





 本文详细阐述了B树和B+树的概念及其在数据库索引中的应用,对比两者特性,解析为何B+树更适合数据库索引。
本文详细阐述了B树和B+树的概念及其在数据库索引中的应用,对比两者特性,解析为何B+树更适合数据库索引。


B树(又叫平衡多路查找树)
注意B-树就是B树,-只是一个符号。
B树的性质(一颗M阶B树的特性如下)
1、定义任意非叶子结点最多只有M个儿子,且M>2;
2、根结点的儿子数为[2, M];
3、除根结点以外的非叶子结点的儿子数为[M/2, M];
4、每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)
5、非叶子结点的关键字个数=指向儿子的指针个数-1;
6、非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
7、非叶子结点的指针:P[1], P[2], …, P[M];其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;
8、所有叶子结点位于同一层;
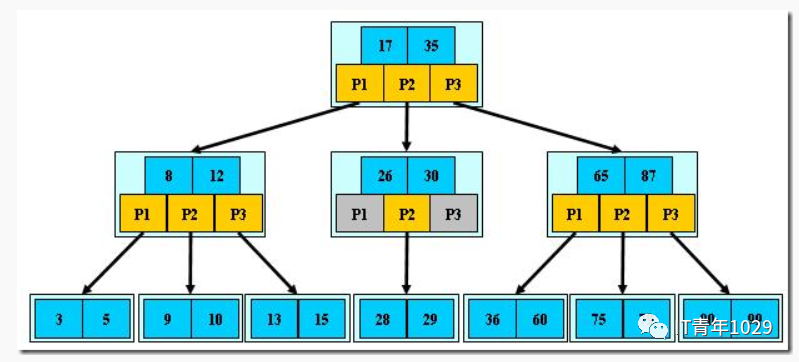
B-树的搜索,从根结点开始,对结点内的关键字(有序)序列进行二分查找,如果命中则结束,否则进入查询关键字所属范围的儿子结点;重复,直到所对应的儿子指针为空,或已经是叶子结点;
B-树的特性:
1.关键字集合分布在整颗树中;
2.任何一个关键字出现且只出现在一个结点中;
3.搜索有可能在非叶子结点结束;
4.其搜索性能等价于在关键字全集内做一次二分查找;
B+树
(1)简介
B+树是应文件系统所需而产生的一种B树的变形树(文件的目录一级一级索引,只有最底层的叶子节点(文件)保存数据)非叶子节点只保存索引,不保存实际的数据,数据都保存在叶子节点中,这不就是文件系统文件的查找吗?
我们就举个文件查找的例子:有3个文件夹a、b、c, a包含b,b包含c,一个文件yang.c,a、b、c就是索引(存储在非叶子节点), a、b、c只是要找到的yang.c的key,而实际的数据yang.c存储在叶子节点上。
所有的非叶子节点都可以看成索引部分!
(2)B+树的性质(下面提到的都是和B树不相同的性质)
1、非叶子节点的子树指针与关键字个数相同;
2、非叶子节点的子树指针p[i],指向关键字值属于[k[i],k[i+1]]的子树.(B树是开区间,也就是说B树不允许关键字重复,B+树允许重复);
3、为所有叶子节点增加一个链指针;
4、所有关键字都在叶子节点出现(稠密索引). (且链表中的关键字恰好是有序的);
5、非叶子节点相当于是叶子节点的索引(稀疏索引),叶子节点相当于是存储(关键字)数据的数据层;
6、更适合于文件系统;
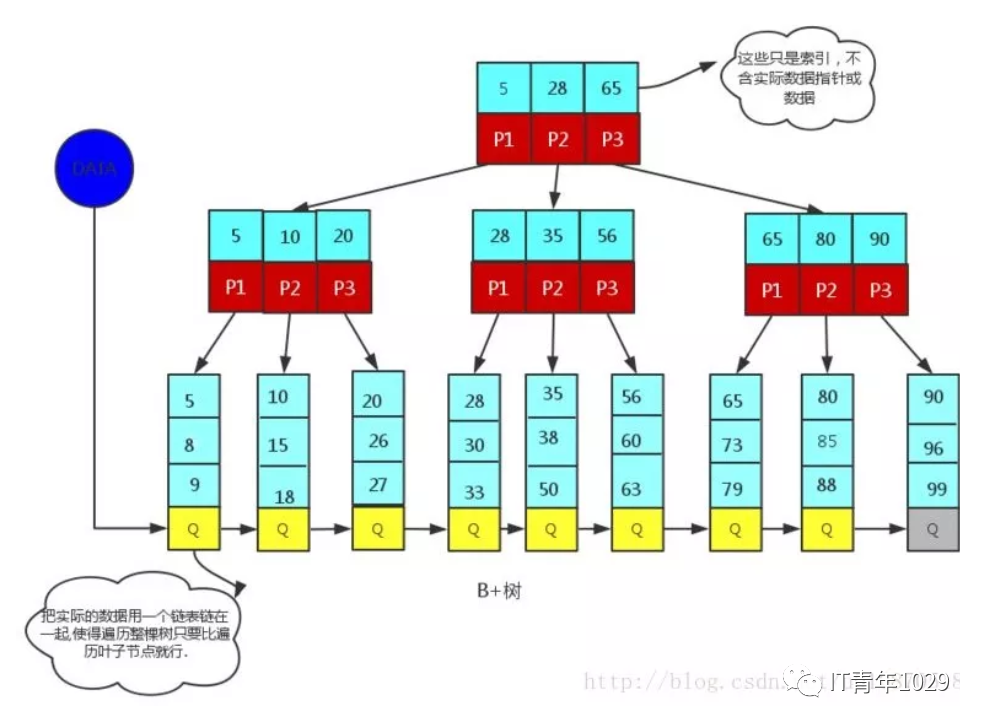
非叶子节点(比如5,28,65)只是一个key(索引),实际的数据存在叶子节点上(5,8,9)才是真正的数据或指向真实数据的指针。
应用
1、B和B+树主要用在文件系统以及数据库做索引,比如MySQL;(MySQL使用B+树)
B/B+树性能分析
n个节点的平衡二叉树的高度为H(即logn),而n个节点的B/B+树的高度为logt((n+1)/2)+1;
