





 本文通过Python2和Python3的实验,详细解释了编码和解码的概念,以及Bytes和Unicode类型的区别。在Python2中,未声明编码的代码默认以ASCII加载,可能导致非ASCII字符的解码错误。通过`#coding: utf-8`声明可以解决这个问题。而在Python3中,代码默认以Unicode加载,打印机制直接显示对应字符。文中通过实例展示了编码、解码的过程,并探讨了不同类型字符在内存中的表示形式。
本文通过Python2和Python3的实验,详细解释了编码和解码的概念,以及Bytes和Unicode类型的区别。在Python2中,未声明编码的代码默认以ASCII加载,可能导致非ASCII字符的解码错误。通过`#coding: utf-8`声明可以解决这个问题。而在Python3中,代码默认以Unicode加载,打印机制直接显示对应字符。文中通过实例展示了编码、解码的过程,并探讨了不同类型字符在内存中的表示形式。
以Python2和Python3为例:

在说编码、解码的概念之前,我们先说一下,写代码和执行代码的区别.
以Python2实验
1. 写代码
如果我说,我们写的代码首先是以二进制01的形式存储在硬盘中的,你可能会认为我说的就是废话,不管是何种形式的编码规则(ASCII编码、GB2312编码、GBK编码、FB18030编码、UTF-8编码)对字符进行编码,最后在计算机硬盘中存放的形式都是01形式,关键是以什么样的方式(编码)变成二进制,如果你真的这样想,那么你是对的,哈哈.(注:后面都用十六进制来表示在硬盘和内存中的存放形式,这样比较容易观察.)
如果你用Pychram软件编写的Python代码,默认是以UTF-8编码形成的01形式存放在硬盘中,VS code亦是如此,如图2所示:

2. 运行代码
那运行代码又是怎么回事呢?

前面我们说过,在用Pychram软件写Python代码是以UTF-8编码形成的01形式存储在硬盘,如果用Python2运行代码,就会将代码转换成ASCII码加载进内存,如果用Python3运行代码,就会将代码转换成Unicode的形式加载进内存.
我们利用python2来写一个实验:
a = 'hello'
print a输出结果:hello

通过Pychram运行代码没有任何问题,那么,这段代码从写到运行结束之后,到底发生了一个怎样的过程呢?

分析:如图5所示,"hello"字符串先以UTF-8码存储在硬盘中(这个编码规则是取决于编写代码的软件,这里用的是Pycharm),然后UTF-8码转换为ASCII码加载进内存(各种编码只要有对方的字符,都有一个转换公式,这个不要太过纠结,还有一点说明,UTF-8码是向下兼容ASCII码).
可能有人要问了,你怎么通过这个例子就能证明是转换成ASCII码加载进内存的呢?说的很好,确实不能证明,仔细观看图5就会发现,加载进内存中的编码与硬盘中的编码都是x68x656c6f,在内存中也完全有可能是UTF-8码,根本就没有发生变化.
既然如此,我们换个打印对象,换成'你好'这个字符串.
实验:
a = '你好'
print a输出结果出错(SytaxError: Non-ASCII character 'xe4' in file...)
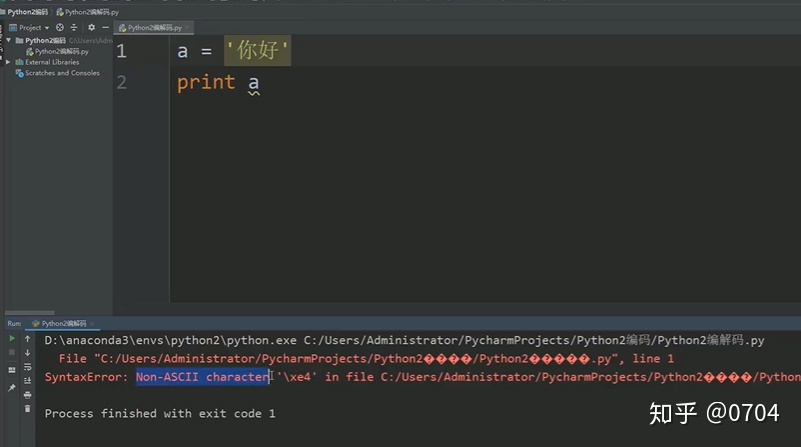
查错时,你就会发现:没有 ascii码:"xe4"
那么这个代码从写到运行结束又经历了一个怎样的历程呢?

