




 本文详细分析了Kafka的Sender线程工作原理,包括Sender线程如何通过RecordAccumulator筛选并发送数据,利用NetworkClient进行IO操作,以及Metadata的更新。Sender线程中的关键组件如KafkaClient、Metadata和RecordAccumulator的角色和交互过程得到阐述,同时深入探讨了NetworkClient的inFlightRequests管理、元数据更新和Selector的nio操作。
本文详细分析了Kafka的Sender线程工作原理,包括Sender线程如何通过RecordAccumulator筛选并发送数据,利用NetworkClient进行IO操作,以及Metadata的更新。Sender线程中的关键组件如KafkaClient、Metadata和RecordAccumulator的角色和交互过程得到阐述,同时深入探讨了NetworkClient的inFlightRequests管理、元数据更新和Selector的nio操作。
对于 RecordAccumulator 的理解,当不断有新的消息被加入之后,使得它的 batch 满了或者说创建了新的 batch 那么它就会唤醒 sender 线程将消息进行逐一的发送。
这是本人花了一些时间整理的 Sender 线程的 UML 图:
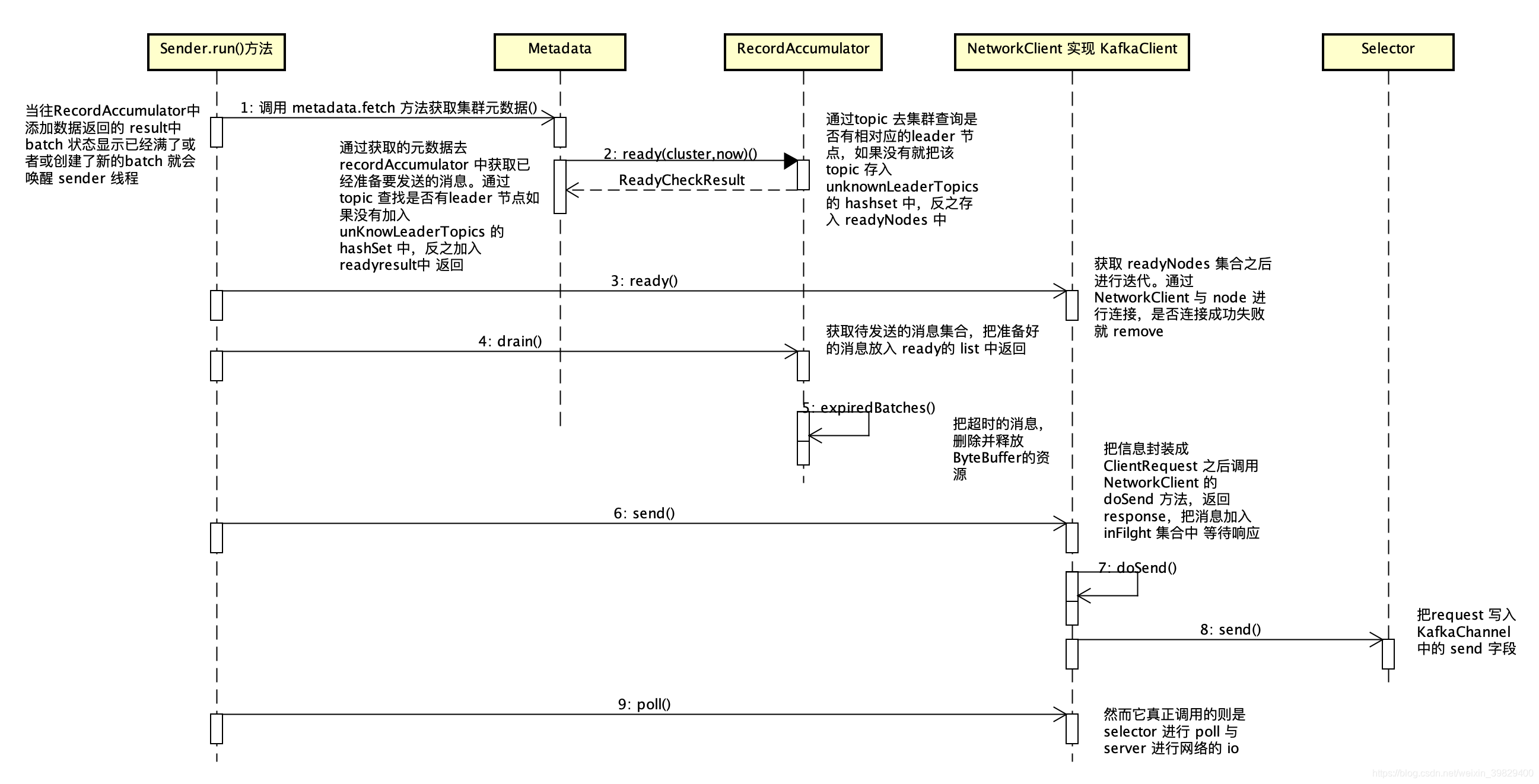
整体的调用流程图中都有明确的注释,接下来逐一进行分析:
