






 本文介绍如何使用Python实现QQ空间自动点赞功能。通过登录获取cookie,解析XML找到动态URL,提取可变参数,利用demjson处理非标准JSON数据,实现对空间动态的点赞。
本文介绍如何使用Python实现QQ空间自动点赞功能。通过登录获取cookie,解析XML找到动态URL,提取可变参数,利用demjson处理非标准JSON数据,实现对空间动态的点赞。
QQ空间自动点赞
- 前景提要目标确定分析介绍登陆获取cookie寻找XML寻找可变参数获取第一个空间动态寻找点赞所需的URL寻找可变参数功能提升到秒赞全部代码最后还是希望你们能给我点一波小小的关注。奉上自己诚挚的爱心
私信小编01即可获取大量Python学习资料
前景提要
因为我周围的小伙伴们天天跟我说的最多的一句话就是:空间第一条点赞。
所以说我还不如直接做一个自动点赞的代码呢,免得天天催我点赞。
目标确定
- QQ空间秒赞
分析介绍
登陆获取cookie
首先既然是对 QQ空间的一系列操作,自然是先解决登陆方面,在这篇文章里面我就不过多介绍了,因为我上几期之前对QQ空间已经做了一定的介绍了。直接放出链接就好。欢迎看博主以前的文章
def search_cookie(): qq_number = input('请输入qq号:') if not __import__('os').path.exists('cookie_dict.txt'): get_cookie_json(qq_number) with open('cookie_dict.txt', 'r') as f: cookie=json.load(f) return Truedef get_cookie_json(qq_number): password = __import__('getpass').getpass('请输入密码:') from selenium import webdriver from selenium.webdriver.chrome.options import Options login_url = 'https://i.qq.com/' chrome_options =Options() chrome_options.add_argument('--headless') driver = webdriver.Chrome(options=chrome_options) driver.get(login_url) driver.switch_to_frame('login_frame') driver.find_element_by_xpath('//*[@id="switcher_plogin"]').click() time.sleep(1) driver.find_element_by_xpath('//*[@id="u"]').send_keys(qq_number) driver.find_element_by_xpath('//*[@id="p"]').send_keys(password) time.sleep(1) driver.find_element_by_xpath('//*[@id="login_button"]').click() time.sleep(1) cookie_list = driver.get_cookies() cookie_dict = {} for cookie in cookie_list: if 'name' in cookie and 'value' in cookie: cookie_dict[cookie['name']] = cookie['value'] with open('cookie_dict.txt', 'w') as f: json.dump(cookie_dict, f) return Truedef get_g_tk(): p_skey = self.cookie['p_skey'] h = 5381 for i in p_skey: h += (h << 5) + ord(i) g_tk = h & 2147483647寻找XML
当我们拿到cookie信息和g_tk这个参数之后,继续去寻找空间好友动态的XML在何处。
首先点到XML位置一个个查找,发现有一个feeds3_html_more很像,点进去发现的确是我们要找的url链接。
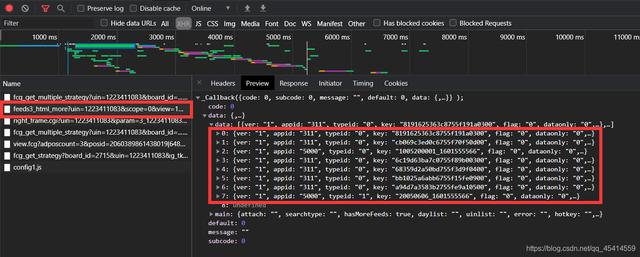
寻找可变参数
这个链接所需要的参数有很多,在这里列举出来
- uin:
- scope:
- view:
- daylist:
- uinlist:
- gid:
- flag:
- filter:
- applist:
- refresh:
- aisortEndTime:
- aisortOffset:
- getAisort:
- aisortBeginTime:
- pagenum:
- externparam:
- firstGetGroup:
- icServerTime:
- mixnocache:
- scene:
- begintime:
- count:
- dayspac:
- sidomain:
- useutf8:
- outputhtmlfeed:
- rd:
- usertime:
- windowId:
- g_tk:
- qzonetoken:
- g_tk:
这些参数中类似于可变参数的一共有五个。
- qzonetoken
- windowId
- rd
- usertime
- g_tk
- qzonetoken 参数在源码中是个可变的“定值”,因为每次刷新这个参数都会变,但是源码中却给出了他的具体值。直接获取即可。
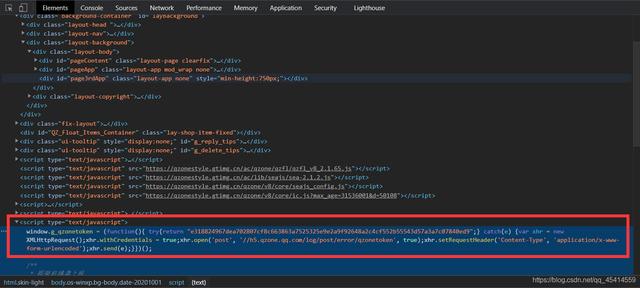
def get_space(): your_url = 'https://user.qzone.qq.com/' + str(qq_number) html = requests.get(your_url,headers=headers,cookies=cookie) if html.status_code == 200: qzonetoken = re.findall('window.g_qzonetoken =(.*?);',html.text,re.S)[1].split('"')[1] return True- windowId 与 rd 虽说每次刷新结果都不同,但是经过博主多次实验得出,这两个参数对整体并没有什么影响,可以直接抄下来。
'rd': '0.9311604844249088','windowId': '0.51158950324406',- usertime 参数看似很眼熟,是个时间戳参数,因为位数不对,说明应该是被放大了一千倍。
'usertime': str(round(time.time() * 1000)),- g_tk 参数上次教程已给出。在JavaScript中分析即可获得。
def get_g_tk(): p_skey = self.cookie['p_skey'] h = 5381 for i in p_skey: h += (h << 5) + ord(i) g_tk = h & 2147483647获取第一个空间动态
我们拿到XML以及各个参数后,即可访问该网页获取其返回值了。
但是这个返回与其他的有一些不同的是,它不仅仅是个json文件,我们无法获取后直接转换成字典格式去给我们使用,这就很麻烦。
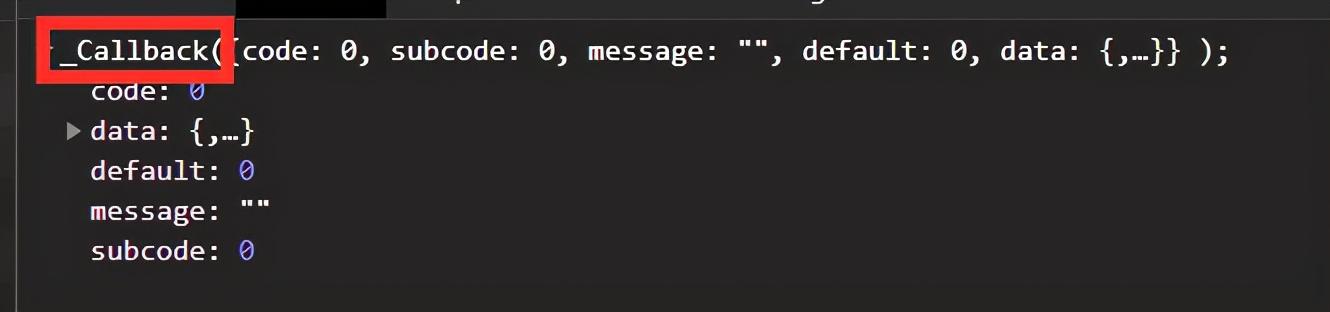
我们获取字符串后,首先先将前后不一致的都切片扔掉,之后经过一系列处理后发现,我们很难将这个看似像json格式的字符串转换成字典。
在这里我继续介绍一个第三方库demjson。
demjson 可以解決不正常的json格式数据
demjson的使用方法很简单。
encode将 Python 对象编码成 JSON 字符串decode将已编码的 JSON 字符串解码为 Python 对象
# 例子# -*- coding: utf-8 -*-import demjsonjs_json = "{x:1, y:2, z:3}"py_json1 = "{'x':1, 'y':2, 'z':3}"py_json2 = '{"x":1, "y":2, "z":3}'data = demjson.decode(js_json)print(data)# {'y': 2, 'x': 1, 'z': 3}data = demjson.decode(py_json1)print(data)# {'y': 2, 'x': 1, 'z': 3}data = demjson.decode(py_json2)print(data)# {'y': 2, 'x': 1, 'z': 3}我们使用demjson直接将该字符串转换为耳熟能详的字典格式,提取其中的data的data,即为前八条动态的每个参数,但我们这里只要第一个说说的动态信息。
text = html.text[10:-2].replace(" ", "").replace('','')json_list = demjson.decode(text)['data']['data']qq_spaces = json_list[0]我们拿到其信息后,先提取一些我们比较想知道的东西,比如名字、QQ号、发布时间、所获赞数、说说内容、说说地址等等结果。
在 qq_spaces 参数中我们发现里面有一个很长也很特殊的一个结果是 html 结果,这个结果里面很长,简单来看是个网页常规代码,应该是被JavaScript写入到网页中了,既然不是全部代码,那么只能用正则提取一下里面的具体我们需要的东西了。
content = str(qq_spaces['html'])try:zanshu = re.findall('(.*?)人觉得很赞
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









