




车牌识别是非常基础的案例,其中包括blob分析、形状特征的提取与转换、仿射变换等。
blob分析:从一幅图像将获取到相同特征、颜色的区域联合起来,然后按要求将不同区域提取出来。涉及到的技术包括去燥、滤波、二值化、图像分割等。
形状特征的提取与转换:每一块区域都有它自己的的形状特征,就好比世界上没有相同的树叶一样。提取就是通过特征筛选自己要的区域,转换就是区域转换成想要形状,一般是转换成矩形或圆形,这样方便对复杂的区域进行图像处理。
辐射变换:我自己的理解就是对图像区域进行平移、旋转得到的新的坐标、角度。这就相当于侧方位停车,车就是图像区域,将车停到规定的车位肯定需要旋转与平移,而车位就是自己要的新图像区域。
简单了解后,附源代码:
dev_close_window ()
dev_open_window (0, 0, 512, 512, 'black', WindowHandle)
read_image (Image, 'C:/Users/LWJ/Desktop/AS_1/斜着的车牌.jpg')
dev_display (Image)
*反色图像,即白底黑字变黑底白字的效果
invert_image (Image, ImageInvert)
*拆分3通道并转换为hsv的颜色空间
decompose3 (ImageInvert, Red, Green, Blue)
trans_from_rgb (Red, Green, Blue, Hue, Saturation, Intensity, 'hsv')
*blob分析处理步骤
threshold (Intensity, Regions, 0, 99) //二值化后能很好的满足选取要求,故不再开运算等操作
connection (Regions, ConnectedRegions)
*在得到很好的字符后,进行剔除周围环境的影响,即形状特征的选择
select_shape (ConnectedRegions, SelectedRegions, ['rect2_len1','row'], 'and', [8.5,180], [8.9,200])
*联合连通域形成一个区域,并将该区域转化为矩形,方便对该字符区域的校正
union1 (SelectedRegions, RegionUnion)
shape_trans (RegionUnion, RegionTrans, 'convex')
*仿射变换(对字符区域的校正)
orientation_region (RegionTrans, Phi) //求矩形摆放角度
area_center (RegionTrans, Area, Row, Column) //求区域的面积及中心坐标
vector_angle_to_rigid (Row, Column, Phi, Row, Column, Phi, HomMat2D) //计算仿射变换的原位置
affine_trans_image (Image, ImageAffineTrans, HomMat2D, 'constant', 'false') //进行图像的仿射变换
affine_trans_region (RegionTrans, RegionAffineTrans, HomMat2D, 'nearest_neighbor') //进行区域的仿射变换
*抠图(字符区域中的)。抠图后做灰度化,并用blob分析选择字符区域
reduce_domain (ImageAffineTrans, RegionAffineTrans, ImageReduced) //在字符图像中裁剪出字符区域
rgb1_to_gray (ImageReduced, GrayImage)
threshold (GrayImage, Regions1, 113, 255)
connection (Regions1, ConnectedRegions1)
*对选择字符排序
sort_region (ConnectedRegions1, SortedRegions, 'first_point', 'true', 'row')
*读取模型并显示识别结果
read_ocr_class_mlp ('Industrial_0-9A-Z_NoRej.omc', OCRHandle)
do_ocr_multi_class_mlp (SortedRegions, ImageInvert, OCRHandle, Class, Confidence)
dev_display (Image)
disp_message (WindowHandle, Class, 'window', Row, Column, 'black', 'true')
效果图:
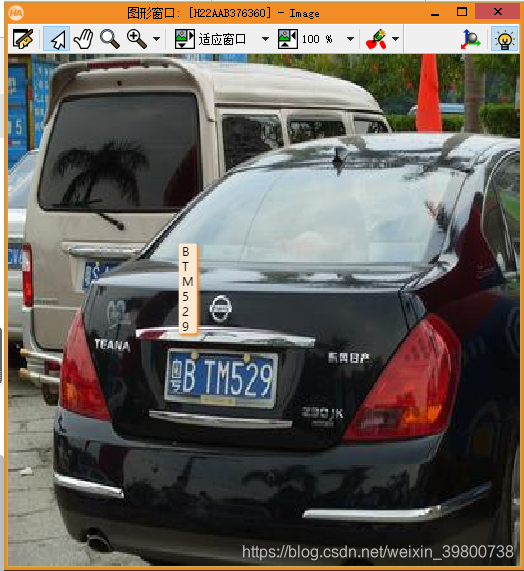
总结:
仿射变换:求角度、面积、中心坐标->求仿射变换原点->求图像的仿射变换->求区域的仿射变换.
这里用到了反色图像,是为了减少图像的环境干扰(我是这么理解的)。
整体思路:采集图像->颜色空间转换->blob分析->形状特征转换->仿射变换->抠图->字符排序->读取模型并显示。
难点在于将车牌部分完整的抠出来以及读取模型。

















 825
825

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









