




 本文介绍了Spark MLib在机器学习中的应用,强调了它相对于MapReduce的优势。内容涵盖机器学习流水线的概念,通过DataFrame进行数据转换和估计器的组织。还详细阐述了TF-IDF特征抽取的过程,并提及特征转换如StringIndexer和VectorIndexer的使用方法。
本文介绍了Spark MLib在机器学习中的应用,强调了它相对于MapReduce的优势。内容涵盖机器学习流水线的概念,通过DataFrame进行数据转换和估计器的组织。还详细阐述了TF-IDF特征抽取的过程,并提及特征转换如StringIndexer和VectorIndexer的使用方法。
Spark MLib
Intro
MapReduce 不适合做机器学习-> 反复读写磁盘的开销/不适合机器学习需要的大量迭代计算。
MLib中只包含能够在集群上运行良好的并行算法,有些算法不能并行执行,所以无法包含在MLib中。
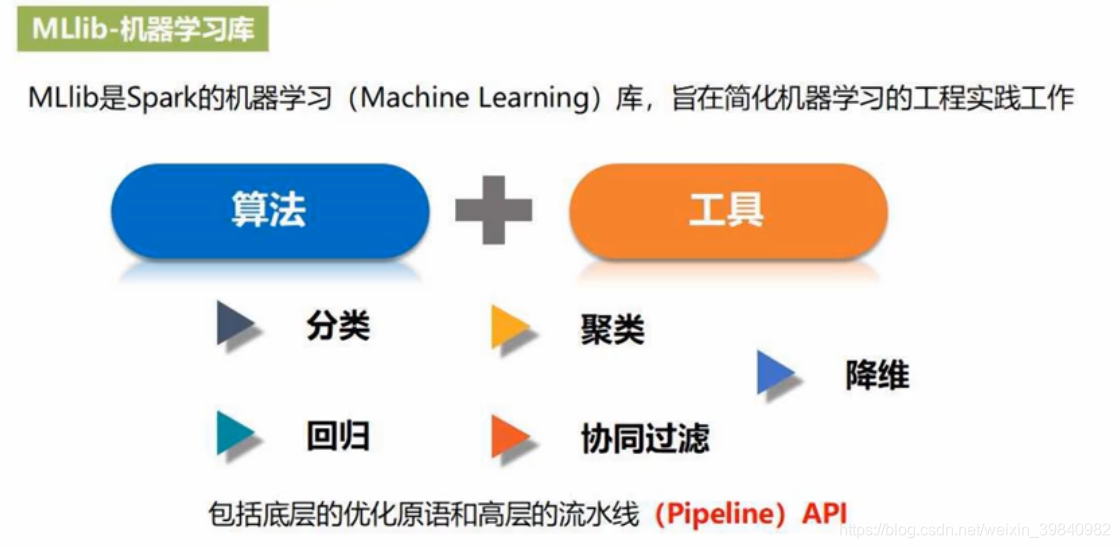
package:spark.mlib基于RDD;spark.ml基于dataframe。
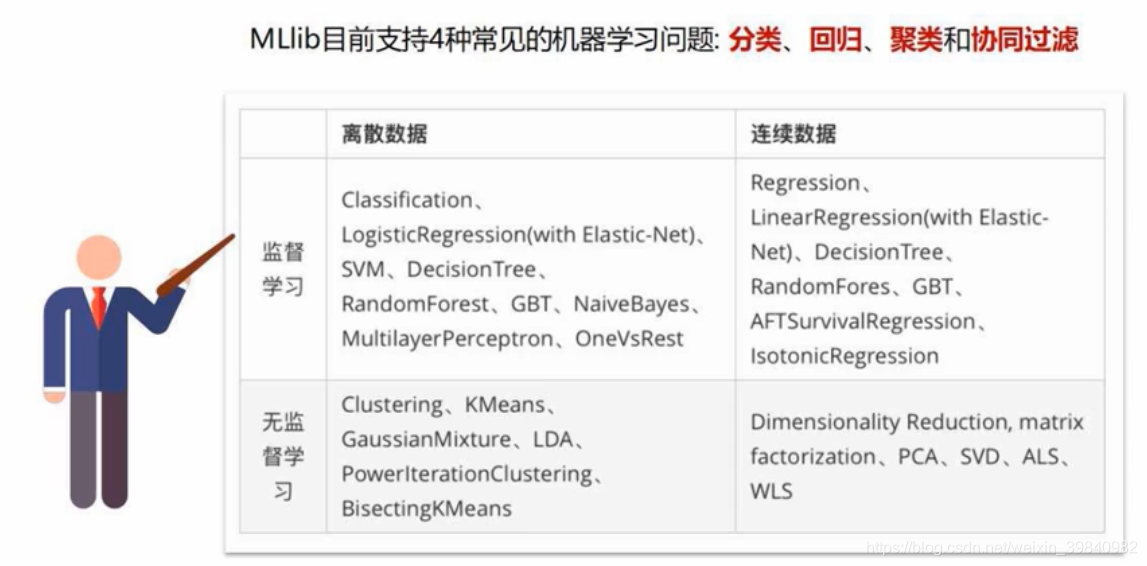
机器学习流水线
dataframe/transform/estimator
1.定义pipeline中各个流水线阶段pipelinestage(包括转换器和评估器);
(转换器和评估器有序组织起来构建成pipeline)
pipeline = Pipeline(stages = [stage1,stage2,stage3])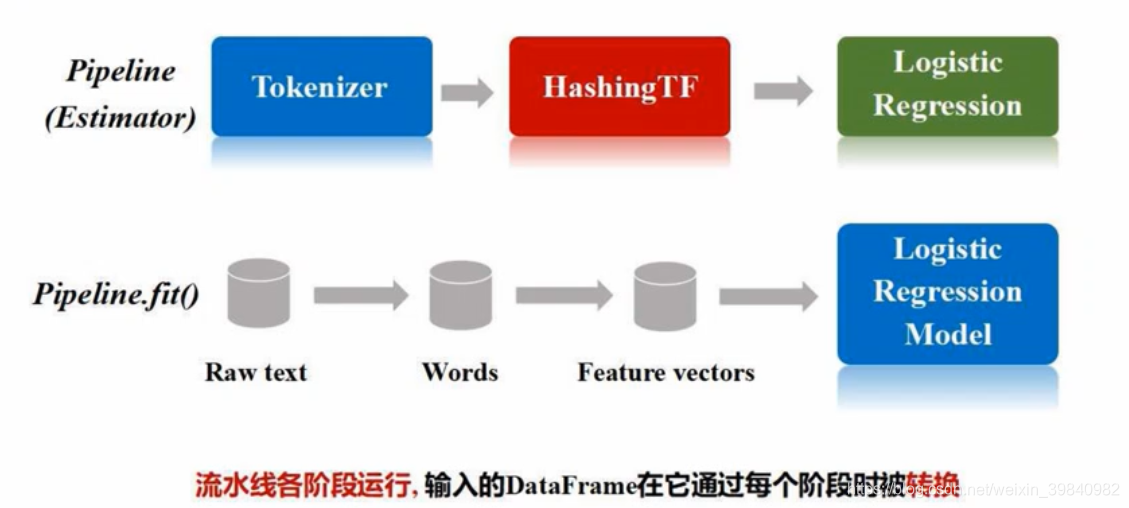
流水线本身也可以看成是一个估计器。在fit方法运行之后,产生一个pipelin
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