分析:首先,代码以UTF-8码存储在硬盘中,'你好'这个字符串每个字由3个字节表示,共由6个字节表示,点击代码运行按钮,代码由UTF-8码转换成ASCII码加载进内存时,发现'xe4'(十六进制),超过ASCII码的范围,所以报错. (ASCII码范围是0~127,转换为十六进制:0~7F,xe4明显大于7F,不能进行编码转换.)
那么问题来了,难道Python2就不能打印中文吗?
我们再进行实验,如图7所示:
代码如下:
#coding : utf-8
a = '你好'
print a 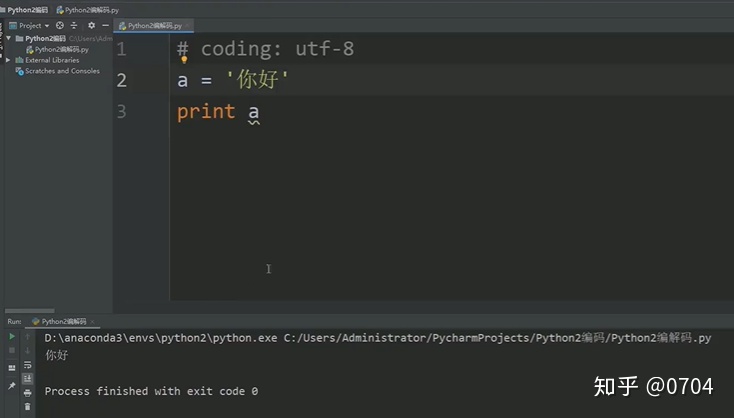
现在又能正常打印中文了,发生了什么?
首先观察代码,就会发现,本实验就比上个实验多了一行代码:#coding : utf-8
这行代码的意思就是:声明此文本代码的编码规则为utf-8 (加载进内存的编码规则)
可能有人听到这,还是有点懵...
我们再来观察本实验代码从写到运行结束的过程,如图8所示:
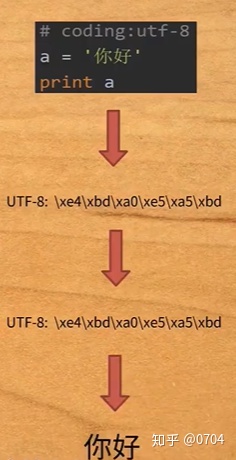
首先代码以UTF-8码存放在硬盘,然后加载进内存,注意此时是转换成UTF-8码加载进内存的,因为我们在写代码时声明:#coding:utf-8 (UTF-8 与utf-8是一样的,不要纠结大小写)
可能有人问了,UTF-8表示一个汉字是三个字节,我想用GB2312编码行不?
话不多说,实验是检测真理的唯一标准.
#coding: gb2312
a = '你好'
print a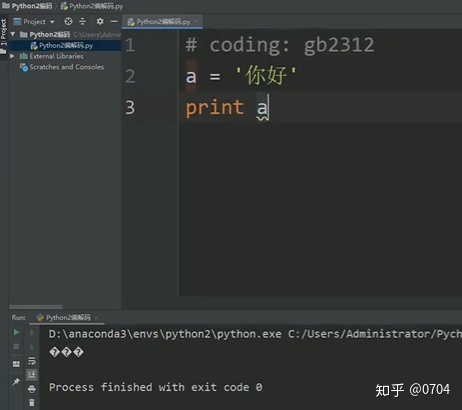
what,发生了什么,怎么会这样子?
虽然没有报错,但打出来的是啥东东,打印了三个 ?...
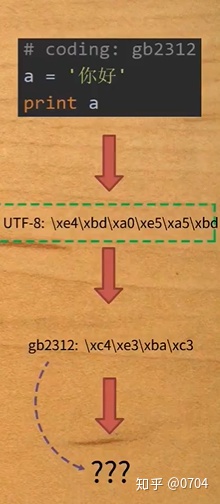
