






 本文介绍了利用机器学习解决Kaggle上的泰坦尼克号生存问题。通过预处理数据,如填充缺失值、特征转换,使用逻辑回归算法进行训练,最终得到约81%的预测准确率。
本文介绍了利用机器学习解决Kaggle上的泰坦尼克号生存问题。通过预处理数据,如填充缺失值、特征转换,使用逻辑回归算法进行训练,最终得到约81%的预测准确率。
拖更了好久,主要是小编最近沉迷ESP8266这个小家伙,做了点IOT的小玩意儿。言归正传,今天跟大家分享一下我对Kaggle上很经典的泰坦尼克号生存问题的实战操作。
今天讲的泰坦尼克号呢,没错,就是那个电影里肉丝儿、杰克在船头上演的经典一幕“you jump,俺也一样”的那艘船。今天我将带大家通过机器学习的方式来揭秘当时在船上的生存概率问题。
首先呢,做这么一个项目,数据很关键,本次应用所采用的数据是Kaggle网站上下载下来的,下载完之后我们可以得到一个train.csv和test.csv的数据文件。如下:
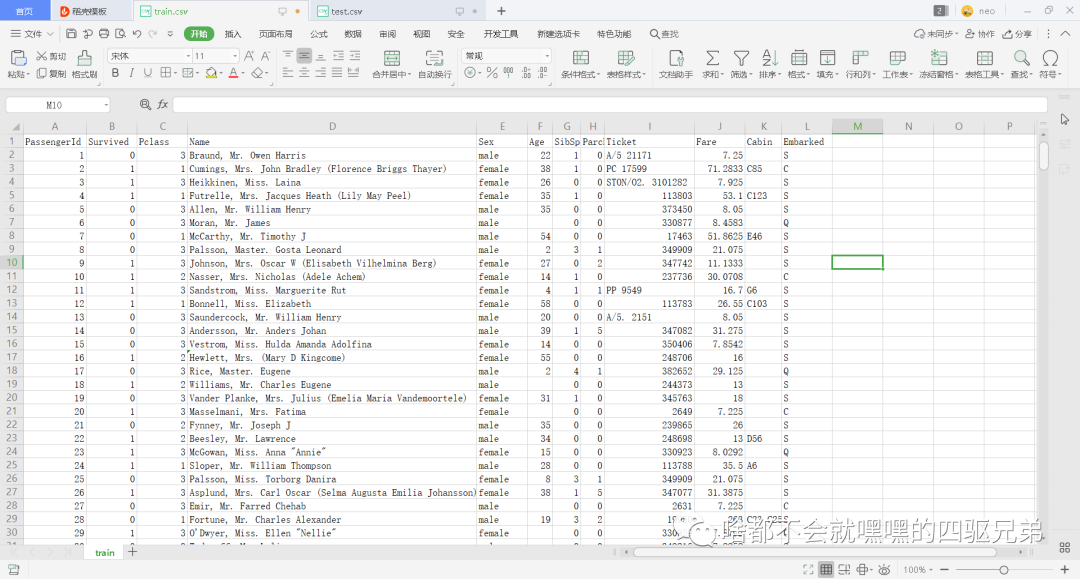
