






 ELMo是一种基于深度双向语言模型的词表示方法,能够捕捉词义的多样性和上下文依赖性,有效解决一词多义问题。该模型通过预训练获得高质量的词向量,进而应用于各种自然语言处理任务,如问答系统、情感分析等。
ELMo是一种基于深度双向语言模型的词表示方法,能够捕捉词义的多样性和上下文依赖性,有效解决一词多义问题。该模型通过预训练获得高质量的词向量,进而应用于各种自然语言处理任务,如问答系统、情感分析等。
摘要
1 介绍
对很多自然语言模型而言,预训练词向量都是重要组成部分。但是学到高质量的词向量比较困难,理想的情况下,要学到词语的多样性特征(比如句法,语义),以及它们基于上下文语义的变化。本论文,我们将使用深度上下文词表示来解决这两个问题,并且可以轻松的集成到现有模型中,在大量有挑战性的语言理解任务上带来显著提升。
我们的词向量与传统词向量不同的点在于每个词的表示都是基于当前的整个句子。这些向量来自一个双向
2 相关研究
由于预训练词向量可以通过大量未标注的样本学习句法和语义信息,已经是
还有一些近期的研究旨在学到上下文表示,有通过双向
之前的研究同样表明了深度双向RNN不同层编码不同类型的信息。我们的研究表明混合不同层的信息对下游任务非常有用。
3 ELMo: 基于语言模型的嵌入
与常用的词嵌入不同,ELMO的词表示基于整个句子,并且使用双向语言模型(包含两层结构和字母级卷积)。可以使用半监督方式预训练。
3.1 双向语言模型
假定一个序列有
最近的语言模型都是使用非上下文的词向量
向后语言模型(backword LM)与向前语言模型类似,除了计算的时候倒置输入序列,用后面的上下文预测前面的词:
实现方式和前向LM类似,每个后向LSTM层
一个双向语言模型包含前向和后向语言模型,我们联合前向和后向的最大似然:
我们在前向和后向结合词表示
3.2 ELMo
ELMo基于任务来组合双向语言模型的中间层表示。对于各个词汇
其中
对于下游模型,ELMo将所有层的表示
其中,
下面进一步解释ELMo原理:
论文地址:https://arxiv.org/pdf/1802.05365.pdf
代码实现:https://github.com/allenai/allennlp
基于以下几个问题展开:
1、ELMO的结构是怎么样的?
2、ELMO到底在解决一个什么问题?
3、ELMO是怎么进行预训练的呢?如何使用它呢?
4、为什么ELMO用两个单向的LSTM代替一个双向的LSTM呢?
1、ELMO的结构是怎么样的?
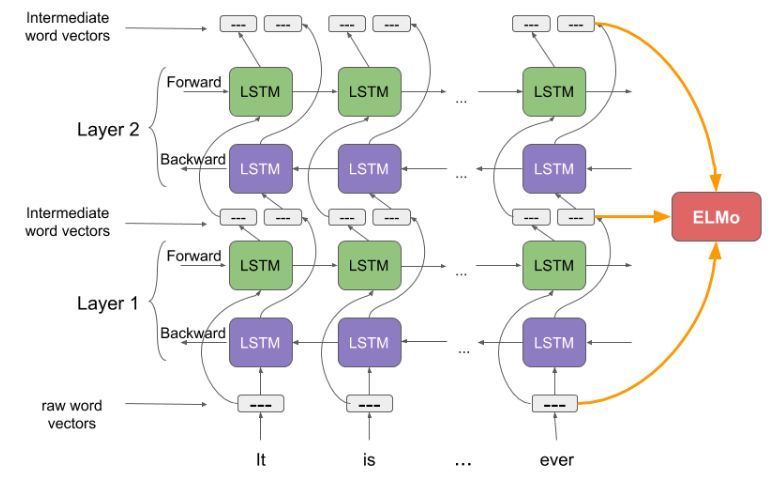
ELMO 由一层input层 和 两层双向LSTM 组合而成的
注:input层可看为embedding层,不过ELMO是通过字符卷积来得到embedding的,不是矩阵相乘;用两个单向LSTM替代一个双向LSTM。
如图:
2、ELMO到底在解决一个什么问题?