猜想:这可能跟Python2的print机制有关,Python2诞生的年份比较早,那时候没有完全考虑到中文,没有编码声明,就会将print后面的内容当作ASCII码显示对应的字符,如果有编码声明,且编码声明是UTF-8,也会显示相应的字符,但如果编码是GB2312或GBK,那就不会显示相应的字符. (注:猜想不一定正确哦,借鉴即可)
到了这里,我们需要引申一个概念:Bytes类型
3. Bytes类型
什么是Bytes类型?
前面我们知道,默认存放在硬盘的是UTF-8编码,而加载进内存时,可以是各种编码(ASCII码、UTF-8码、GB2312码 等等),无论它是以何种编码加载进内存的,加载进内存的内容肯定是一种编码. 我们称以某种编码加载进内存的数据类型为:Bytes类型.
Python2当中,并不叫Bytes类型,而是称为str类型.(大家不要纠结名称,我们知道它的本质其实是Bytes就行了)
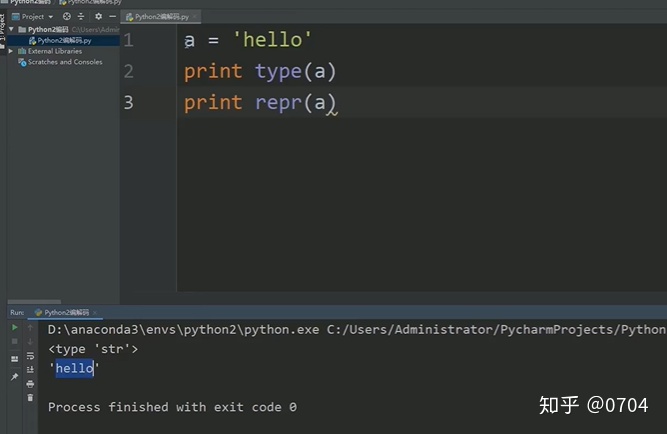
如图11,type():是python查看数据类型的内置函数,
repr(a):一种机制,可查看数据在内存中的码值,如果repr后面是ASCII码,默认把对应的字符显示出来.
为了更好观察,我们打印汉字(注:汉字的编码不在ASCII码中)
代码:
#coding: utf-8
a = '你好'
print type(a)
print repr(a)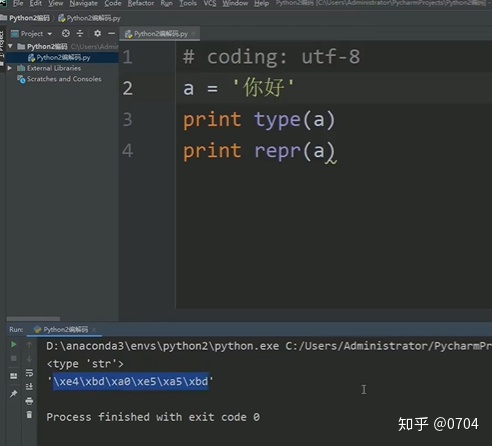
打印出来:'xe4'xbdxa0xe5xa5adb' (注:Bytes类型)
可能有人问了,加载进内存的都是Bytes类型吗?
继续往下读了,你就明白了...
4. Unicode类型
我们先来看一段代码,如图13所示:
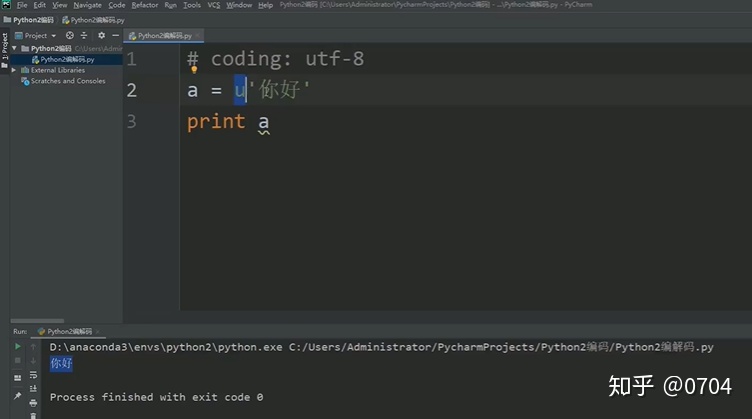
有人可能问,'你好'前面的u是什么意思?
u:告诉python2解释器运行这段代码时,要采用Unicode形式(UCS-2字符集:码位的二进制映射)把u后面的内容,加载进内存.
Python2也将这种数据类型称为Unicode.

