






 文章介绍生成验证式的软件自动修复方法,以解决软件开发中缺陷修复成本高的问题。该方法定义搜索空间,通过特定算法搜索、验证来生成补丁。文中详细介绍GenProg、RSRepair、ssFix、CapGen、ARJA等经典方法的原理和流程,软件自动修复研究仍在持续。
文章介绍生成验证式的软件自动修复方法,以解决软件开发中缺陷修复成本高的问题。该方法定义搜索空间,通过特定算法搜索、验证来生成补丁。文中详细介绍GenProg、RSRepair、ssFix、CapGen、ARJA等经典方法的原理和流程,软件自动修复研究仍在持续。
这篇文章主要对生成验证式的软件自动修复方法的相关研究工作做简要介绍,有兴趣的读者可查找参考文献自行阅读。
一、背景介绍
软件开发过程中不可避免的引入缺陷,即所谓的Bug,研究表明,对这些缺陷的修复占了总开发开销的50%,消耗了大量人力成本和时间成本。
为了解决这一问题,越来越多的学者着力于软件自动化调试的研究中去。比如一些缺陷自动定位的算法,使用缺陷程序在测试过程中的执行路径信息,包括测试通过或者测试失败时的执行路径,通常认为存在缺陷的语句或者表达式,频繁出现在测试失败的执行路径,而不常出现在测试通过的执行路径,根据这种思想,识别出可能存在缺陷的代码元素,报告给修复人员。即便有了缺陷自动定位技术,修复人员还要对这些可疑位置进行人工分析,手动修复。而一类新的方法,软件自动修复,可以对缺陷程序直接产生可通过测试用例集的补丁版本,大大减少了开发人员的负担。
Gazzola等人的文章中讨论了两大类软件自动修复方法,分别是生成验证式(Generate-and-Validate)的软件修复方法,以及语义驱动式(Semantics-driven)的软件修复方法。语义驱动式的方法将修复问题形式化表示,通过求解的方式来得到最终的补丁,比较经典的算法有SemFix,DirectFix,Angelix,NOPOL,DynaMoth等。而生成验证式的方法会定义一个搜索空间,通过特定算法搜索,不断生成候选,然后测试验证,在空间中搜索到潜在的补丁,具体流程如下图所示。
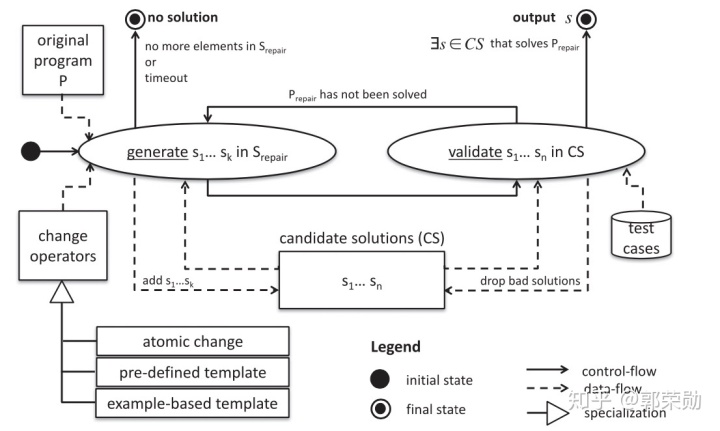
在生成过程中,将设定的修改算子应用到初始程序,会生成一系列新的程序版本作为候选补丁;在验证过程中,会将这些候选补丁运行测试用例集,如果有一个候选补丁可以通过所有的测试用例,那么作为最终结果输出。如果没有可以通过测试的候选补丁,那么会返回到生成过程,直到满足结束条件:1. 找到正确补丁;2. 空间已经搜索完毕;3. 超时。
比较经典的生成验证式的修复方法有GenProg,RSRepair等,下面详细介绍下这几种方法。
二、相关研究
1. GenProg
举个例子
1 /* requires: a >= 0, b >= 0 */
2 void gcd(int a, int b) {
3 if (a == 0) {
4 printf("%d", b);
5 }
6 while (b != 0)
7 if (a > b)
8 a = a - b;
9 else
10 b = b - a;
11 printf("%d", a);
12 exit(0);
13 }上面的程序是用来求两个数的最大公约数,但是存在一个bug,当a=0且b为正数,虽然可以输出正确结果,但是会陷入6-9-10行的死循环。
GenProg首先会根据测试用例运行时的执行路径,定位出进行修改的位置,选择那些失败测试用例执行到的,并且通过的测试用例没有执行到的位置,比如说,gcd(1071, 1029)正常输出21,执行了第2-3、6-13行,而gcd(0,55)是失败的测试用例,执行了第2-5、6-7、9-10行,因此后面主要针对第4-5行来进行修改。
