





 本文介绍了三种比较两个Excel表格不同之处的方法:使用Excel的IF公式、条件格式筛选和Excel比较大师软件。IF公式需手动填充,条件格式筛选操作稍复杂,Excel比较大师效率高但不支持xlsx格式。每种方法适用场景各有特点。
本文介绍了三种比较两个Excel表格不同之处的方法:使用Excel的IF公式、条件格式筛选和Excel比较大师软件。IF公式需手动填充,条件格式筛选操作稍复杂,Excel比较大师效率高但不支持xlsx格式。每种方法适用场景各有特点。

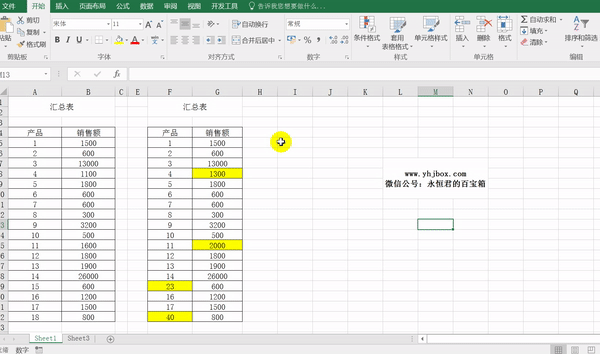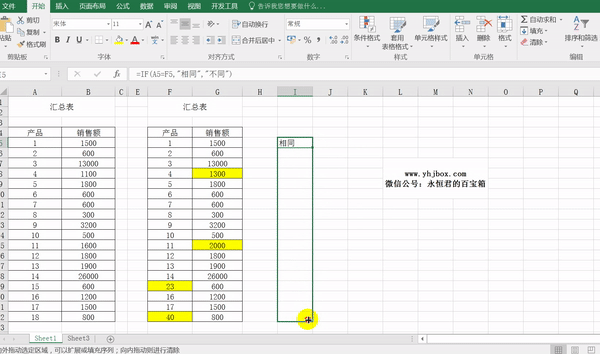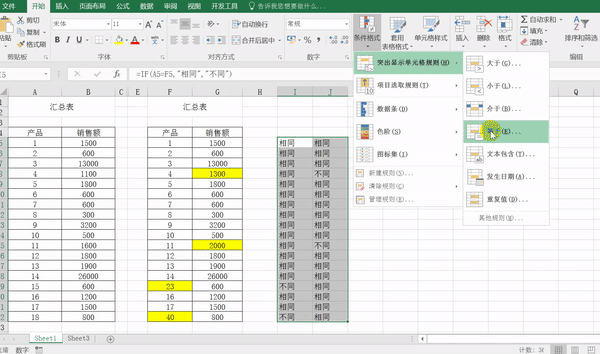