现在我们知道了,加载进内存的代码有两种类型:① Bytes; ② Unicode
可能到这,有人又要问了,这两种类型有联系呢?

Unicode其实是一种对字符码位的二进制映射,不属于严格意义上的编码. (如果不理解,就去看上一篇文章或相关的链接视频). 一个理解为熟饭(Bytes),一个是生米(Unicode).
0704:字符集、编码zhuanlan.zhihu.com
其实很好理解:
生米 → 熟饭 : 编码
熟饭 → 生米 : 解码
注:编、解码不仅是属于Python2或Python3,而是适用于任何的编程语言,为通用概念.
说了这么多,我们来做一个实验.

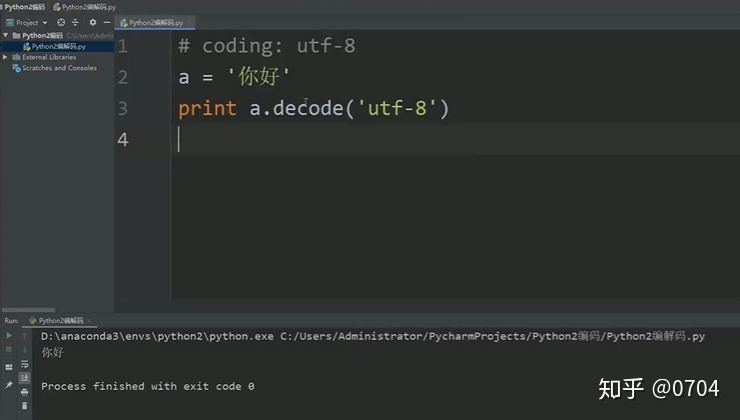
如图17:我们知道'hello'在内存中的默认形式是ASCII码(Bytes类型),我们对它进行解码,就可以看到它的类型在内存中变成了 Unicode类型.
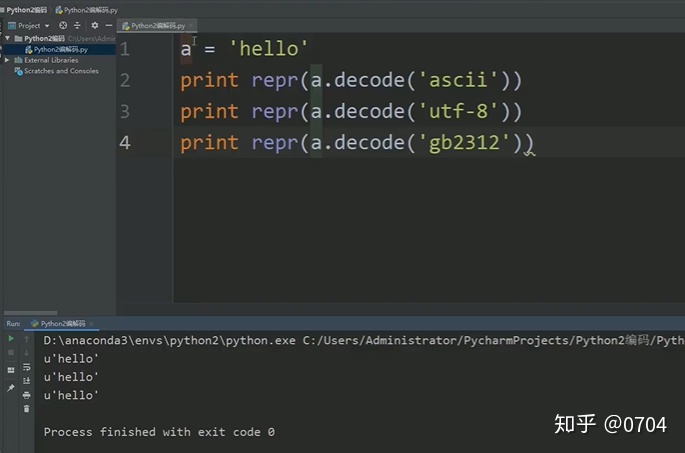
如图18所示:我们利用repr()函数,想查看'hello'的Unicode码(其实就是Unicode码位的二进制的映射),但结果好像不是值,而是字符.