GenProg在对这些位置进行修改时可以对代码进行插入、删除或替换,基于一个假设,就是大多数的缺陷可以通过使用该程序其他位置的代码来进行修复,比如程序可能因为缺少空指针检查或者数组边界检查而产生缺陷,但是在该程序的其他位置可能会存在这些检查的代码,于是在对可疑的位置进行修改时,只用程序中出现过的代码来插入或替代,这样大大减小了搜索空间。比如上面的例子,可以在第4行和第5行中间插入 exit(0) 和 a=a-b,如下所示:
1 void gcd(int a, int b) {
2 if (a == 0) {
3 printf("%d", b);
4 exit(0); // inserted
5 a = a - b; // inserted
6 }
7 while (b != 0)
8 if (a > b)
9 a = a - b;
10 else
11 b = b - a;
12 printf("%d", a);
13 exit(0);
14 }这样便可以修复先前提到的bug。然而,可以发现,第5行的插入语句事实上是冗余的,GenProg对这样的冗余修复做了最小化处理,通过最小化最初的程序版本和得到的修复版本之间的差异,保留最小的有效修复部分,最终得到更为精简的修复版本:
3 if (a == 0) {
4 printf("%d", b);
5 + exit(0);
6 }
7 while (b != 0) {算法介绍
GenProg方法的核心是遗传编程——GP,GP是一种基于生物遗传演化的搜索算法,它会维护一个由不同程序个体组成的population,一个用来评估不同个体适应度的fitness function,个体经过不断的交叉和变异操作,筛选出适应度高的个体,直到搜索到目标。

上面是方法的伪代码,下面具体介绍下每个步骤:

第1行和第2行:确定测试用例运行时的执行路径。
第3行:结合执行路径的权重。
GenProg将程序表示为语句级别的抽象语法树(AST),并且给每条语句赋予权重,权重由测试用例运行时的执行路径所决定,这样每条语句对应一个<statement, weight>的两元组。
首先,将运行失败测试用例P(n)时经过的语句权重设置为1.0。然后用运行通过的测试用例P(p)执行时的路径来调整权重,如果P(n)中执行的语句也在P(p)被执行,那么权重被设为W_path,如果W_path被设为0,那么就完全不用考虑P(p)中执行到的语句,一般将W_path设为0.01效果会好一些。这个权重后面会影响到语句是否应用变异算子。
这样,每个GP得到的程序个体都会被表示为<statement, weight>的序列。
第4行:构建GP初始的population。就是将初始程序复制pop_size份。
第5-16行:GP的主循环。
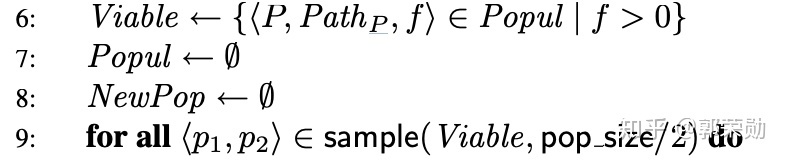
- 第6行:移除掉每个测试用例都失败的个体。
- 第9行:在剩下的个体中随机采样。
在GP的每次迭代中,GenProg首先移除掉fitness为0即每个测试用例都失败的个体,然后在剩下的个体中随机选出pop_size/2个个体,这些个体将会作为后面交叉操作的父个体。GenProg应用变异和交叉来产生新的个体,变异就是在程序上应用一些小的修改,比如增删改,交叉就是将某个程序的前面部分和另外程序的后面部分组合。

- 第10行:应用交叉操作。
交叉操作的伪代码如下:

交叉操作时选择一个cutoff作为分割点,将分割点之后的所有语句交换,比如输入[P1, P2, P3, P4]和[Q1, Q2, Q3, Q4],cutoff为2,那么输出的C=[P1, P2, Q1, Q2], D=[Q1, Q2, P3, P4],但是交叉操作不是一定发生的,发生的概率是当前语句的权重值。
