependency>
<groupId>org.nd4j</groupId>
<artifactId>nd4j-cuda-11.6-platform</artifactId>
<version>1.0.0-M2.1</version>
</dependency>
<!--DL4J 模型库包-->
<dependency>
<groupId>org.deeplearning4j</groupId>
<artifactId>deeplearning4j-zoo</artifactId>
<version>1.0.0-M2.1</version>
</dependency>三、模型训练和测试
1.数据集准备
1.1使用自定义数据集
如果想使用自己的数据去进行训练,需要下载标注工具。推荐使用lableimg工具进行标注。本文是基于TinyYOLO去实现人脸检测,所以一张完整的图片数据集应该是如下格式:
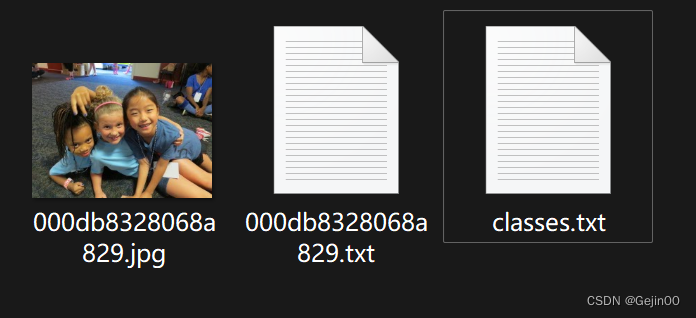
classe.txt是类别文件,因为本文中只进行人脸检测,所以类别文件中只有一行数据。内容如下:
Human face000db8328068a829.txt是标签文件,与图片文件名称相同。如图上图所示,图片中有3个人脸,所以标签文件内容如下:
0 0.267578125 0.5758854166666667 0.16125 0.2325
0 0.4457421875 0.4863545 0.148125 0.23583299999999996
0 0.6105859375 0.3789065833333334 0.17062500000000003 0.3如何使用lableimg工具生成yolo数据集可以自行百度。
1.2使用google开源的数据集
如果不想自己麻烦去标注上百张训练集的话,也可以下载开源的数据集。具体如何下载可以参考以下博文:
 https://blog.youkuaiyun.com/PhilharmyWang/article/details/121784119
https://blog.youkuaiyun.com/PhilharmyWang/article/details/1217841192.编写训练代码
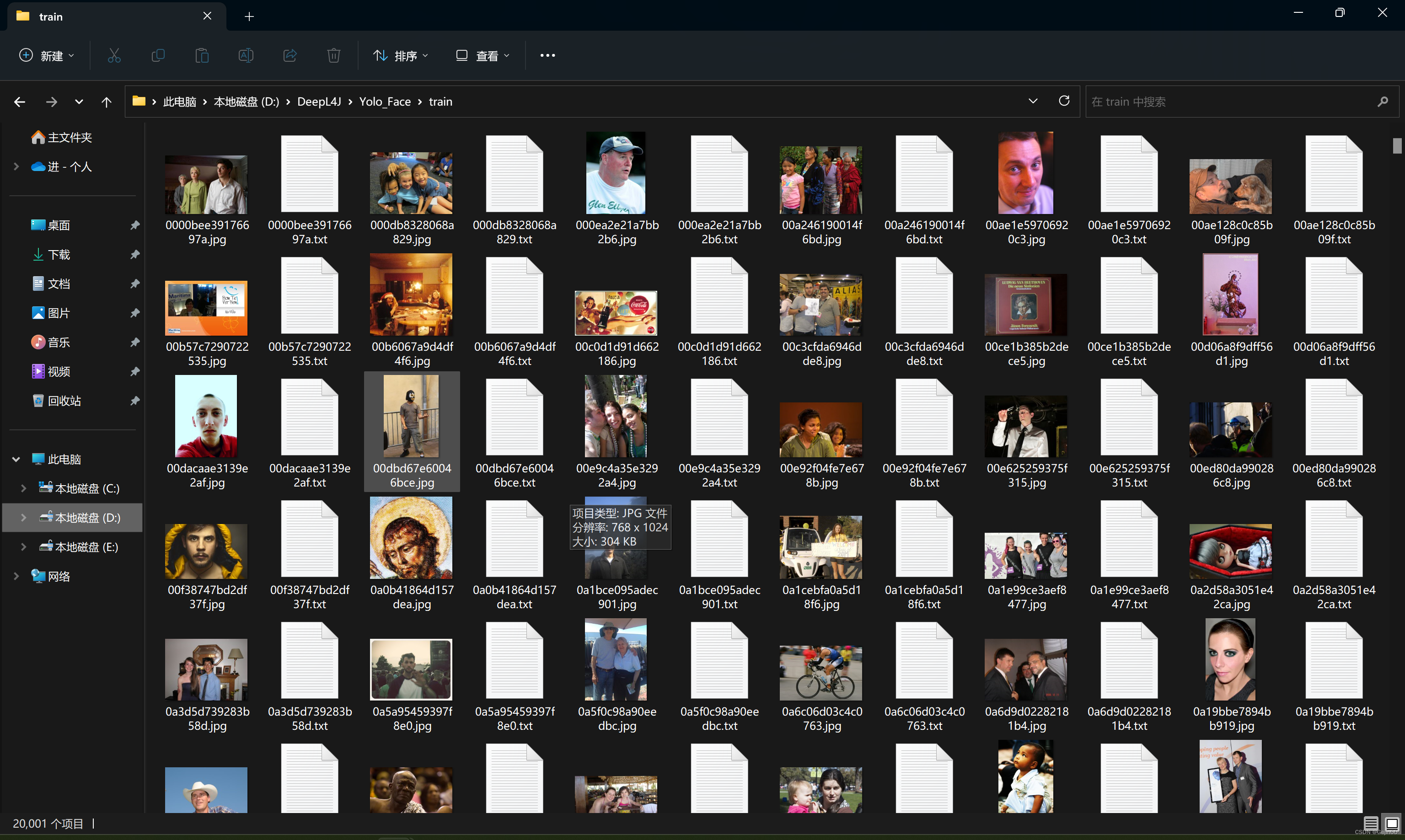
如果已经拥有数据集,就可以编写代码来训练我们的模型了,本文使用1万张图片作为训练集,训练集如下(1万张图片文件,1万个标签文件,1个classe.txt文件):
Java训练代码如下:
public static void main(String[] args) throws Exception {
//图像宽高和网格宽高
int width = 416, height = 416;
int gridWidth = 13, gridHeight = 13;
//图像通道和种类
int nChannels = 3, nClasses = 1;
//先验框
int nBoxes = 5;
double[][] priorBoxes = {{2, 2}, {2, 2}, {2, 2}, {2, 2}, {2, 2}};
//批量大小和训练轮次
int batchSize = 4, nEpochs = 10;
//训练文件的路径
String trainPath = "D:\\DeepL4J\\Yolo_Face\\train";
//模型的存储路径
String modelPath = "D:\\DeepL4J\\Yolo_Face\\mod\\model.dat";
//准备训练文件
File trainFile = new File(trainPath);
InputSplit[] data = new FileSplit(trainFile, NativeImageLoader.ALLOWED_FORMATS, new Random(123)).sample(null, 1.0, 0.0);
InputSplit trainData = data[0];
//训练数据