首先我们来看一下 sender 类,它实现了 runnable 接口,执行单独死循环的线程
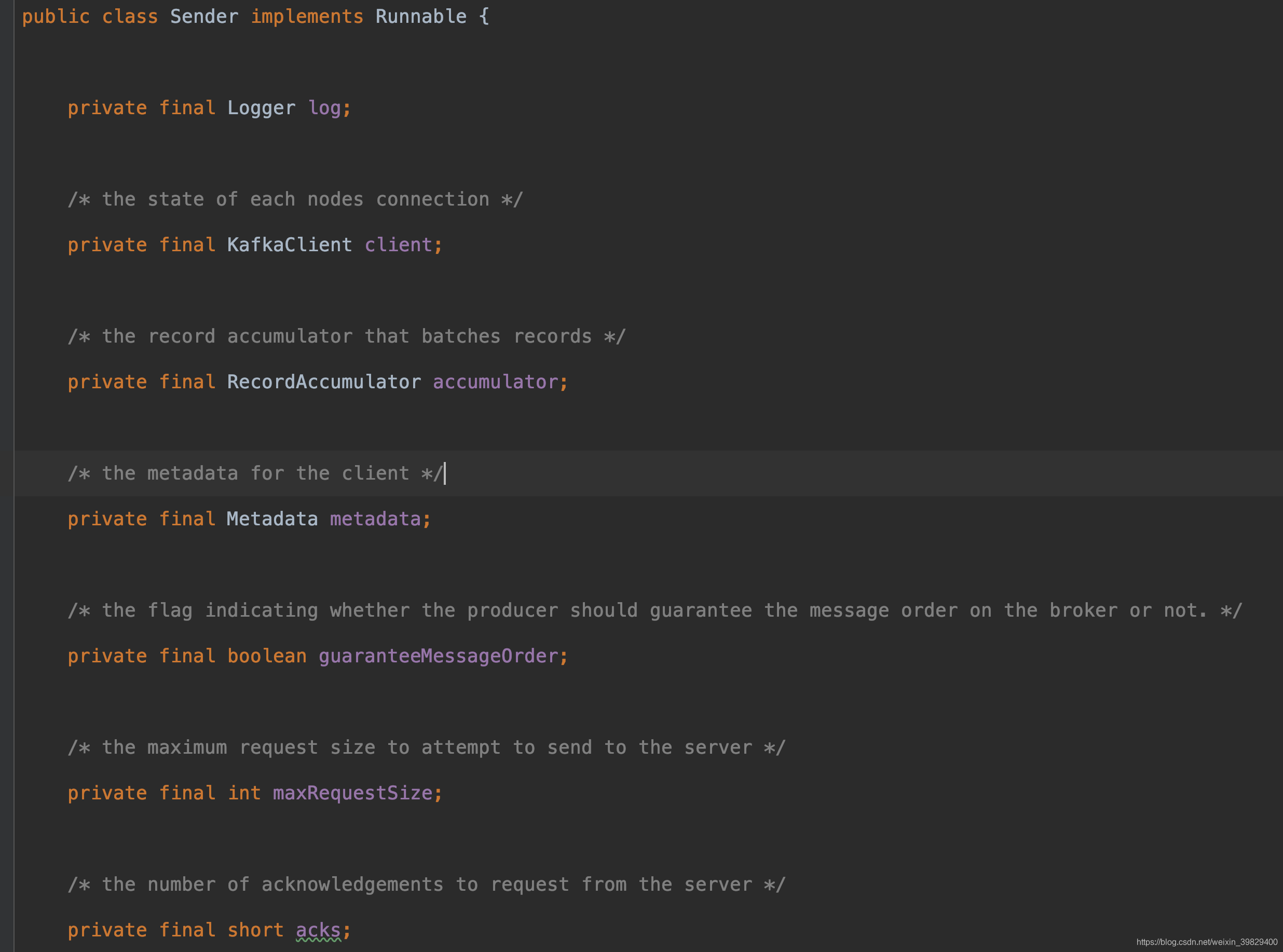
在 Sender 线程中有三个组件很关键
KafkaClient:它是一个接口,实现它的是 NetworkClient,它用于把消息封装成clientRequest 让如 selector 的 send 字段,所以说真正与 sever 进行 io 操作的是 selector,它采用了 java 中的 nio
Metadata:用于获取集群中的元数据,更新等操作
RecordAccumulator:用于获取预备好的集合,会调用 ready 方法。
