






 本文介绍了在处理信用卡交易数据时,为解决样本不均衡问题,采用下采样策略。通过随机抽取正常样本与异常样本形成新的平衡数据集,接着将数据集切分为训练集、验证集和测试集。使用逻辑回归模型,通过K折交叉验证在下采样数据集上找到最佳模型参数,以召回率为评价指标。最后,观察模型在下采样测试集和原始测试集上的表现,通过混淆矩阵进行评估。
本文介绍了在处理信用卡交易数据时,为解决样本不均衡问题,采用下采样策略。通过随机抽取正常样本与异常样本形成新的平衡数据集,接着将数据集切分为训练集、验证集和测试集。使用逻辑回归模型,通过K折交叉验证在下采样数据集上找到最佳模型参数,以召回率为评价指标。最后,观察模型在下采样测试集和原始测试集上的表现,通过混淆矩阵进行评估。

版权声明:小博主水平有限,希望大家多多指导。本文仅代表作者本人观点。
目录:
BG大龍:【机器学习项目实战01】异常检测——信用卡交易数据检测(上篇)zhuanlan.zhihu.com
1. 【项目背景】
2. 【数据简介】
3.【导入必备的工具包】
4.【数据读取】
5.【数据标签分布】——‘0’类+‘1’类
6.【数据标准化处理】——sklearn处理Amount和Time数据,得到数据集样本分布情况
BG大龍:【机器学习项目实战01】异常检测——信用卡交易数据检测(中篇)zhuanlan.zhihu.com
7. 【下采样方案】根据数据集样本分布情况,提出下采样方案。解决原始数据集样本不均衡,得到一个下采样数据集
8. 【数据集切分】——将‘原始数据集’和‘下采样数据集’切分成训练集+验证集+测试集
9.【交叉验证】调用逻辑回归模型,采用交叉验证方法来评估(本方案使用KFlod)——在下采样的训练集+验证集中找到最好的模型参数
10. 上述‘最好的模型’,观察在‘下采样的测试集’中的表现——混淆矩阵
11.上述‘最好的模型’,观察在‘原始数据的测试集’中的表现——混淆矩阵
BG大龍:【机器学习项目实战01】异常检测——信用卡交易数据检测(下篇)zhuanlan.zhihu.com
12.【原始数据方案】——基于下采样方案的结果,如果直接使用原始数据方案会怎么样?
13.【阈值对结果的影响】
14.【过采样方案】——基于SMOTE算法对异常样本集(正例)进行样本生成,解决原始数据集样本不均衡,得到一个下采样数据集
15.【项目总结】
我们知道在这个数据集中,正负样本的比例极不平衡,现在我们有3个思路。
下采样(数据抽取)、过采样(数据扩充)、直接用原始数据
7. 【下采样方案】——将正常样本(负例)进行样本抽取,解决原始数据集样本不均衡,得到一个下采样数据集
所谓下采样,就是从样本量大的类别中,随机选出与小样本的类别数量相同的样本。
下采样方案=从标签为0的样本(约28万)中,随机选择492个0样本,与已经有的492个标签为1的样本,重新组成数据集。
(0样本——正常样本;1样本——异常样本)
1 分步骤理解代码:
【步骤1】得到Class列的数据集
【步骤2】分别得到492个样本量的‘异常样本索引’+‘随机正常样本索引’
【步骤3】形成下采样数据集,并且分成 X特征数据集、y标签数据集

【步骤1】得到Class列的数据集
##【1】将数据集分类
X = data.iloc[:, data.columns != 'Class']
#iloc[]选取特定的列。
#“:”是指,选取整列。
#data.columns != 是指,将数据集中【列名称】不是‘Class’的选取出来送到X
y = data.iloc[:, data.columns == 'Class']
#同理,data.columns == 是指,将数据集中【列名称】是‘Class’的选取出来送到y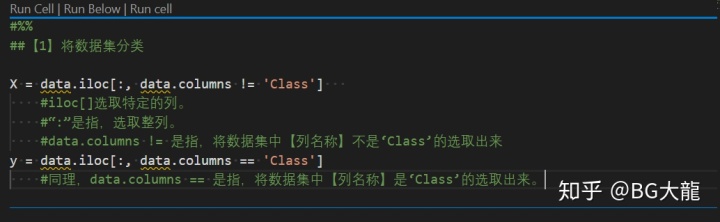
【注解】切片——在Pandas中,有loc()和iloc()用来选取特定的列。
在一个DataFrame数据中,loc根据设置的index来选取对应的列。iloc并不是根据index来索引,而是根据列号来索引,从0开始,逐次加1。 详细内容,我写在答疑博客:BG大龍:【Python答疑】Python怎么选取特定列?—Pandas的iloc、loc使用zhuanlan.zhihu.com