图1 train.csv部分截图
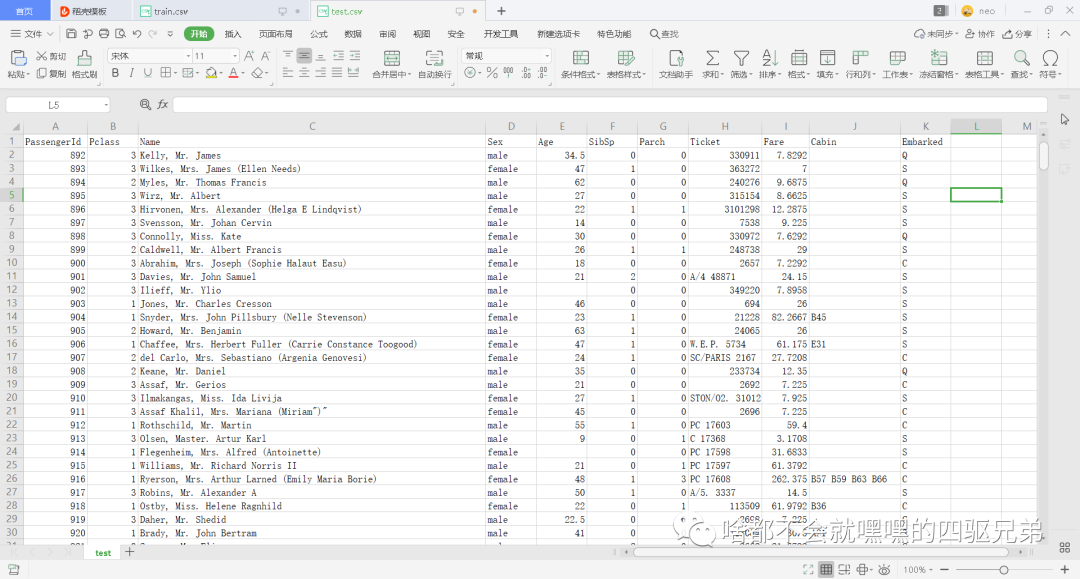
图2 test.csv部分截图
下面是对于第一行的一些属性解释,这些属性会或多或少地影响之后的分析,所以很重要。
PassengerId :乘客的ID号
Survived :生存的标号(0代表遇难,1代表幸存)
Pclass :船舱等级
Name :名字
Sex :性别
Age:年龄
SibSp :兄弟姐妹
Parch :父母和小孩
Ticket :票的编号
Fare:费用
Cabin:舱号
Embarked:登船口
知道了这些之后我们就可以在Jupter Notebook上开始慢慢写代码了。
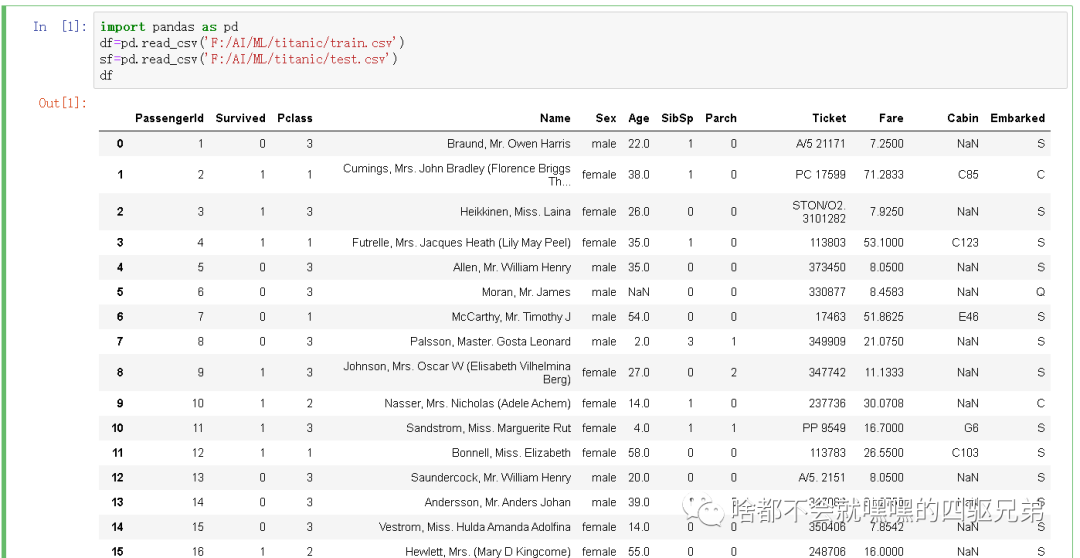
1.首先加载pandas数据包,同时加载本地的数据文件
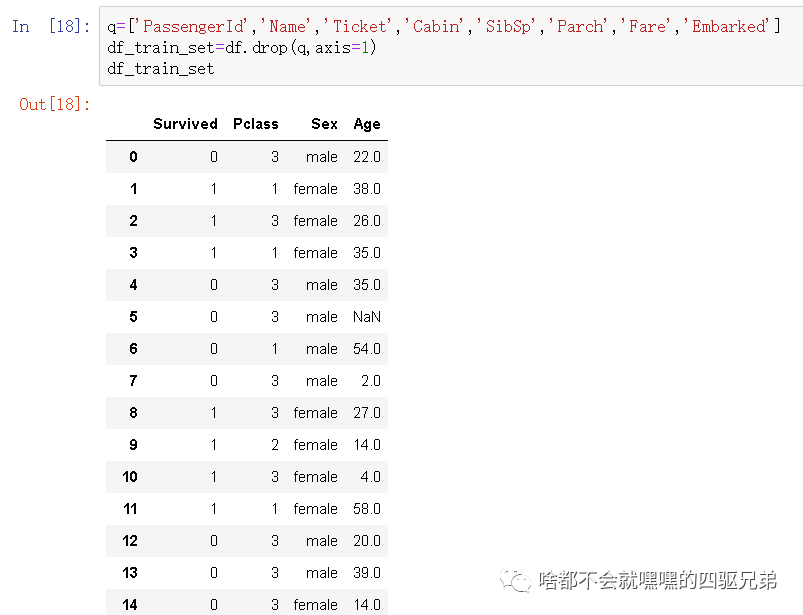
2.选择drop函数来去除几个我不想要的数据