接下来,来看一下 sender 线程实现的 run 方法,真正的核心在于它重载的 run 方法
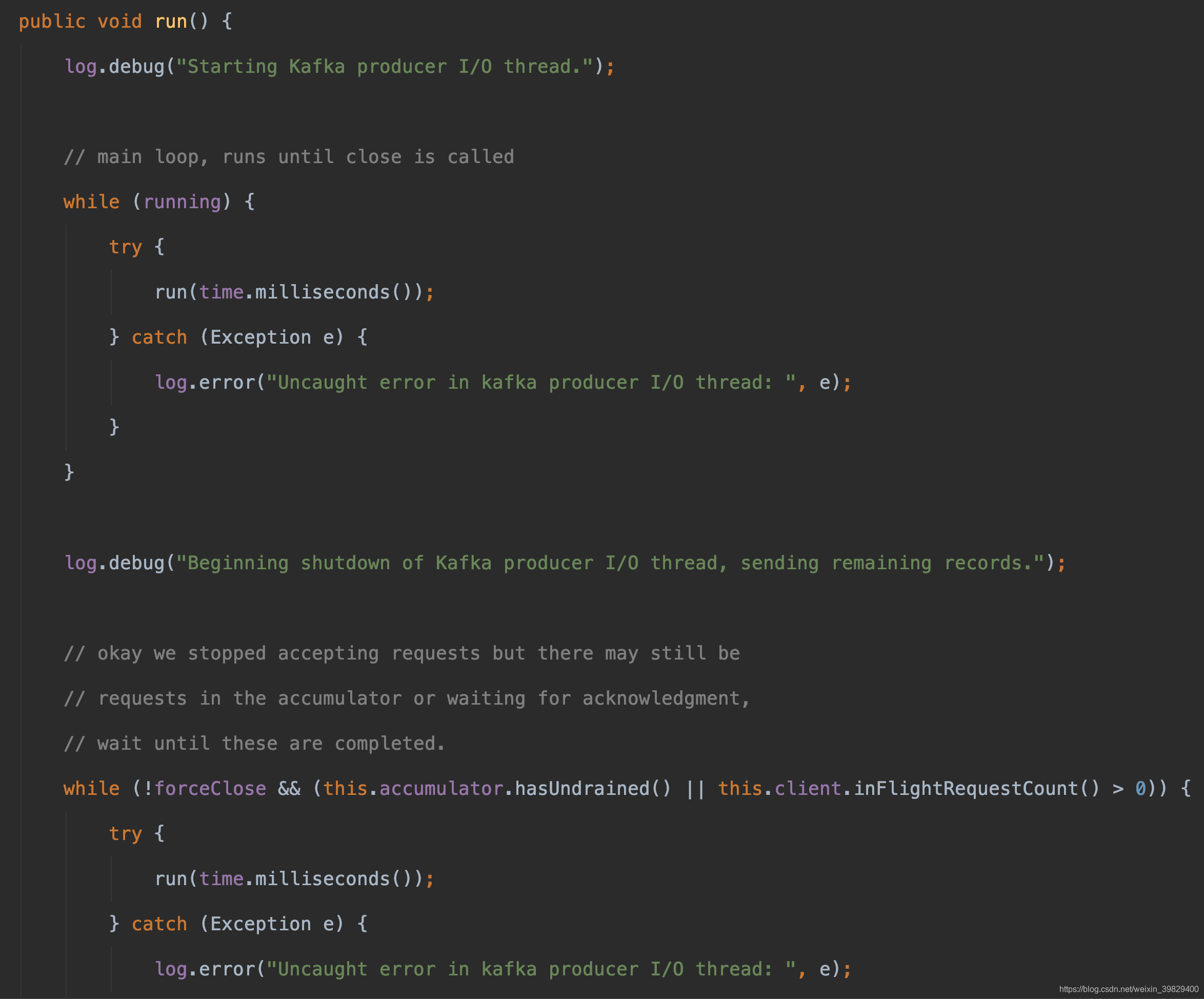
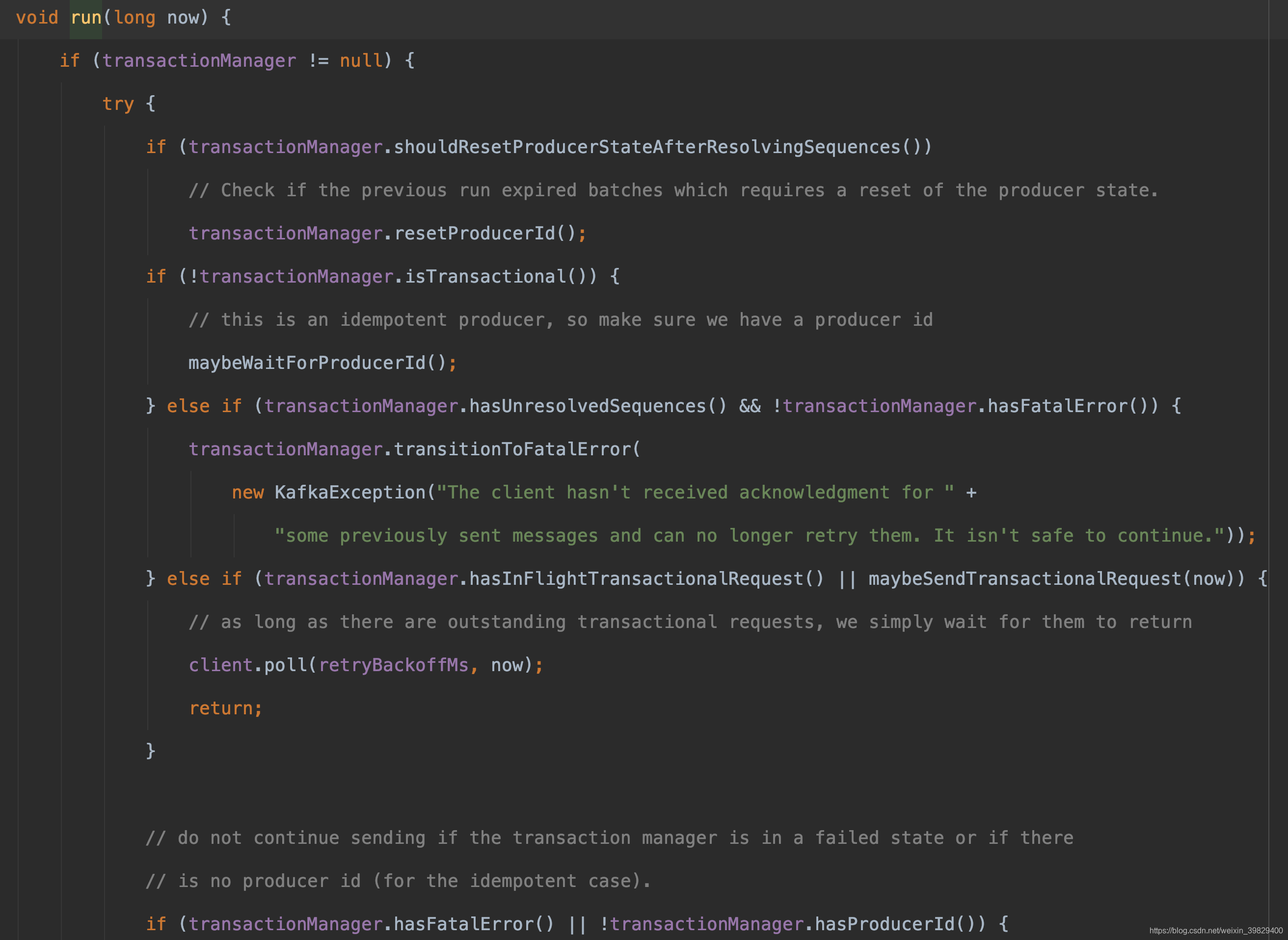
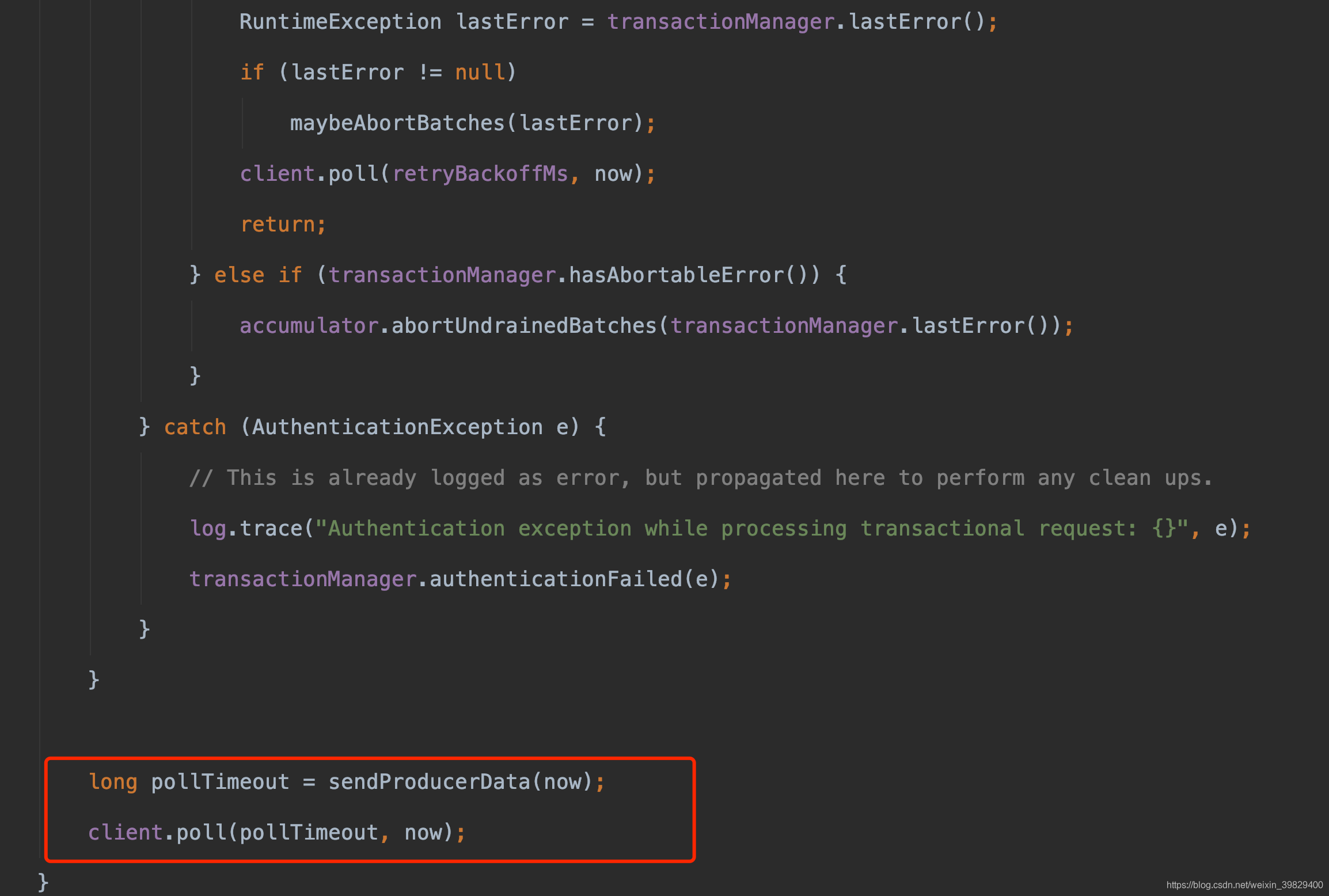
除了红色框内的内容其他的是跟事务有关,我还没有对事务进行 debug 进行学习,所以暂不讨论
sendProducerData方法主要还是筛选数据,把数据放入 selector 的 send 字段中等操作
poll 方法是真正进行io 操作的
sendProducerData流程:
(1)首先通过上面述说的 metadata类中的方法 fetch 获取集群中的元数据,其中 clusterId 是服务器随机生成的
(2)调用 accumulator.ready 方法筛选出准备好的集合,流程是遍历 recordAccumulator 中的所有数据<TopicPartition,Deque<ProducerBatch= >> 获取 key 也就是 topicPartition,通过这个 key 去查找是否有这个 node,如果
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1186
1186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