ObjectDetectionRecordReader recordReaderTrain = new ObjectDetectionRecordReader(height, width, nChannels, gridHeight, gridWidth, new YoloLabelProvider(trainFile.getAbsolutePath()));
recordReaderTrain.initialize(trainData);
//训练迭代器
RecordReaderDataSetIterator train = new RecordReaderDataSetIterator(recordReaderTrain, batchSize, 1, 1, true);
train.setPreProcessor(new ImagePreProcessingScaler(0, 1));
ComputationGraph model;
//如果模型存在则加载模型,不存在则加载模型并训练
if (new File(modelPath).exists()) {
System.out.println("Load model...");
model = ComputationGraph.load(new File(modelPath), true);
model.init();
} else {
System.out.println("Build model...");
//迁移学习
ComputationGraph pretrained = (ComputationGraph) TinyYOLO.builder().build().initPretrained();
INDArray priors = Nd4j.create(priorBoxes);
FineTuneConfiguration fineTuneConf = new FineTuneConfiguration.Builder()
.seed(123)
.optimizationAlgo(OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT)
.gradientNormalization(GradientNormalization.RenormalizeL2PerLayer)
.gradientNormalizationThreshold(1.0)
.updater(new Nesterovs.Builder().learningRate(1e-3).momentum(0.9).build())
.l2(0.00001)
.activation(Activation.IDENTITY)
.trainingWorkspaceMode(WorkspaceMode.SEPARATE)
.inferenceWorkspaceMode(WorkspaceMode.SEPARATE)
.build();
model = new TransferLearning.GraphBuilder(pretrained)
.fineTuneConfiguration(fineTuneConf)
.removeVertexKeepConnections("conv2d_9")
.removeVertexKeepConnections("outputs")
.addLayer("convolution2d_9",
new ConvolutionLayer.Builder(1, 1)
.nIn(1024)
.nOut(nBoxes * (5 + nClasses))
.stride(1, 1)
.convolutionMode(ConvolutionMode.Same)
.weightInit(WeightInit.XAVIER)
.activation(Activation.IDENTITY)
.build(),
"leaky_re_lu_8")
.addLayer("outputs",
new Yolo2OutputLayer.Builder()
.lambdaNoObj(0.5)
.lambdaCoord(5.0)
.boundingBoxPriors(priors)
.build(),
"convolution2d_9")
.setOutputs("outputs")
.build();
System.out.println("Train model...");