ELMO解决了大部分问题,其中最重要的一个是:它解决了一词多义的问题。
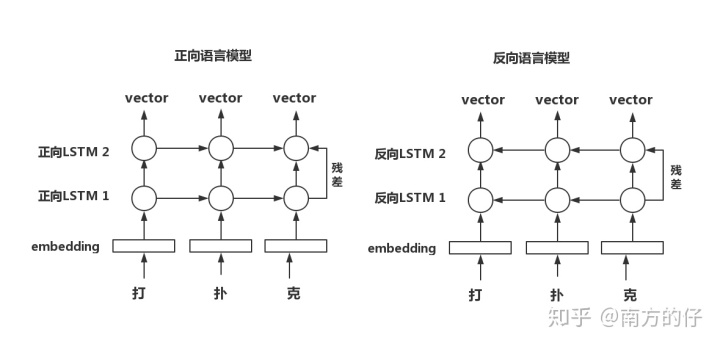
拿word2vector来说,字与vector是一一对应的,输入句子,然后输出句子中每个字对应vector,可以看成查表的过程。
如:输入 画画 ,word2vector就会输出两个一样的vector,但是第一个画是动词、第二个画是名词,他们的vector应该是不一样的,但word2vector并不能区分。即使在训练过程中对embedding矩阵进行更新,它依旧还是一一对应的关系。
向ELMO输入 画画 ,输出的两个向量是经过2层LSTM后的结果,它们是不同的。这是ELMO根据输入句子的语境得到的结果。
3、ELMO什么怎么进行预训练的呢?如何使用它呢?
论文这么说到:
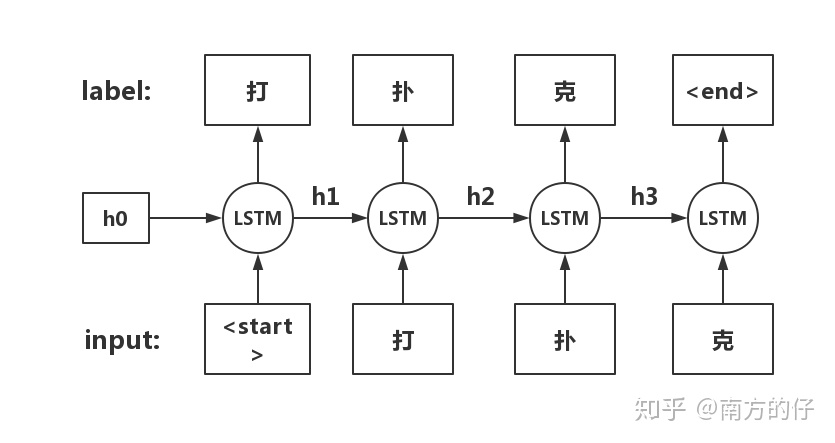
The top layer LSTM output, is used to predict the next token with a Softmax layer.
即,将ELMO输出的向量映射到 vocab_size的长度,softmax后,取出概率最大的元素对应的下标,作为对下一个字的预测。相当于做一个分类,类别数量是词表大小,类似自回归。
label相对于input错位一个字,如:
使用:
ELMO有三层,每一层都有一个输出,将这三层的输出按比例相加后即为所得vector。这个比例是模型学习得到的。得到加权后的向量后,如何使用取决于任务的效果。
4、为什么ELMO用两个单向的LSTM代替一个双向的LSTM呢?
这是关键!!!