这是咋回事呢?
其实前面我也说过了,这是Python2的显示机制,如果是英文,显示出的是对应Unicode码的字符.
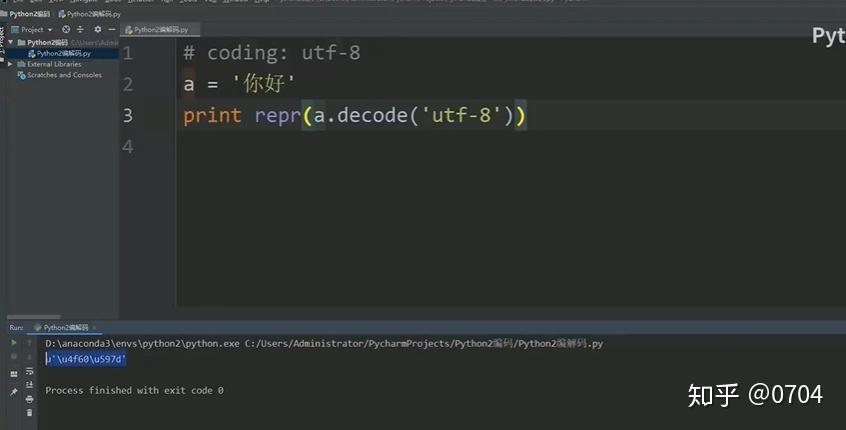
我们改用汉字实验一下:
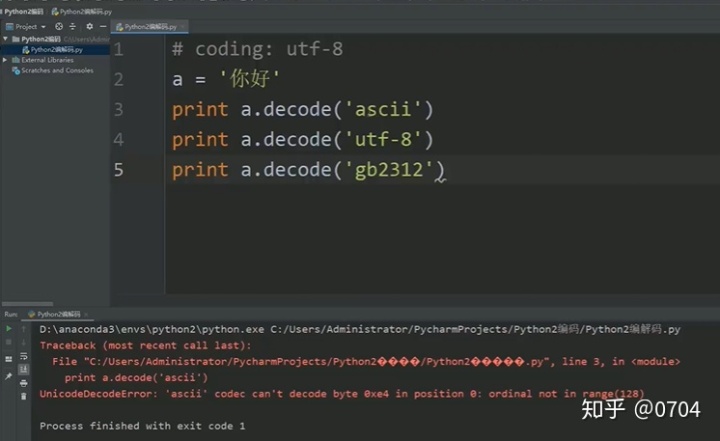
结果又出现问题,是不是有点崩溃,哈哈,我也是. (不过不要急,在解决问题过程中,你会学习到很多知识)
分析:首先看代码,'你好'以UTF-8码加载进内存(Bytes类型),现在想解码成Unicode类型,如果我用ASCII码进行解码,仔细一想,肯定会出现问题,'你好'的UTF-8码没有对应的ASCII码,而你用ASCII码去解码肯定会有问题的;如果用UTF-8码进行解码,当然是没有问题
所以我把 print a.decode('ascii')去掉,如图20所示:
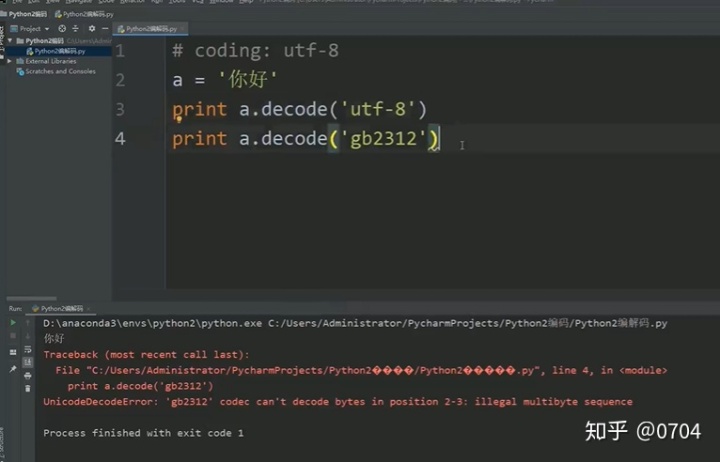
结果:print a.decode('gb2312') 这段代码出现问题.
分析:因为 UTF-8码的十六进制在GB2312字符集中无法找到相匹配的字符。

