





 本文介绍了Keras Tokenizer的基本参数、使用方法和实例,展示了如何通过Tokenizer进行文本分词和序列化,适用于各种NLP项目。核心功能包括词频统计、过滤特殊字符、转换大小写等,是实现深度学习模型输入的基础工具。
本文介绍了Keras Tokenizer的基本参数、使用方法和实例,展示了如何通过Tokenizer进行文本分词和序列化,适用于各种NLP项目。核心功能包括词频统计、过滤特殊字符、转换大小写等,是实现深度学习模型输入的基础工具。
Tokenizer 是一个用于向量化文本,或将文本转换为序列的类。是用来文本预处理的第一步:分词。
简单来说,计算机在处理语言文字时,是无法理解文字的含义,通常会把一个词(中文单个字或者词组认为是一个词)转化为一个正整数,于是一个文本就变成了一个序列。Tokenizer 的核心任务就是做这个事情。
一、基本参数说明
keras.preprocessing.text.Tokenizer(num_words=None,
filters='!"#$%&()*+,-./:;<=>?@[]^_`{|}~tn',
lower=True,
split=' ',
char_level=False,
oov_token=None,
document_count=0)num_words:保留的最大词数,根据词频计算。默认为None是处理所有字词。如果设置成一个整数,那么最后返回的是最常见的、出现频率最高的 num_words 个字词。filters:过滤掉常用的特殊符号,默认上文的写法就可以了。lower:是否转化为小写。split:词的分隔符,如空格。char_level:是否将每个字符都认为是词,默认是否。在处理中文时如果每个字都作为是词,这个参数改为True.oov_token:如果给出,会添加到词索引中,用来替换超出词表的字符。document_count:文档个数,这个参数一般会根据喂入文本自动计算,无需给出。
二、对象或实例方法
fit_on_texts(texts) :
- 参数 texts:要用以训练的文本列表。
- 返回值:无。
texts_to_sequences(texts) :
- 参数 texts:待转为序列的文本列表。
- 返回值:序列的列表,列表中每个序列对应于一段输入文本。
texts_to_sequences_generator(texts) :
- 本函数是texts_to_sequences的生成器函数版。
- 参数 texts:待转为序列的文本列表。
- 返回值:每次调用返回对应于一段输入文本的序列。
texts_to_matrix(texts, mode) :
- 参数 texts:待向量化的文本列表。
- 参数 mode:'binary','count','tfidf','freq' 之一,默认为 'binary'。
- 返回值:形如
(len(texts), num_words)的numpy array。
fit_on_sequences(sequences) :
- 参数 sequences:要用以训练的序列列表。
- 返回值:无
sequences_to_matrix(sequences) :
- 参数 sequences:待向量化的序列列表。
- 参数 mode:'binary','count','tfidf','freq' 之一,默认为 'binary'。
- 返回值:形如
(len(sequences), num_words)的 numpy array。
三、属性
word_counts :字典,将单词(字符串)映射为它们在训练期间出现的次数。仅在调用fit_on_texts之后设置。
word_docs :字典,将单词(字符串)映射为它们在训练期间所出现的文档或文本的数量。仅在调用fit_on_texts之后设置。
word_index :字典,将单词(字符串)映射为它们的排名或者索引。仅在调用fit_on_texts之后设置。
document_count :整数。分词器被训练的文档(文本或者序列)数量。仅在调用fit_on_texts或fit_on_sequences之后设置。
四、简单示例
from keras.preprocessing.text import Tokenizer
tokenizer = Tokenizer()
text = ["今天 武汉 下 雨 了", "我 今天 上课", "我 明天 不 上课", "武汉 明天 不 下 雨"]
tokenizer.fit_on_texts(text)- word_counts 属性:
tokenizer.word_counts
- word_docs 属性:
tokenizer.word_docs
- word_index 属性:
tokenizer.word_index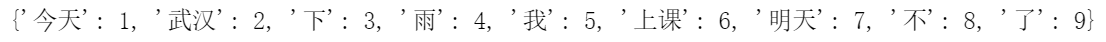
- document_count 属性:
tokenizer.document_count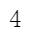
五、参考文献
- https://www.jianshu.com/p/ac721387fe48
- https://blog.youkuaiyun.com/wcy23580/article/details/84885734
- https://keras-cn-docs.readthedocs.io/zh_CN/latest/preprocessing/text/

















 2832
2832

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