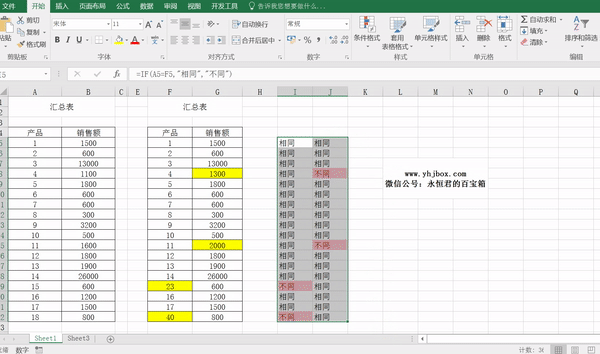
上一篇文章介绍了如何快速找出两个word文档不同的地方,这篇文章来说说如何快速找出两个Excel表格不同的地方,这里说的两个Excel表格,可以是同一个工作簿的不同sheet,也可以是两个不同的Excel文件,如下图:

黄色的部分是我手工标注出来的。现在我需要通过软件程序来自动识别。
方法一:利用Excel-If公式
将两张表格复制到同一个sheet当中,然后在表格数据的同行输入下面的这行公式=IF(A5=F5,"相同","不同"),向下、向右填充即可。

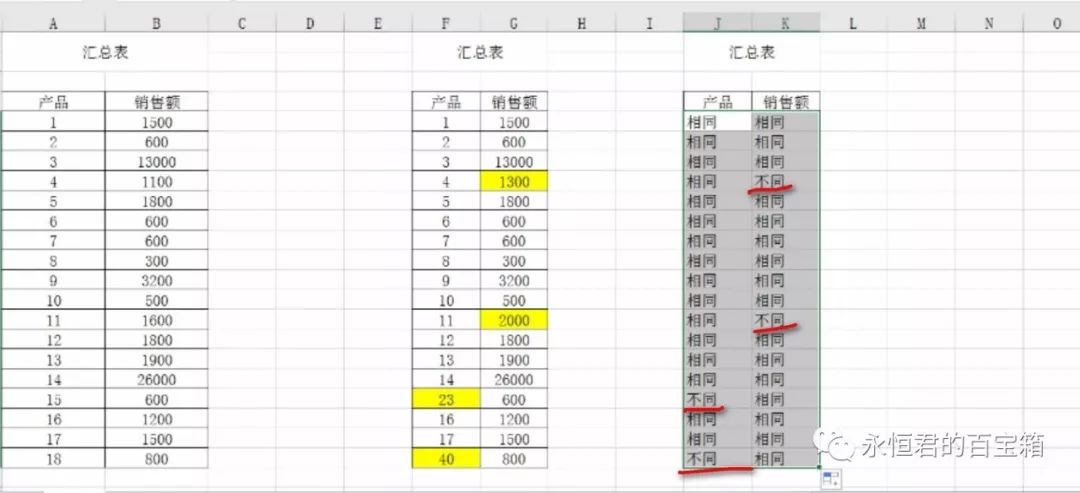
