










 作者因面试中被要求实现DOM树的广度优先遍历算法而受挫,遂整理深度优先和广度优先遍历算法思路。深度优先遍历先深入子孙元素,可借助栈或递归实现;广度优先遍历则像层次遍历,需利用队列先进先出特性。
作者因面试中被要求实现DOM树的广度优先遍历算法而受挫,遂整理深度优先和广度优先遍历算法思路。深度优先遍历先深入子孙元素,可借助栈或递归实现;广度优先遍历则像层次遍历,需利用队列先进先出特性。
一、前言
在面试中,面试官给了个dom树结构:(记不清了,假设是这样)
<div class="d1">
<div class="d2"></div>
</div>
<div class="d3">
<div class="d4"></div>
<div class="d5">
<div class="d6"></div>
</div>
</div>
<span class="s1">
<a class="a1" href=""></a>
</span>
让我实现广度优先遍历算法。当时的我又被自己菜cry了。。。
痛定思痛,现在整理一下这两个算法的思路。
二、深度优先遍历
上述dom树简化后的树状结构如下图所示:(这里以body元素为根节点)
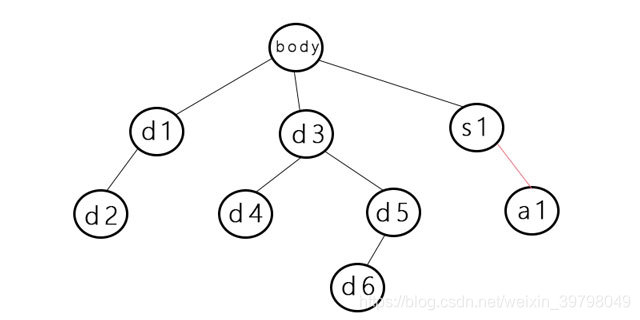
深度优先遍历,顾名思义即是先抓着一个元素一直往下遍历它的子孙元素,直到没有未被遍历的元素时则换下一个元素继续往下遍历。当全部元素都遍历完了就结束。
按照当前树结构来遍历的话就是:
- body -> d1 -> d2
- d3 -> d4
- d5 -> d6
- s1 -> a1
总的遍历顺序为:body -> d1 -> d2 -> d3 -> d4 -> d5 -> d6 -> s1 -> a1
要实现深度优先遍历的话需要用到栈先进后出的特性,当然使用递归也可以的。
function dfc(root){
if(root==null)
return [];
var result = [];//存放遍历结果的数组
var nodeStack = [];//暂存元素的栈
nodeStack.push(root);
while(nodeStack.length>0){
let n = nodeStack.pop();
result.push(n);
let children = n.children;
//要从左到右遍历,所以要反向进栈
for(let i=children.length-1;i>=0;i--){
nodeStack.push(children[i]);
}
}
return result;
}
dfc(document.body);
浏览器中输出为:

三、广度优先遍历
还是这个图
广度优先遍历,和深度不同,它更像是横着去扫描。每次都先遍历当前元素的所有子元素,然后才遍历子元素的所有子元素。
在树型结构中,就像是层次遍历,一层一层地遍历。
要实现广度遍历需要使用队列先进先出的特性
它的遍历过程为:
- body
- d1,d3,s1 (body出队列,三个子元素进队列,现在已进入第二层)----> 已遍历:body
- d3,s1,d2 (d1出队列,d2进队列)----> 已遍历:body,d1
- s1,d2,d4,d5 (d3出队列,d4,d5进队列)----> 已遍历:body,d1,d3
- d2,d4,d5 ,a1(s1出队列,a1进队列,现在已进入第三层)----> 已遍历:body,d1,d3,s1
- ...以此类推
- 队列清空 ----> 已遍历:body,d1,d3,s1,d2,d4,d5,a1,d6
代码如下:
function bfc(root){
if(root==null)
return [];
var result = [];//存放遍历结果的数组
var nodeQueue = [];//暂存元素的队列
nodeQueue .push(root);
while(nodeQueue.length>0){
let n = nodeQueue.shift();
result.push(n);
let children = n.children;
for(let i=0;i<children.length;i++){
nodeQueue.push(children[i]);
}
}
return result;
}
bfc(document.body);
在浏览器中结果为:

和预期结果一样。
完

















 1901
1901

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









