






 本文介绍了一种基于CNN的骨骼行为识别方法,通过巧妙设计实现全局特征提取,并有效处理多人参与的行为识别问题。
本文介绍了一种基于CNN的骨骼行为识别方法,通过巧妙设计实现全局特征提取,并有效处理多人参与的行为识别问题。
Co-occurrence Feature Learning from Skeleton Data for Action Recognition and
Detection with Hierarchical Aggregation
论文链接:https://arxiv.org/abs/1804.06055
代码链接:huguyuehuhu/HCN-pytorch
最近看了一些论文,大多是关于GCN和RNNs的,关于CNN的论文大多质量不高,很少看一篇像这篇论文这么好的了,所以写个总结纪念一下。
这篇论文其实有很多东西值的学习,他的主要框架就是下图,但是很多细节并没有在这张图上展示出来。主框架图看着很简单,其实有很多巧妙的设计。
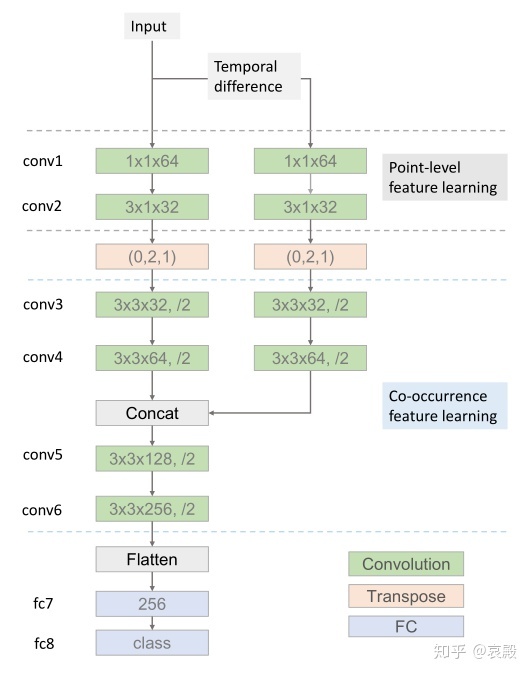
首先,这是一篇基于CNN的骨骼行为识别。最开始我也有这样的疑问,骨骼数据又不是图像,为什么用CNN?其实我之前也看过用CNN做的,有一部分是将骨架数据编码成其他类型的数据,就比如有编码成光谱的,有编码成色调、饱和度和亮度这种的。哎?我当时看了还很奇怪,饱和度和亮度有什么区别?不过这种创新点不好找,能编码的也就这么那么几种都让人写了,而且比较关键的是,这种编码真的会有专门用来做骨骼行为识别的图卷积好用?我看过的数据编码的论文都是没有公开源码,可能就是心里虚吧。
还有一些就是将骨骼数据编码成RGB图像的,最后输入的张量形状就是:帧数x关节数x3,这里的3是指三维坐标。看着是不是就是一张长宽不一样的RGB图像?但是这样设计会有很多问题的,就比如帧数,不同的序列可能不一样,形状都不一样肯定不能做批处理。这个问题很多用CNN做的都没有交代,你是找个最大帧数,其他不到这个帧数的用0填充还是怎么?还有就是现在很多数据集,就比如NTU RGB+D,里面的参与者不止一个,就是说一帧可能有两组关节,怎么处理?但是在这篇论文里,这些问题都考虑到了。
首先输入的数据会有两个分支,见下图。这两个分支很好理解,就是一个是单纯的帧数x关节数x3,另外一个Temporal difference分支其实就是相邻两帧之差组成的,形状跟上个分支是一样的(相邻的两两之差不应该少一帧么?我算错了?)
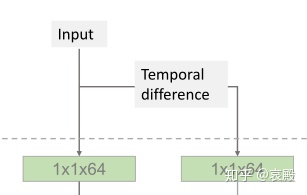
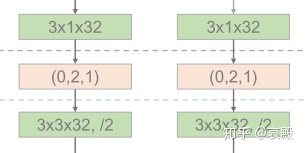
conv2后面的(0,2,1)是一个转换函数,学过tensorflow就应该知道tf.transpose()这个函数,这个函数就是用来交换维度的,比如正常三维数据的维度索引应该是(0,1,2),如果改成(0,2,1)就说明第二个维度和第三个维度交换了位置。这个交换维度有什么作用的,我们下面来讲。
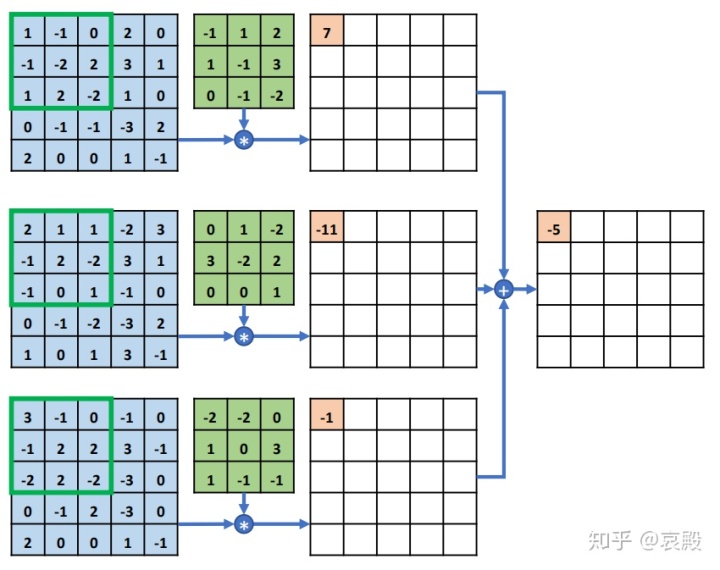