3.对数据进行预处理,方便之后的计算

大家可以从之前的数据上发现年龄这一列有很多地方是NaN,缺少部分数据,那么这里通过取mean函数取均值并用fillna函数进行填充。

这一段代码是数据预处理的第二步,将一些机器学习无法识别的属性进行转换并做归一化处理,简单来说就是把机器看不懂的玩意儿换种说法告诉它(这里对旅客的性别进行了这样的操作,因为电脑是无法识别男性还是女性的,只能、读懂0,1这样的数字)。

之后就是对数据进行切片定位,iloc函数的后面先行后列,单一个冒号默认所有行,列指的是从哪两列之间进行切片操作。

train_test_split是划分数据集的一个函数,test_size代表代表测试数据集占总数据集的比例,random_state函数是用来控制随机状态的,如果没有规定这个数,那么同样的算法模型在不同的训练集和测试集上的效果将完全不一样。做这些的目的就是为了交叉验证。
交叉验证就是从原始数据集中抽取一部分作为测试集来评估模型,一部分作为训练集来训练模型。这么做的其目的就是为了让整个模型变得稳定可靠(鲁棒性强)。减少模型对新数据的应用时产生过拟合的概率,同时获取更多有用信息。
4.使用逻辑回归算法来训练模型并得出结论

最后发现我们的准确率大概在81%左右,这个结果不算最好,我只是用了个人理解的部分属性来进行测试,通过这样的方式说明逻辑回归的方法还是可行的。最有几个数据我想再介绍一下:
precision:精度=正确预测的个数(TP)/被预测正确的个数(TP+FP)(模型预测的结果中有多少是预测正确的)
recall:召回率=正确预测的个数(TP)/预测个数(TP+FN)(某个类别测试集中的总量,有多少样本预测正确了)
f1-score= 2*精度*召回率/(精度+召回率)(是统计学中用来衡量二分类模型精确度的一种指标。它同时兼顾了分类模型的精确率和召回率。f1-score是模型准确率和召回率的一种调和平均值,其范围在0到1之间)
support:当前类别在测试数据中的样本总量
avg/total:平均值和总数
那么今天的介绍就到这结束了,如果大家还对别的感兴趣可以自行到Kaggle官网浏览自己感兴趣的内容,也可以私信我沟通交流,886

















 1611
1611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