表格中标有“不同”的即表示两个表格该位置的数据不一样。如果数据太大,还可以通过条件格式来把“不同”标上颜色,更能清楚的看到。
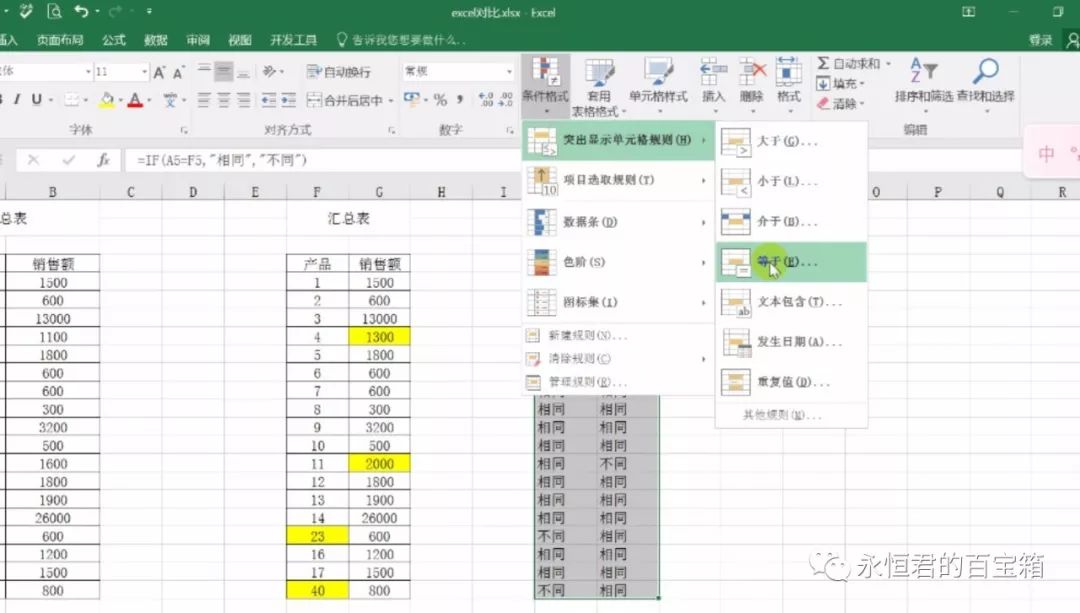
演示一下:
方法二:利用Excel条件格式来筛选。
将两张表格的内容复制到同一个工作簿中(可以是同一个sheet,也可以是不同的sheet)。
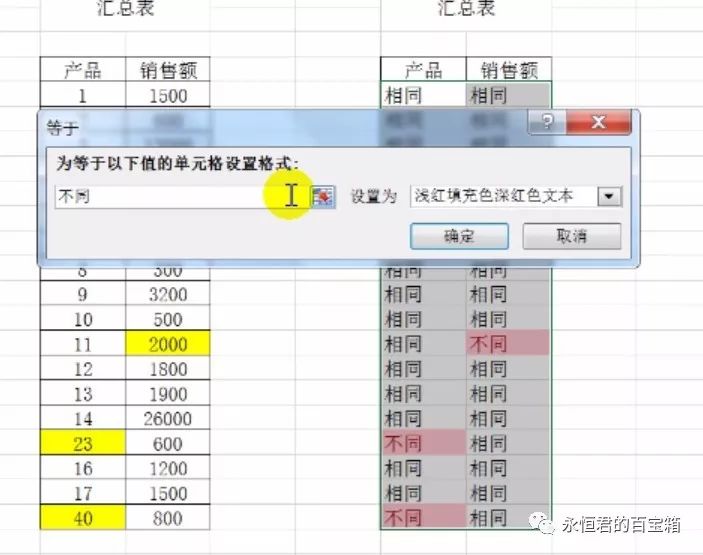
选中其中一个表格内容,然后【条件格式】-【新建规则】-【只包含以下内容的单元格设置格式】,下面选项设为【不等于】,区域是【=Sheet2!A4】(注意,默认是绝对引用,改成相对)。
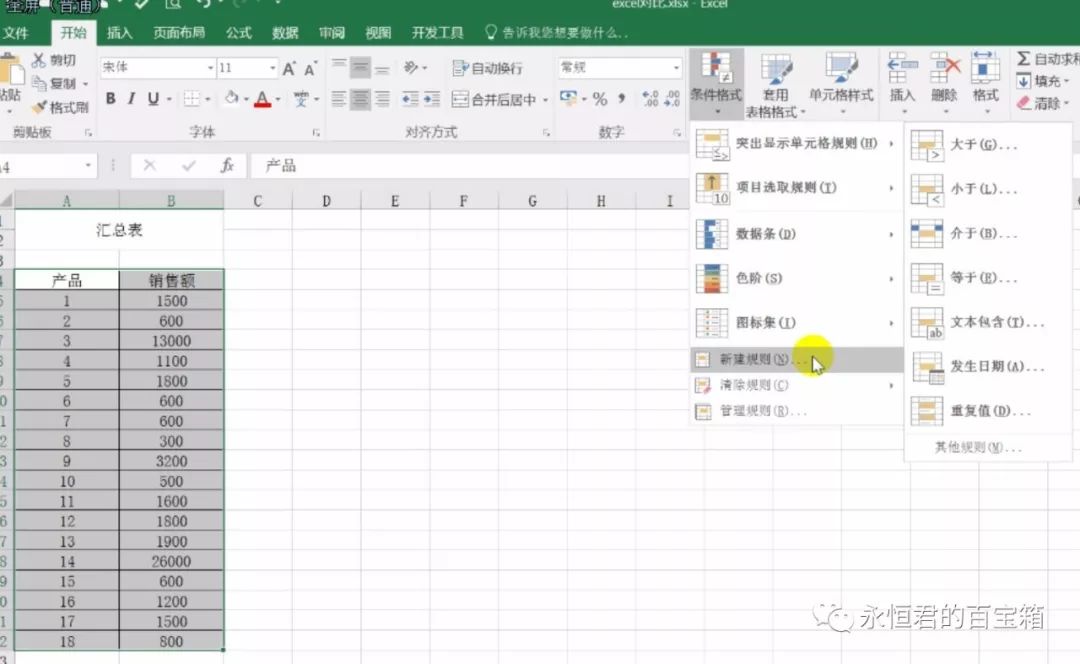