用双向的模型结构去训练语言模型会导致“看到自己”或“看到答案”的问题。后来的预训练语言模型也都在避免或解决这个问题,解决的程度也影响着模型效果。
以下是几个模型的解决方法:
ELMO:使用两个单向LSTM代替一个双向LSTM
GPT :通过mask得分矩阵避免当前字看到之后所要预测的字,所以GPT是只有正向的,缺失了反向信息
BERT:将所要预测的字用[MASK]字符代替,无论你是正向的还是反向的,你都不知道[MASK]这个字符原来的字是什么,只有结合[MASK]左右两边的词语信息来预测。这就达到了用双向模型训练的目的,但也引入了 预训练-微调 不一致的问题
XLnet:不用[MASK]字符,结合GPT和BERT的思想,即:用mask得分矩阵的方法来替代[MASK]这个字符
可以看出,如果不考虑训练数据大小的影响,谁更好的解决“如何将双向融入语言模型”这个问题,谁效果就更好。
现在来说一下为什么双向LSTM会导致看见答案的问题:
如图所示的正向LSTM,"克"是根据“扑”这个字 和 隐藏向量h2 来预测出来的。h2包含了<start>和打 这两个字的信息,所以预测“克”这个字时,是根据前面所有的字来预测的。
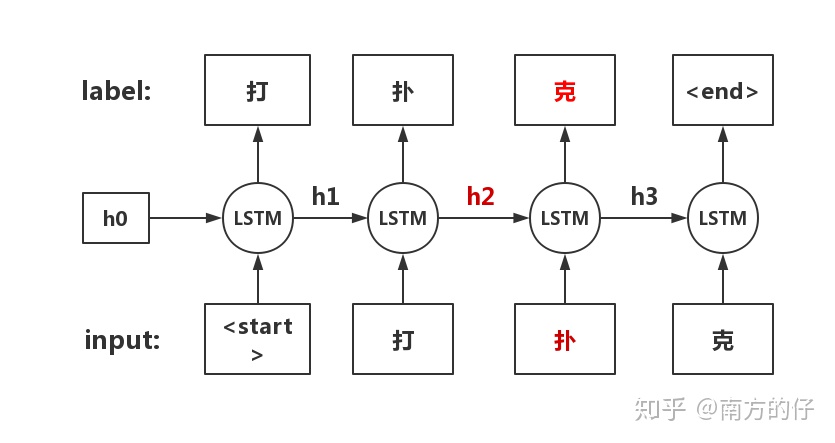
但如果加上反向LSTM呢?
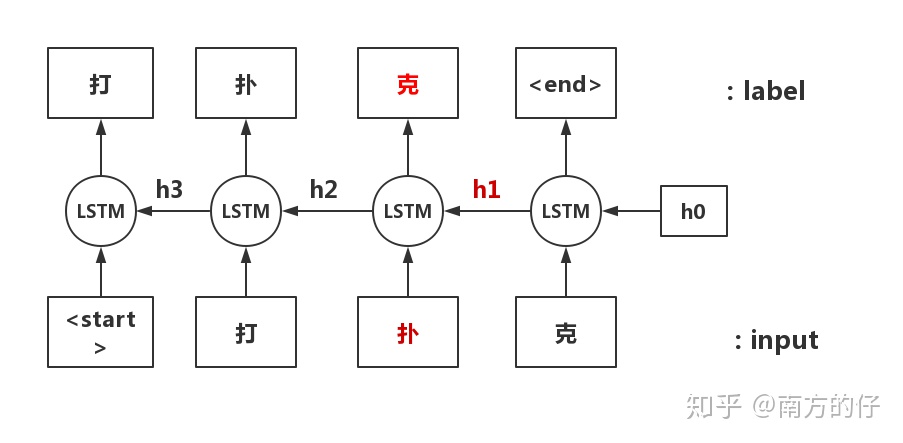
反向的话,“克”就是根据 “扑”和 h1 来预测的,但是 h1 包含了“克”的信息,所以反向的话会导致模型看到答案。
这就是双向LSTM带来的“看见答案”的问题。
Transformer 可以看成双向结构,通过它,句子间任何两个字的距离都是1,所以它是如何通过 mask 操作避免它看到下文信息的呢?这其中的原理又是什么呢?
参考:chon zhang:Bert前传(2)-ELMo
南方的仔:火热的语言模型:从被遗忘的ELMO出发

















 1045
1045

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