【步骤2】分别得到492个样本量的‘异常样本索引’+‘随机正常样本索引’
##【2】得到异常样本的索引
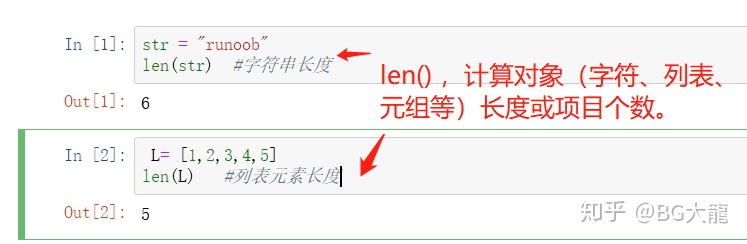
number_records_fraud = len(data[data.Class == 1])
#len()是计算data[]的个数,再将结果送给“异常样本个数”存放
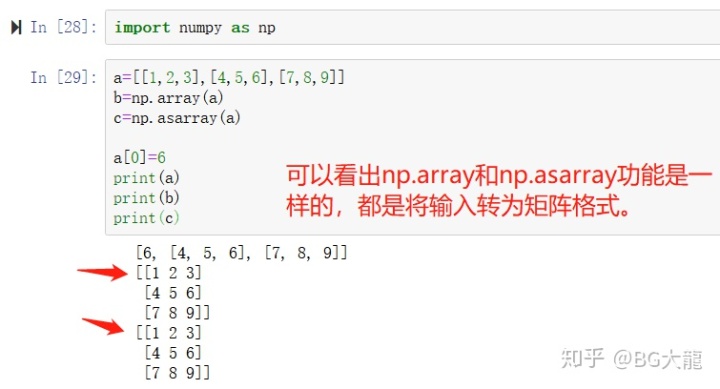
fraud_indices = np.array(data[data.Class == 1].index)
#.index是取data[]的索引地址,np.array将输入转为矩阵格式,再送到“异常样本索引集”存放
##【3】得到正常样本的索引,由于正常样本很多,涉及到随机抽取
normal_indices = data[data.Class == 0].index
#index是取data[]的索引地址,再送到“正常样本索引集”存放
##【4】在正常样本中,随机采样出指定个数的样本(492个),并得到索引
random_normal_indices = np.random.choice(normal_indices, number_records_fraud, replace = False)
#np.random.choice()是指,在正常样本中用随机模块挑选出与异常样本量相同的个数。false指只挑选不替换
random_normal_indices = np.array(random_normal_indices)
#np.array()是指,将输入转换成矩阵形式,然后再送到“随机正常样本索引集”存放
【注解】Python内置函数len()
【注解】np.array()的用处
输入为列表时
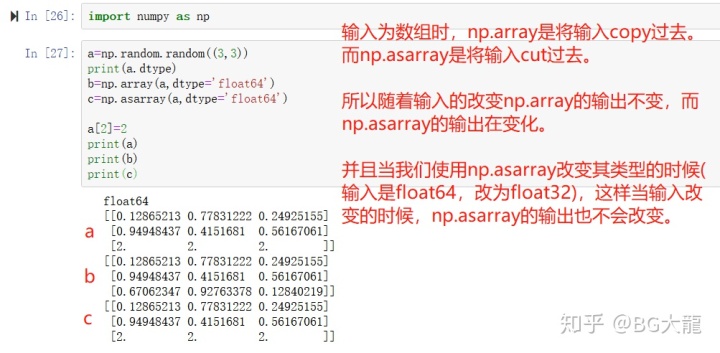
输入为数组时
【步骤3】形成下采样数据集,并且分成 X特征数据集、y标签数据集
##【5】有了正常样本和异常样本后,把它们的索引都拿到手
under_sample_indices = np.concatenate([fraud_indices,random_normal_indices])
#np.concatenate()是数据拼接函数,将“异常样本索引集”和“随机正常样本索引集”拼在一起得到“下采样索引集”
##【6】根据索引得到下采样所有样本点
under_sample_data = data.iloc[under_sample_indices,:]
#data.iloc[]是指,对“下采样索引集”进行切片,选under_sample_indices的所有列
##【7】将下采样数据集分成X、y两类
X_undersample = under_sample_data.iloc[:, under_sample_data.columns != 'Class']
y_undersample = under_sample_data.iloc[:, under_sample_data.columns == 'Class']
##【8】下采样数据集的样本比例
print("正常样本所占整体比例: ", len(under_sample_data[under_sample_data.Class == 0])/len(under_sample_data))
print("异常样本所占整体比例: ", len(under_sample_data[under_sample_data.Class == 1])/len(under_sample_data))
print("下采样策略总体样本数量: ", len(under_sample_data))
【注解】np.concatenate()的使用