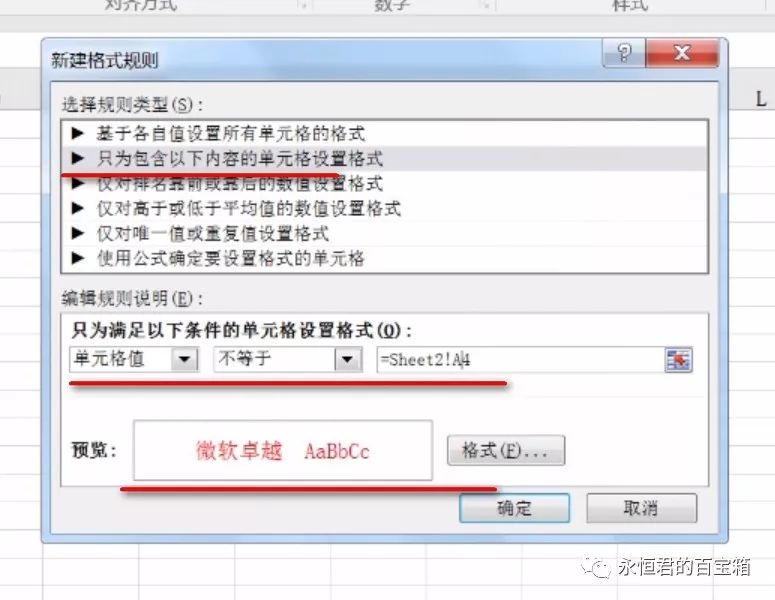
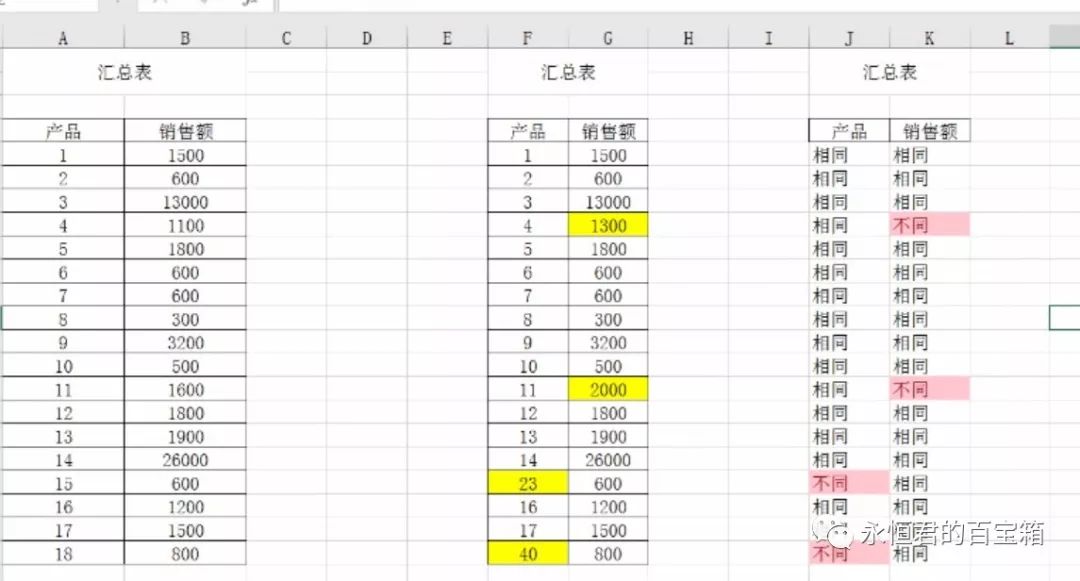
程序会自动筛选出两个表格不同的内容,并标成红色字体。
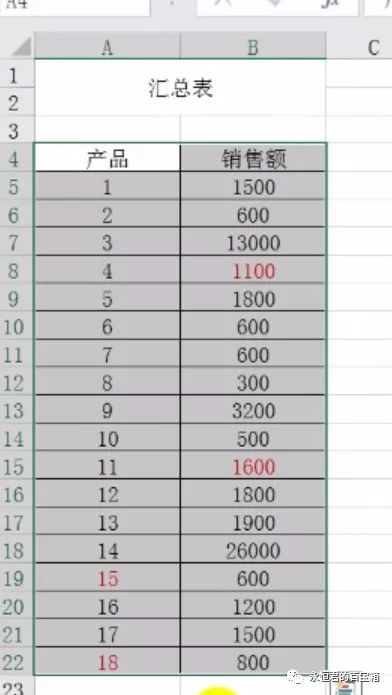
演示一下:

注意:两个表格行数不同的话,多出来的内容无法对比到。
方法三:利用Excel比较大师软件
这个软件可以对比同一个excel文件里的不同sheet,也可以对比不同excel文件里的不同sheet。但是注意,这个软件只能支持xls格式。
软件使用比较简单,选择好excel文件和需要对比的sheet,再确定好报告输出方式和类型,开始比较即可。