model.setListeners(new ScoreIterationListener(1));
for (int i = 0; i < nEpochs; i++) {
train.reset();
while (train.hasNext()){
model.fit(train.next());
}
//每一轮训练完都保存模型
ModelSerializer.writeModel(model, modelPath, true);
}
}
}上面代码中,依赖的YoloLabelProvider类的代码如下:
public class YoloLabelProvider implements ImageObjectLabelProvider {
private String baseDirectory;
private List<String> labels;
public YoloLabelProvider(String baseDirectory) {
this.baseDirectory = baseDirectory;
Assert.notNull(baseDirectory, "标签目录不能为空");
if (!new File(baseDirectory).exists()) {
throw new IllegalStateException(
"baseDirectory directory does not exist. txt files should be " + "present at Expected location: " + baseDirectory);
}
String classTxtPath = FilenameUtils.concat(this.baseDirectory, "classes.txt");
File classFile = new File(classTxtPath);
Assert.isTrue(classFile.exists(), "classTxtPath does not exist");
try {
labels = Files.readAllLines(classFile.toPath());
} catch (Exception e) {
throw new RuntimeException(e);
}
}
@Override
public List<ImageObject> getImageObjectsForPath(String path) {
int idx = path.lastIndexOf('/');
idx = Math.max(idx, path.lastIndexOf('\\'));
String filename = path.substring(idx + 1, path.length() - 4); //-4: ".png"
String txtPath = FilenameUtils.concat(this.baseDirectory, filename + ".txt");
String pngPath = FilenameUtils.concat(this.baseDirectory, filename + ".jpg");
File txtFile = new File(txtPath);
if (!txtFile.exists()) {
throw new IllegalStateException("Could not find TXT file for image " + path + "; expected at " + txtPath);
}
List<String> readAllLines = null;
BufferedImage image = null;
try {
image = ImageIO.read(Paths.get(pngPath).toFile());
readAllLines = Files.readAllLines(txtFile.toPath());
} catch (Exception e) {
throw new RuntimeException(e);
}
int width = image.getWidth();