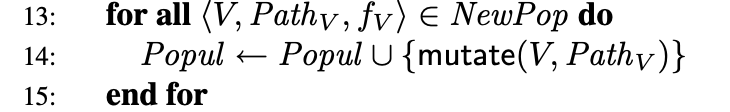
- 第14行:将交叉得到的子个体与交叉前的父个体,加入到population,并应用变异算子。
变异算子的伪代码如下:

prob_i是第i个语句变异的概率,事实上就是我们之前设定的权重值,如果随机产生的浮点数不大于该条语句的权重值,并且不大于一个全局变异率,就对这条语句进行变异操作。
变异算子包括insert、swap、delete,随机选择一个分别进行下面操作:
- swap:将这条语句替换为程序中出现过的一条其他语句。
- insert:在这条语句之后,插入程序中出现过的一条其他语句。
- delete:删除这条语句。
可以看到,在进行变异操作之后,仍然保留了<statement, weight>的形式,保证了变异前后这样的语句序列的长度不变。
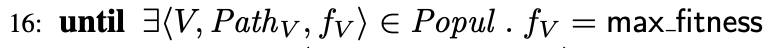
- 第16行:达到终止条件。
GenProg采用的Fitness Function计算了程序个体通过测试用例的权重和,计算公式为:
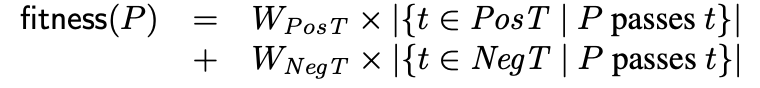
如果程序个体编译不通过,那么fitness为0,如果编译通过那么用上面的公式计算。W_PosT是通过每个正例(即初始程序可通过的测试用例)的权重,W_NegT是通过每个反例(即初始程序失败的测试用例)的权重。
第17行:得到最小化修复补丁。
一旦得到一个可以通过所有测试用例的个体,GenProg会对它进行最小化处理,因为这个个体中可能会包含一些对修复效果无关紧要的修改部分。GenProg结合了delta debugging和树结构距离度量里面的一些思想,在保证通过所有测试用例的前提下,丢弃一些修改,直到不能通过某些测试。
GenProg在提出时针对的是C语言的缺陷修复,而Java版本的jGenProg,kGenProg后续也相继实现。
2. RSRepair
RSRepair使用完全随机搜索的方法,并且通过对测试用例排序来加快修复效率。
算法介绍

第1-3行,对测试用例排序进行初始化。
测试用例集排序的思想是,如果一个测试用例发现缺陷的能力越强,越应该排在前面,这样如果这个测试用例运行不通过,就不需要进行下面的测试,可以加快程序验证的速度。对于测试用例集T中的每个测试用例t,赋予其index值,表示在这个测试用例上运行失败的次数。将失败测试用例的index初始值设为1,意味着初始程序不能通过;其余测试用例的index初始值设为0。
第4行,仿照GenProg的方法进行缺陷定位。
第5行,初始化成功标记为false。
第6-21行,迭代搜索过程直到成功标记为true。
- 第7行,将GenProg中的变异操作应用到缺陷位置生成新的程序个体pt;
- 第8到20行,按照顺序依次在pt上运行测试用例;
- 第11到14行,如果当前测试用例不通过,那么对应的index加1,并且重新按照index大小对测试用例集T排序。
- 第15-16行,如果最后一个测试用例通过,即所有测试用例都通过,那么就得到最终结果。
- 第17-18行,继续运行下一个测试用例。
可以看到RSRepair的方法很简单,甚至比GenProg少了交叉操作和fitness的计算。事实上,RSRepair的提出说明GenProg的修复并没有完全发挥GP的优势,而只是用到了变异操作里的随机性。
3. ssFix
ssFix的大致思想是通过语法级别的代码搜索,在代码库现有的代码中,找到可以修复缺陷的补丁。
算法介绍
主要有四个部分:缺陷定位、代码搜索、补丁生成和补丁验证。