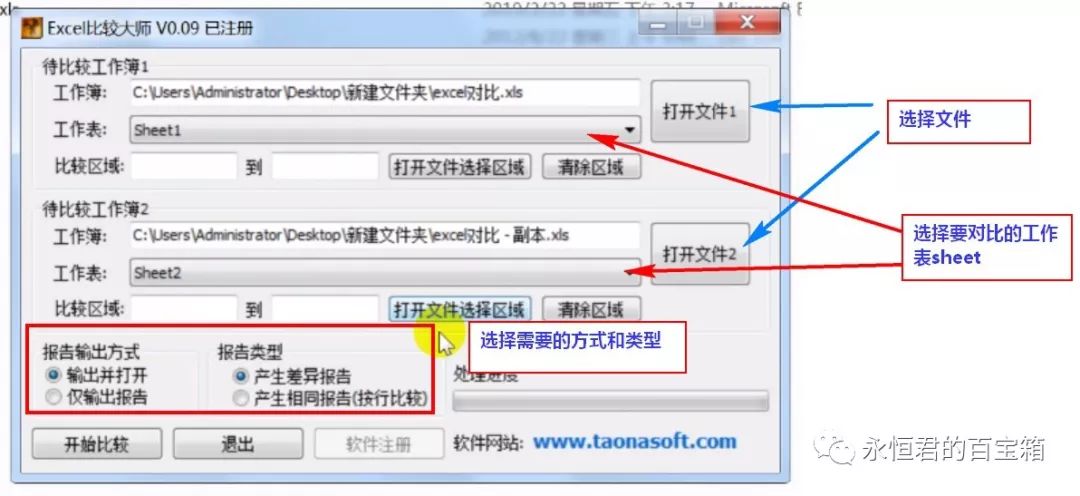
程序会自动生成一个report.xls,如下图,会详细说明不同的地方。
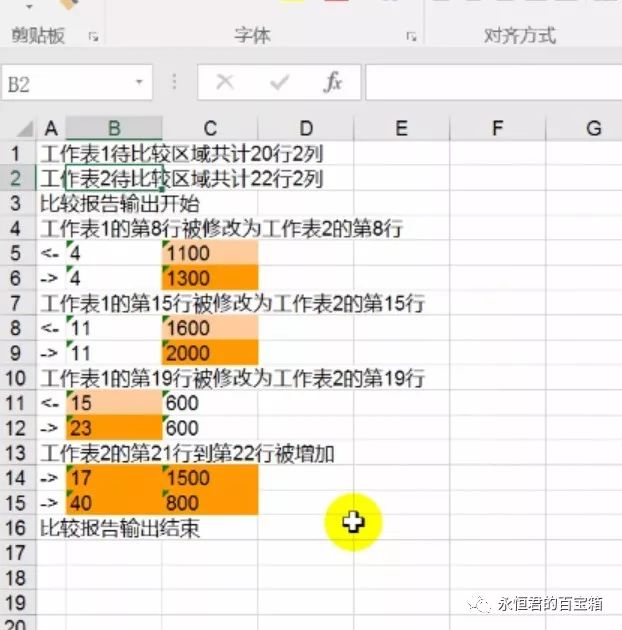
小结一下:
方法一(利用Excel-If公式):简单快捷,但是需要在同一个excel文件里对比。
方法二(利用Excel条件格式来筛选):操作较复杂,并且表格行数要统一,否则多出来的内容无法对比到。
方法三(利用Excel比较大师软件):操作简单,效率高,但是不支持xlsx文件。
欢迎交流!
微信公众号:永恒君的百宝箱
个人博客:www.yhjbox.com

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