学过CNN的应该对下面这张图不陌生,我们的卷积核是要在三个通道上都要进行卷积操作,最后加在一起形成一个通道的图,当然这里只考虑了单通道的卷积核。这里的输入数据就是长x宽x通道数,你们在学CNN的时候是不是有介绍最重要的特点叫做”局部相关,权值共享“,这里的局部相关就是指长和宽聚集的特征就是一种局部特征。而通道数最后都是合在一起的,所以就是全局特征。那么思路就来了,如果输入是三维张量,想要哪一维度的全局信息就将哪个维度放在通道维度,得到的就是关于这个维度的全局信息。其实看过一些论文就知道,不论是CNN还是其他一些算法,无论怎么分层,一些关节点的关联性很差的,就比如手关节和腿关节,两个物理上相差很远,局部特征很难提取他们的联系。这就体现了转换维度获取全局特征的重要性。
他这里在conv1和conv2中将关节维度的卷积核设置为1也是为了在转换到通道维数是保持原来的关节数不变。conv3和conv4的/2其实就是步长为2的最大池化,这个很好理解。conv4后面的按Concat层其实就是按元素连接,这也很好理解。
后面要介绍的一个细节就是他对多人参与的行为进行识别。这里的多人参与就是比如拥抱和握手这种行为。他这里其实也做了很多种设计,首先具体怎么将多个人的骨骼数据进行合并处理,分为两种方案:
方案一是将所有参与者的数据在输入时直接堆叠在一起,就相当于在帧数维前面再加一个人数维。这样就要选择一个最大参与人数,当小于这个人数的时候用0填充。这做法也太简单暴力了吧!
方案二是将每个人的骨骼数据都加入到相同的子网中,就是最上面的网络框架,然后在conv6后面进行拼接。这里拼接方法有三种:沿通道直接连接或者按最大/均值连接。
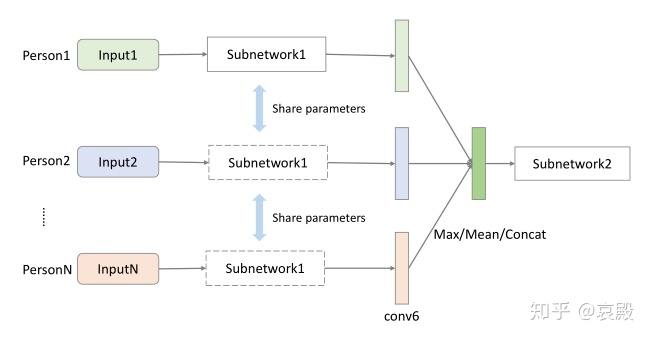
作者关于选择方案一还是方案二时,除了给了数据比较,在理论上也做了一些解释:不同人物的特征在高层次语义空间中更协调一致。我的英语不好,翻译的不怎么样,大概意思就是说,经过几层特征提取之后,不同人物的特征更像一点。关于方案二的三种拼接方法,只要大概了解输入的数据,肯定知道要设计很多子网,子网数量等于最大参与人数,人数不足肯定是0填充。用均值或者直接连接都会对整体造成影响,你想想有这么多0的情况下,求均值或者直接拼一起肯定会对最后的结果造成很大影响啊。用最大连接就没有这种困扰(好像有关节坐标是负的耶)。
后面有一部分内容好像是关于时间行为预测的,算是个附加功能,不算是行为识别的范畴了。我不太懂,大概意思就是将上面处理得到的特征图再进行一些处理,加入两个子网络,得到行为预测的结果。有兴趣的可以自行阅读一下。
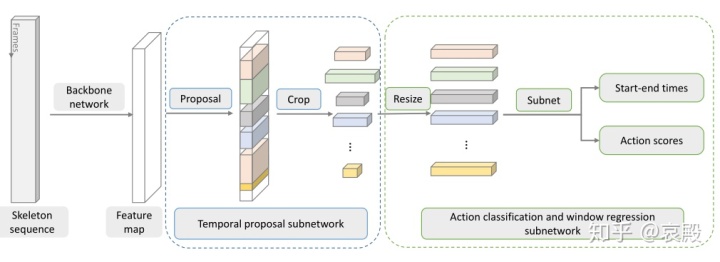
关于实验的一些细节是值得拿出来说一说的。上面说了关于不同序列有不同的帧数的问题,他这里是用的双线性内插法采样每个序列32帧。还有,为了证明他的多人参与识别的方法有效性,他用了一个双人运动的SBU Kinect数据集,这个数据集很小,只有8分类共282个序列。这里不同于很多论文采用数据增强,作者是在原有的网络框架下进行简化,减少了一个卷积层,也减少了通道维数。
总结一下,这篇论文是CNN方法里面非常好的一篇。首先他用CNN实现了全局特征的提取,这很不容易的,他那个调换维度可是真的秀。再就是他对多人参与的行为的处理,细节很到位。
萌新一个,有什么说的不对的请大家评论指出!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