缺陷定位
ssFix使用现有的缺陷定位工具GZoltar,他可以识别出一系列可能存在缺陷的语句,并把这些语句按照可疑值从高到低排序。除此之外,如果缺陷程序抛出异常,ssFix会首先将异常抛出的stack trace所在的语句加入到可疑语句列表(GZoltar没有这个特性)。每次ssFix会从中选择一条语句作为修复目标。
代码搜索
- Step1. 目标代码块识别
ssFix首先要划定代码块的范围(叫做tchunk),包括选出的可疑语句和它的上下文。一方面,代码块不能太小(如 return x),这样不能包含足够的上下文信息;另一方面,代码块不能太大,因为太大了反而不能找到和它语法相近的其余代码块。

大致算法是,设定一个代码块长度阈值(6行),
- 如果可疑语句s长度已经大于等于阈值,则把s单独作为tchunk;
- 否则,看s的父语句s0,可以简单理解为用花括号包含s的语句,若长度小于等于阈值,则把s0作为tchunk;
- 否则,看s的前一条语句s1和后一条语句s2,如果存在,就将其和s作为整体,如长度小于等于阈值,则整体作为tchunk;
- 否则还是把s单独作为tchunk。
ssFix识别代码库中的片段(叫做cchunks)的方法不设定阈值,而是将所有包含子语句块的复合语句,和所有同一个代码块的连续三条语句,作为cchunk。
- Step2. 提取token
提取token分为两部分:结构上的k-gram token,conceptual(概念上的?)token。
- k-gram token
ssFix将代码块中的部分token用特定的占位符来表示,比如用$v$表示非JDK的变量和字段,用$m$表示非JDK的方法,其他的token还是它本身,代码块可以被表示为这样token的有序列表,同时为了保持连贯性,括号和分号又将这个列表切分为一个个子列表。对每个token子列表,再用k-gram的方法进行提取。
例如 str.charAt(1)=='e'这条语句,如果用$v$代替str,用$ln$代替1,k设为5,提取后的k-gram就是{ $v$.charAt($ln,.charAt($ln$) ,charAt($ln$)==,($ln$)=='e'}。 - conceptual token
ssFix将代码块中的标识符提取出来,并且识别出其中的驼峰命名和下划线+数字的命名方式,将这些token全部小写,并且去除掉长度小于3或者大于32的token,并去掉停词和java关键字。
例如对于 str.getChars(0,strLen,buffer,size),这样一条语句,处理之后的结果应该是 {“str”, “getchars”, “chars”, “strlen”, “str”, “len”, “buffer”, “size”} ,因为get是个停词所以被去掉了。 - Step3. 检索候选
对于每个tchunk,ssFix调用Apache Lucene 搜索引擎在代码库中获取相关联的cchunks,按照TF-IDF的值从高到低排序。
补丁生成
这一步是使用cchunk来为tchunk生成补丁。
- Step1. 候选翻译
因为tchunk和cchunk可能来自不同的程序,使用不同名字的变量和方法,所以需要将cchunk的变量进行替换,得到一个新的使用tchunk中标识符的代码块,称之为rcchunk。
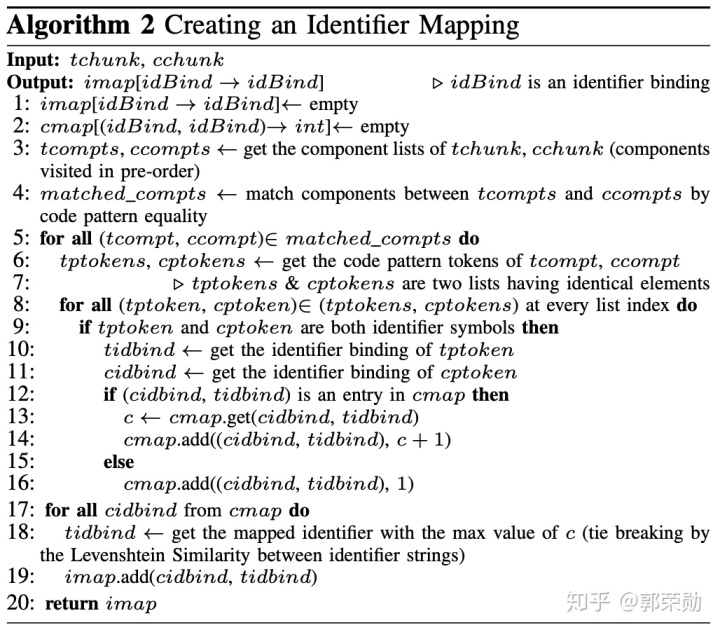
第1~2行:初始化。
第3行:前序遍历tchunk和cchunk的语法树,分别得到不包含数字常量、文本和标识符的代码块成分,tcompts和ccompts。这些成分代表了所有标识符的上下文信息。
