





 本文深入探讨Python爬虫中如何使用BeautifulSoup库的find()和find_all()方法来提取网页中p标签内的数据。通过实例介绍这两个方法的用法,帮助初学者掌握数据提取的关键技巧。
本文深入探讨Python爬虫中如何使用BeautifulSoup库的find()和find_all()方法来提取网页中p标签内的数据。通过实例介绍这两个方法的用法,帮助初学者掌握数据提取的关键技巧。

前言
在提取数据这一环节,爬虫程序会将我们所需要的数据提取出来。在上一篇文章《入门Python爬虫 -- 解析数据篇》中,我们已经了解过了解析数据的要点。而今天的内容,主要会在此基础上进一步提取出我们认为有价值的信息。

提取数据知识点
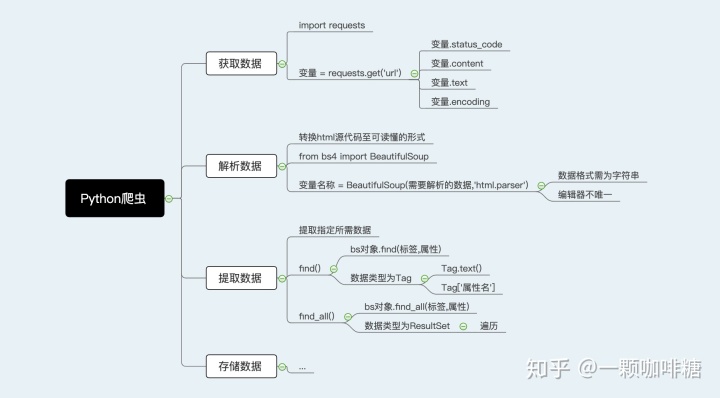
在提取数据的过程中,我们依旧会用到熟悉的BeautifulSoup库。下面我会介绍一下其中比较常用的两个方法:find()以及find_all()。

find():提取首个符合要求的数据。
用法:bs对象.find(标签,属性)
备注:此处的bs对象为解析过后的数据。标签和属性在这里用于定位指定HTML源代码所在的位置。让我们做一个简单的回顾:标签是被<>括住的内容,例:<head>,</head>。元素为一对标签中所涵盖的全部内容,例:<body>网页体内容</body>。属性则为定义了一个元素的内容,常见的属性有:href='https:www.example.com'(定义了一个链接);class="example"(定义了一个类);等等。
# 使用find()方法提取数据例子:
import requests
# 引入requests库
from bs4 import BeautifulSoup
# 引入bs库
res = requests.get('https:www.example.com')
# 获取https:www.example.com网页信息
print(res.status_code)
# 检查请求是否成功
string = res.text
# 将数据转换为字符串格式
soup = BeautifulSoup(string,'html.parser')
# 解析数据至可读懂格式
data = soup.find('div')
# 提取首个<div>元素,并命名变量为data
print(data)
find_all():提取所有符合要求的数据。
用法:bs对象.find_all(标签,属性)
备注:上述的bs对象、标签以及属性的用法与find()一致。不过,由find_all()提取出的数据类型会与find()不同。由find()方法提取出的数据类型一般为Tag,而find_all提取出的数据类型则为ResultSet。遇到类型为Tag的数据,我们可以通过Tag.text()的方式进一步提取其中纯文本格式的内容,以及Tag['属性名']的方式提取特定属性的值。而遇到类型为ResultSet的数据,我么则可以通过遍历的方式进一步提取出所有符合要求的数据。
# 使用find_all()方法提取数据例子:
import requests
# 引入requests库
from bs4 import BeautifulSoup
# 引入bs库
res = requests.get('https:www.example.com')
# 获取https:www.example.com网页信息
print(res.status_code)
# 检查请求是否成功
string = res.text
# 将数据转换为字符串格式
soup = BeautifulSoup(string,'html.parser')
# 解析数据至可读懂格式
data = soup.find_all('div')
# 提取所有<div>元素,并命名变量为data
for x in data:
content = x.find('p')
# 通过遍历的方式进一步提取<p>元素
print(content.text)
# 提取content中的纯文本内容总结

















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