int height = image.getHeight();
//去除空行
for (int i = 0; i < readAllLines.size(); i++) {
if (readAllLines.get(i).equals("")){
readAllLines.remove(i);
}
}
List<ImageObject> imageObjects = readAllLines.stream().map(line -> {
String[] data = line.split(" ");
int centerX = Math.round(Float.valueOf(data[1]) * width);
int centerY = Math.round(Float.valueOf(data[2]) * height);
int bboxWidth = Math.round(Float.valueOf(data[3]) * width);
int bboxHeight = Math.round(Float.valueOf(data[4]) * height);
int xmin = centerX - (bboxWidth / 2);
int ymin = centerY - (bboxHeight / 2);
int xmax = centerX + (bboxWidth / 2);
int ymax = centerY + (bboxHeight / 2);
ImageObject imageObject = new ImageObject(xmin, ymin, xmax, ymax, this.labels.get(Integer.valueOf(data[0])));
return imageObject;
}).collect(Collectors.toList());
return imageObjects;
}
@Override
public List<ImageObject> getImageObjectsForPath(URI uri) {
return getImageObjectsForPath(uri.toString());
}
}3.使用模型
3.1使用模型对图片进行预测
模型训练完毕后,可以参考训练代码中的Load model...部分去加载模型,然后可以使用如下代码对图片中的人脸目标进行预测:
//测试图片
File imageFile = new File("D:\\DeepL4J\\Yolo_Face\\test\\1358.jpg");
//读取图片
NativeImageLoader imageLoader = new NativeImageLoader(416, 416, 3);
INDArray indArray = imageLoader.asMatrix(imageFile);
//图片归一化
DataNormalization dataNormalization = new ImagePreProcessingScaler(0, 1);
dataNormalization.transform(indArray);
INDArray results = model.outputSingle(indArray);
org.deeplearning4j.nn.layers.objdetect.Yolo2OutputLayer yout = (org.deeplearning4j.nn.layers.objdetect.Yolo2OutputLayer) model.getOutputLayer(0);
List<DetectedObject> objs = yout.getPredictedObjects(results, 0.5);
for (int i = 0; i < objs.size(); i++) {
System.out.println("预测到第"+(i+1)+"个目标,左上角坐标:"+ objs.get(i).getTopLeftXY().toString() + ",右下角坐标:"+ objs.get(i).getBottomRightXY().toString());
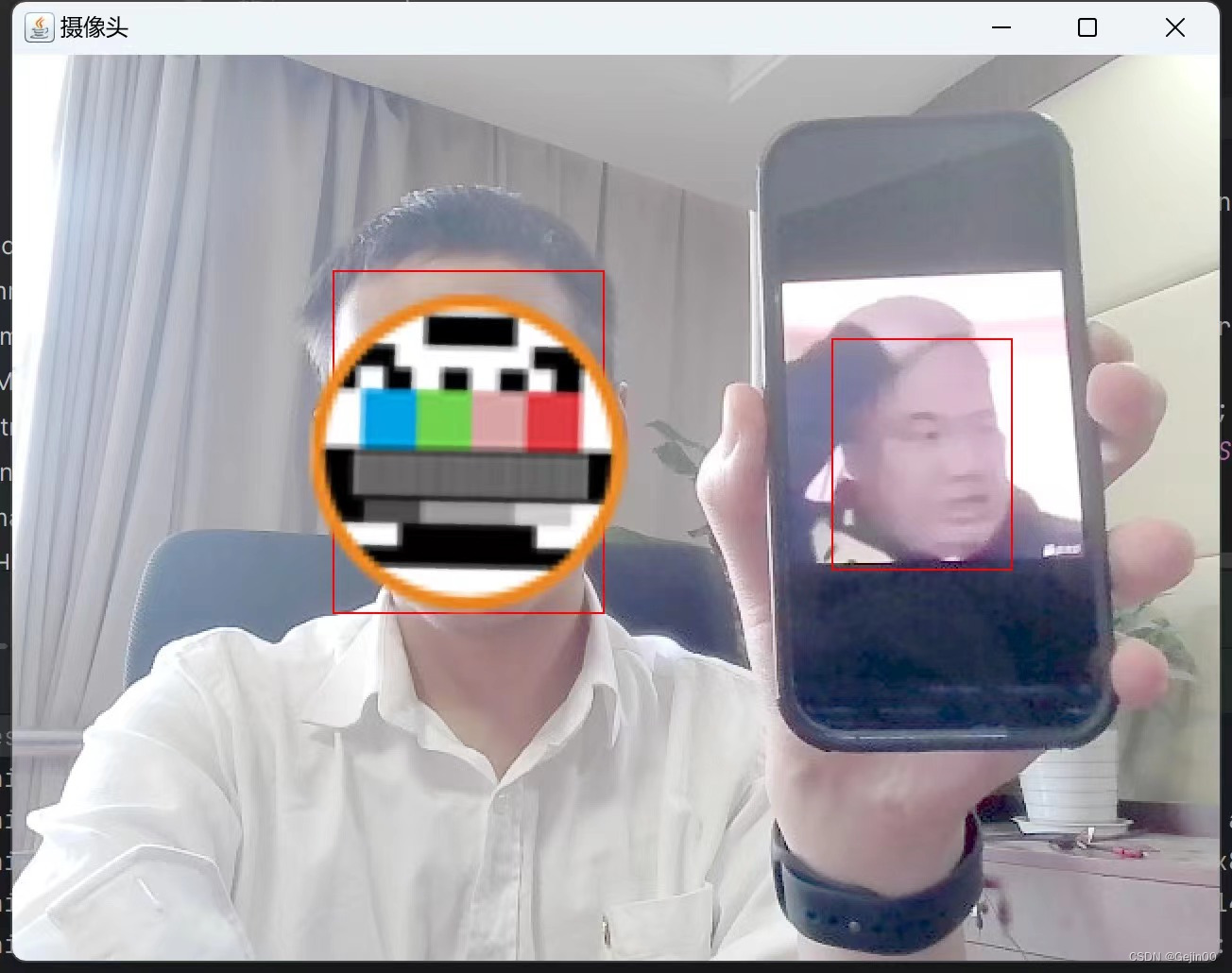