第4行:比较tcompts和ccompts,如果两个成分的代码模式,即代码块识别时的token子列表相同,则它们之间可以匹配。
第6行:获取到匹配的代码模式token。
第8~16行:对于两个列表每个相同下标的token,如果它们都是标识符,那么它们之间建立一条映射关系。重复这样的操作,最后对于每个cchunk中的标识符,选择映射关系数量最多的tchunk中的标识符,作为最终的映射。
最后根据这个映射关系得到rcchunk。
- Step2. 成分匹配
ssFix扩展了ChangeDistiller的算法,来建立语法树节点之间的映射关系,这样之后,不仅得到一些能够匹配的成分,而且还可以得到tchunk和rcchunk之间的语法区别。
- Step3.修改
基于上一步得到的tchunk和rcchunk之间匹配的成分和未匹配的成分,ssFix对tchunk进行一些改动来得到新的补丁。改动类型包括替换、插入和删除。
- 替换:
ssFix会将tchunk中的成分tcpt替换为rcchunk中匹配的成分ccpt,规则如下:

- 插入和删除:
对于插入,ssFix会将rcchunk中不匹配的成分cstmt插入到tchunk来产生新的补丁。首先ssFix会判断rcchunk是否可以插入,主要看tchunk中有没有对cstmt来说冗余的代码。然后ssFix会估算插入的位置,挨个尝试每个可能的位置。
对于删除,ssFix会将tchunk中不匹配的成分删除来生成新的补丁。
补丁验证
ssFix对每个cchunk都会生成一批补丁,在验证之前,ssFix会将他们进行排序,排序基于以下规则:
- 由替换或插入生成的补丁优先级高于由删除生成的补丁;
- 在上一条基础上,更小修改树高度的补丁优先度较高;
- 在上一条基础上,更小编辑距离的补丁优先度较高。
ssFix对每个cchunk产生的补丁排序后只取前50个补丁进行验证,先执行失败测试用例,通过后执行所有测试用例。
4. CapGen
CapGen是一种使用到上下文信息帮助补丁生成的修复技术。与之前的技术相比,它更善于生成语义正确的补丁,而不是对测试过拟合的补丁。
算法介绍
加强的操作算子
与之前的技术采用替换、插入、删除这样的操作算子不同,CapGen采用的是一种加强的操作算子。CapGen分析了Le Goues等人的数据集中超过700个项目的3000多个真实修复的补丁,通过比较补丁修复前后AST节点级别的差异,提取了30个加强的操作算子,包括“在if语句下插入表达式语句”,“替换一个简单的变量名”等等,所有算子如下表所示:

每个算子都有一个出现的频率,CapGen将这个频率近似地看作该算子能够成功修复的概率。
上下文相似的ingredient
Fixing ingredient,即用来替换和插入目标位置的代码元素,已有的研究已经发现大部分的ingredient都能在缺陷位置的相同文件中找到。CapGen在ingredient的选择上又考虑了上下文信息,认为ingredient的上下文应该和目标修改位置具有相似性。CapGen从三个方面来描述上下文之间的相似性:
- 系谱上下文 Genealogy Contexts
系谱上下文可以大概反映出当前节点N大概率使用的位置。
首先,对于节点N,遍历它的祖宗节点直到到达方法声明的节点,收集到它的祖宗节点信息。
其次,还可以收集和节点N在同一个语句块中的语句和表达式,这些称之为兄弟节点信息。
将这些信息表征为不同节点类型出现的次数统计,存储起来。
算法伪代码如下所示:

收集好ingredient节点的系谱上下文信息
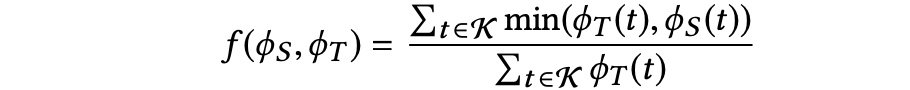
其中, K表示
- 变量上下文 Variable Contexts