若要作为内存中的查找表,B树却不一定比平衡二叉树好,尤其当m较大时更是如此。因为查找操作CPU的时间在B-树上是O(mlogtn)=O(lgn(m/lgt)),而m/lgt>1;所以m较大时O(mlogtn)比平衡二叉树的操作时间大得多。因此在内存中使用B树必须取较小的m。(通常取最小值m=3,此时B-树中每个内部结点可以有2或3个孩子,这种3阶的B-树称为2-3树)。
为什么说B+树比B树更适合数据库索引?
1、 B+树的磁盘读写代价更低:B+树的内部节点并没有指向关键字具体信息的指针,因此其内部节点相对B树更小,如果把所有同一内部节点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多,一次性读入内存的需要查找的关键字也就越多,相对IO读写次数就降低了。
2、B+树的查询效率更加稳定:由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
3、由于B+树的数据都存储在叶子结点中,分支结点均为索引,方便扫库,只需要扫一遍叶子结点即可,但是B树因为其分支结点同样存储着数据,我们要找到具体的数据,需要进行一次中序遍历按序来扫,所以B+树更加适合在区间查询的情况,所以通常B+树用于数据库索引。
PS:我在知乎上看到有人是这样说的,我感觉说的也挺有道理的:
他们认为数据库索引采用B+树的主要原因是:B树在提高了IO性能的同时并没有解决元素遍历的我效率低下的问题,正是为了解决这个问题,B+树应用而生。B+树只需要去遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作或者说效率太低。
---------------------------面试常见问题-------------------------------------------------------------------------------------------------------------------
数据库为什么使用B+树而不是B树
B树只适合随机检索,而B+树同时支持随机检索和顺序检索;B+树空间利用率更高,可减少I/O次数,磁盘读写代价更低。一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。这样的话,索引查找过程中就要产生磁盘I/O消耗。B+树的内部结点并没有指向关键字具体信息的指针,只是作为索引使用,其内部结点比B树小,盘块能容纳的结点中关键字数量更多,一次性读入内存中可以查找的关键字也就越多,相对的,IO读写次数也就降低了。而IO读写次数是影响索引检索效率的最大因素;
B+树的查询效率更加稳定。B树搜索有可能会在非叶子结点结束,越靠近根节点的记录查找时间越短,只要找到关键字即可确定记录的存在,其性能等价于在关键字全集内做一次二分查找。而在B+树中,顺序检索比较明显,随机检索时,任何关键字的查找都必须走一条从根节点到叶节点的路,所有关键字的查找路径长度相同,导致每一个关键字的查询效率相当。
B-树在提高了磁盘IO性能的同时并没有解决元素遍历的效率低下的问题。B+树的叶子节点使用指针顺序连接在一起,只要遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作。
增删文件(节点)时,效率更高。因为B+树的叶子节点包含所有关键字,并以有序的链表结构存储,这样可很好提高增删效率。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