}3.2使用模型对电脑前置摄像头画面进行预测
使用模型对前置摄像头画面预测的代码和效果如下:
public static void main(String[] args) throws Exception {
//模型的存储路径
String modelPath = "D:\\DeepL4J\\Yolo_Face\\mod\\model.dat";
model = ComputationGraph.load(new File(modelPath), true);
model.init();
OpenCVFrameGrabber grabber = new OpenCVFrameGrabber(0);
grabber.start(); //开始获取摄像头数据
CanvasFrame canvas = new CanvasFrame("摄像头");//新建一个窗口
canvas.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
canvas.setAlwaysOnTop(true);
while (true) {
if (!canvas.isDisplayable()) {//窗口是否关闭
grabber.stop();//停止抓取
System.exit(2);//退出
}
OpenCVFrameConverter.ToIplImage converter = new OpenCVFrameConverter.ToIplImage();
Mat cameraMat = converter.convertToMat(grabber.grab());
NativeImageLoader imageLoader = new NativeImageLoader(416, 416, 3);
INDArray indArray = imageLoader.asMatrix(cameraMat);
DataNormalization dataNormalization = new ImagePreProcessingScaler(0, 1);
dataNormalization.transform(indArray);
INDArray results = model.outputSingle(indArray);
org.deeplearning4j.nn.layers.objdetect.Yolo2OutputLayer yout = (org.deeplearning4j.nn.layers.objdetect.Yolo2OutputLayer) model.getOutputLayer(0);
List<DetectedObject> objs = yout.getPredictedObjects(results, 0.3);
int w = cameraMat.cols();
int h = cameraMat.rows();
for (DetectedObject obj : objs) {
double[] xy1 = obj.getTopLeftXY();
double[] xy2 = obj.getBottomRightXY();
int x1 = (int) Math.round(w * xy1[0] / 13);
int y1 = (int) Math.round(h * xy1[1] / 13);
int x2 = (int) Math.round(w * xy2[0] / 13);
int y2 = (int) Math.round(h * xy2[1] / 13);
rectangle(cameraMat, new Point(x1, y1), new Point(x2, y2), Scalar.RED);
}
canvas.showImage(converter.convert(cameraMat));
}
} 
四、模型集成到SpringBoot中
运行效果如下:

代码已上传(其中的模型使用1万张图片训练100轮)。


















 2334
2334

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