变量上下文就是当前节点访问到的变量集合,包括局部变量和字段的访问。每个
计算变量上下文之间相似度的公式如下:
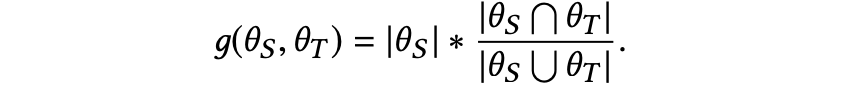
其中,
- 依赖上下文 Dependency Contexts
依赖上下文是当前节点N所影响到的节点和影响到节点N的节点。CapGen基于def-use关系来对节点N中的变量进行分析,具体算法如下:

最终收集到当前节点N的依赖上下文信息,即N影响到的节点和影响到N的节点的类型个数,最后通过下面公式计算ingredient节点的依赖上下文
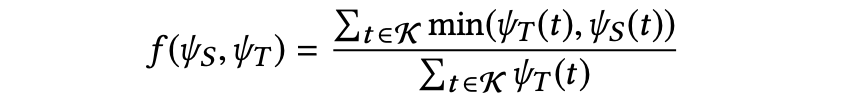
最后依据上面得到的三个方面的上下文相似度,计算最终的相似度。
对于不同的算子,CapGen采取了不同的最终相似度计算公式:
对于替换类型的算子:
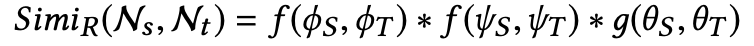
对于插入类型的算子,变量上下文并不是很重要,因为要插入的ingredient可能和插入位置的语句功能不同:
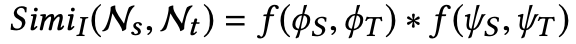
对于删除类型的算子,计算更为复杂。假设要从N_t节点下删除掉N_s节点,首先会找到和N_s节点相同的另一个N_o节点,如果N_o节点的上下文和N_t的上下文相似,那么认为N_s在相似的上下文被使用,相应的被删除的概率就会变小:
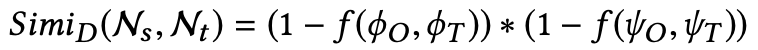
补丁优先级排序
CapGen生成的每个补丁都可以被表示为P=的形式,其中N_t表示缺陷定位定位到的目标修改节点,M表示选定的加强操作算子,N_s表示选定的ingredient。
最终给补丁进行优先级排序时的计算公式为:
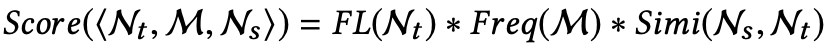
其中,
CapGen使用到了程序中蕴含的上下文信息,生成正确补丁的准确性更高。
5. ARJA
Yuan Yuan等人认为GenProg并没有完全表达出GP强大的搜索能力,并提出了一个新的基于GP的修复系统——ARJA。
算法介绍
1. 缺陷定位和覆盖率分析
ARJA使用现有的缺陷定位技术Ochiai,来找到可疑出错的语句及对应的可疑度。
另外,通过对测试用例执行时的覆盖率分析,ARJA找出所有至少被一个测试用例执行过的语句作为seed语句,后面可以用来当做ingredient。
2. 测试用例过滤
为了加速GP的fitness function计算过程,ARJA对测试用例集进行了过滤,记录每个测试用例执行时经过的语句,如果不包含上一步得到的可疑语句,就把该测试用例过滤掉。
3. 确定scope
对于某个可疑语句位置,大多数seed语句不能成为ingredient,主要是因为他们可能访问了一些在该位置不可见的变量或方法。
这一步确定出每个可疑语句位置所能访问到的变量和方法范围。变量包括字段、方法参数和局部变量,而字段又包括所在类本身声明的字段,从父类继承的字段和外部类声明的字段。方法和字段类似。
4. 筛选ingredient
ARJA在筛选ingredient的时候,定义了3个模式,分别是从同一文件、同一包、同一应用中获取。
除此还定义了2种ingredient的选择方法:直接使用和基于类型匹配。
- 直接使用原始Ingredient,首先会检查里面的变量和方法是否在该位置的scope。
- 基于上面方法,如果不在则会进行类型匹配,使用能访问到的变量和方法将不在的进行替代,生成新的Ingredient。
5. GP搜索补丁
- 补丁表示方法。使用3个数组:b中每一位表示是否对该位置进行修改;u中每一位表示修改类型;v中每一位表示使用到的Ingredient。