以Python3 实验:

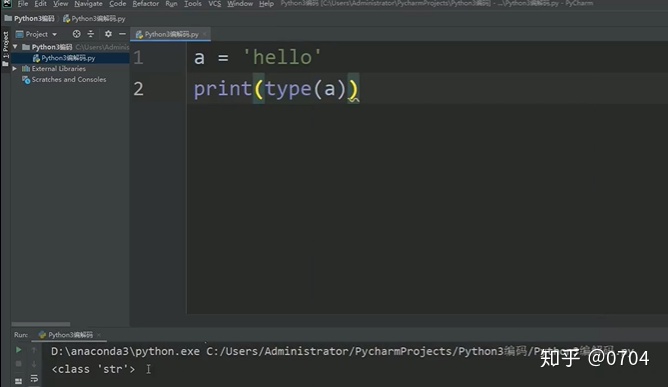
Python3 的print机制会将print后的Unicode码,显示出相对应的字符,而那些不是Unicode码,也会原封不动的显示出来.,如图23所示,第三个打印的是こんにちは(日语:你好)(注:Python3默认加载进内存的是Unicode类型)
Python3将这种Unicode类型称为:str类型(额,搞来搞去,也是有点醉)
其实大家知道它的本质是:以Unicode类型存放在内存中就行.
那么有人又想问了,既然有Unicode类型,是不是也应该有Bytes,确实这样.
我们可以定义一个Bytes类型,如图24所示:
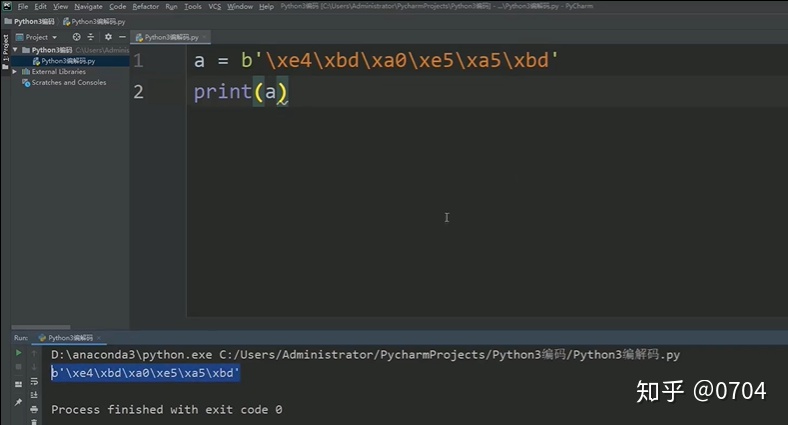
观察打印结果,发现原封不动的打印出来了.
这又是怎么回事呢?
其实我们刚才说过,Python打印时,如果是Unicode码(内存里存放的形式),会打印相对应的字符,如果不是Unicode码,会原封不动的显示出来. 图24所示的代码,加载进内存的是:Bytes类型,而非Unicode类型(对应的就是Unicode码),所以会原封不动的显示出来.
其实图24所示的代码发生了如下过程:

分析:b'xe4xbdxa0xe5xa5xbd'先以UTF-8的形式写进内存,这里注意:是引号里每个字符对应的UTF-8码(包括xe4...),Python解释器看到字符串前有个b,就会以某种编码转换成我们所理解的Bytes类型,而Python3的print只会对Unicode类型显示相应的字符,其它的原封不动显示出,所以最后呈现出的还是b'xe4xbdxa0xe5xa5xbd' .
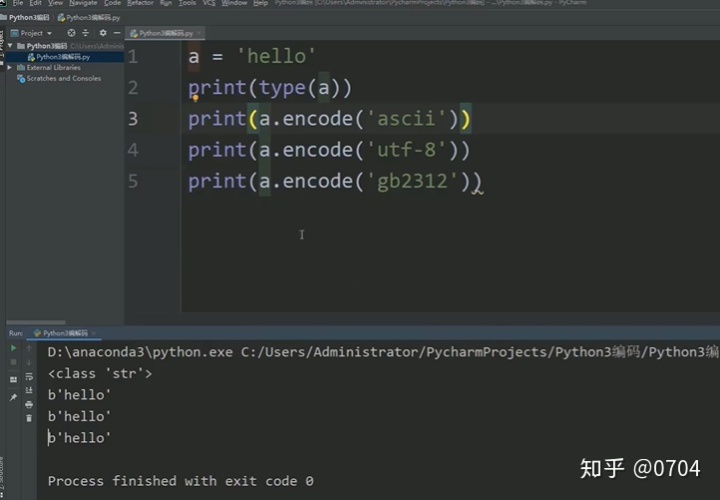
既然,Python3默认在内存中加载的是Unicode类(生米),那我们就可以进行编码,如图27所示:
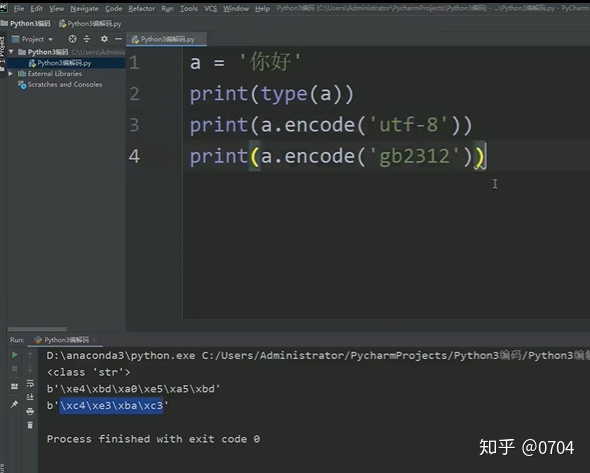
解码的过程与编码相反:
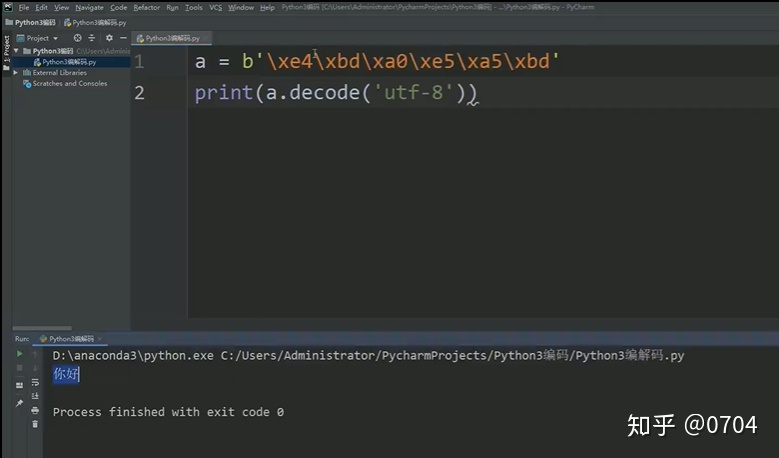
Bytes类(UTF-8码)加载进内存,因此采用UTF-8解码成Unicode类,Python3会显示对应的字符.
说到这里,差不多结束了,大家有没有感觉有点懵...


















 468
468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