- 初始化Population。
- 计算Fitness。两个优化目标:最小化patch size,即修改复杂度;最小化加权失败率,即修改错误率。
- 遗传算子。交叉和变异。
- 搜索算法。NSGA-II。
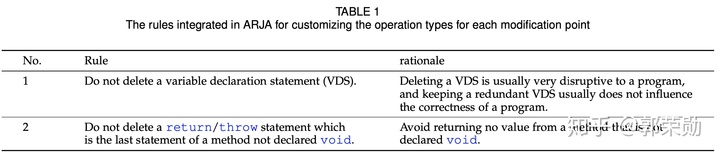
6. 基于规则的搜索空间缩减
- 定制操作类型,比如变量声明和return语句不能删除。
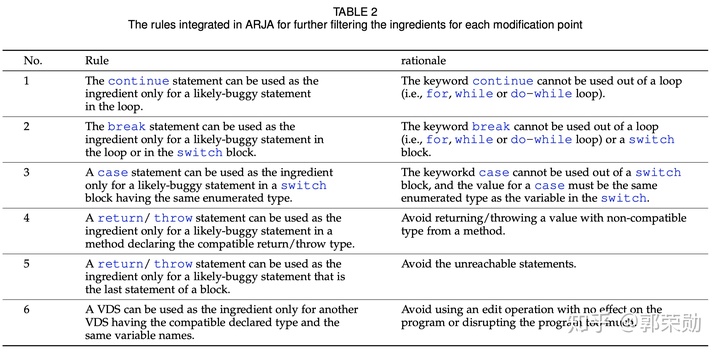
- 进一步过滤Filter,比如continue只能在循环里,break只能在循环和switch里。
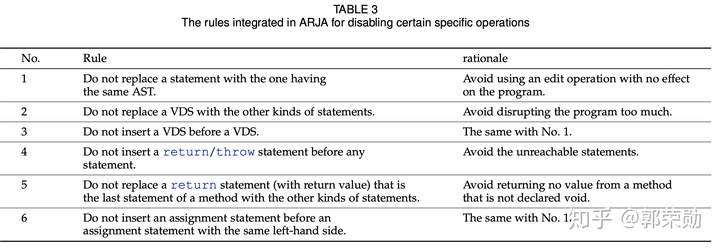
- 丢弃其他特定操作,比如在其他语句前面插入return或throw语句。
ARJA在Defects4J上修复了59个bug,表现优于同样是基于GP的jGenProg。甚至能修复多位置的bug。
三、结语
软件自动修复的研究仍在继续,如何更准确、更迅速的修复更多的缺陷,已经成为一个引人关注的问题。
如果想了解更多软件自动修复方面的内容,可以关注 http://program-repair.org/,这个社区中包含了最新的APR技术和相关论文。
参考资料
Weimer W, Nguyen T V, Le Goues C, et al. Automatically finding patches using genetic programming[C]//2009 IEEE 31st International Conference on Software Engineering. IEEE, 2009: 364-374.
Qi Y, Mao X, Lei Y, et al. The strength of random search on automated program repair[C]//Proceedings of the 36th International Conference on Software Engineering. 2014: 254-265.
Xin Q, Reiss S P. Leveraging syntax-related code for automated program repair[C]//2017 32nd IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 2017: 660-670.
Wen M, Chen J, Wu R, et al. Context-aware patch generation for better automated program repair[C]//2018 IEEE/ACM 40th International Conference on Software Engineering (ICSE). IEEE, 2018: 1-11.
Monperrus M. Automatic software repair: a bibliography[J]. ACM Computing Surveys (CSUR), 2018, 51(1): 1-24.
Gazzola L, Micucci D, Mariani L. Automatic software repair: A survey[J]. IEEE Transactions on Software Engineering, 2017, 45(1): 34-67.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