详细内容,我写在答疑博客:BG大龍:【Python答疑】Numpy中‘数组拼接’的方法(推荐concatenate)zhuanlan.zhihu.com
【注解】iloc()的使用

2 结果:
从标签为0的样本中,随机选择492个0样本与已经有的492个1样本,重新组成数据集。
解决了样本分布不均衡问题。

8. 【数据集切分】——将‘原始数据集’和‘下采样数据集’切分成训练集+验证集+测试集
为什么要切分?——为了下一步交叉验证
为什么要交叉验证?——可以辅助调参,使模型的评估效果更好。
举个例子,对于一个数据集,我们需要拿出一部分作为训练集(比如 80%)——计算我们需要的参数;需要拿出剩下的样本作为测试集(比如20%)——评估我们的模型的好坏。
但是,
对于训练集,我们也并不是一股脑地拿去训练。
比如把训练集又分成三部分:1,2,3
首先,第 1 部分和第 2 部分作为训练集,第 3 部分作为验证集。
然后,再把第 2 部分和第 3 部分作为训练集,第 1 部分作为验证集。
然后,再把第 1部分和第 3 部分作为训练集,第 2 部分作为验证集。
这就是交叉验证。
1 分步骤理解代码:
【步骤1】原始数据集切分
【步骤2】下采样数据集切分
【步骤1】原始数据集切分
from sklearn.cross_validation import train_test_split
# 对原始数据集进行划分
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size = 0.3, random_state = 0)
print("原始训练集包含样本数量: ", len(X_train))
print("原始测试集包含样本数量: ", len(X_test))
print("原始样本总数: ", len(X_train)+len(X_test))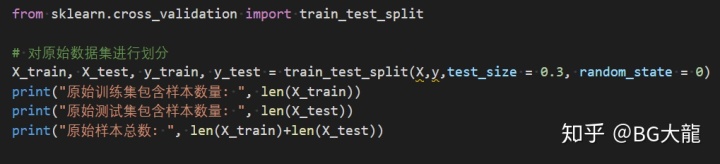
【注解】train_test_split函数
格式:关于python中的随机种子--random_state - simpleDi - 博客园www.cnblogs.com
X_train,X_test, y_train, y_test =cross_validation.train_test_split(train_data,train_target,test_size=0.3, random_state=0) 参数解释:
train_data:被划分的样本特征集
train_target:被划分的样本标签集
test_size:如果是浮点数,在0-1之间,表示样本占比,test_size = 0.3是指按测试集占总体30%的比例划分;如果是整数的话就是样本的数量
random_state:random_state是一个随机种子,划分训练集和测试集的类train_test_split()时,随机种子控制每次划分训练集和测试集的模式。 random_state随机数种子:
其实就是该组随机数的编号,在需要重复试验的时候,保证得到一组一样的随机数。比如你每次都填1,其他参数一样的情况下你得到的随机数组是一样的。但填0或不填,每次都会不一样。
#当random_state取某一个值时,也就确定了一种规则。
详细见该博客:
【注解】原始数据集和下采样数据集,为什么都要进行切分呢?
因为下采样后的数据集是均衡分布,而实际的原始数据集是不均衡分布,用下采样训练+测试不具有代表性。
所以,对数据进行切分的时候,既要对原始数据集进行一定比例的切分,测试时能用到;又要对下采样数据集的样本进行切分,训练的时候用。
而且,切分之前,每次都要进行洗牌。
【步骤2】原始数据集切分
# 对下采样数据集进行划分
X_train_undersample, X_test_undersample, y_train_undersample, y_test_undersample = train_test_split(X_undersample
,y_undersample
,test_size = 0.3
,random_state = 0)
print("")
print("下采样训练集包含样本数量: ", len(X_train_undersample))
print("下采样测试集包含样本数量: ", len(X_test_undersample))
print("下采样样本总数: ", len(X_train_undersample)+len(X_test_undersample))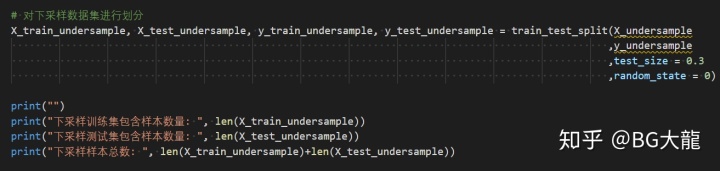
2结果:
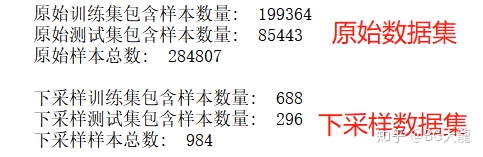
19【交叉验证】调用逻辑回归模型,采用交叉验证方法来评估(本方案使用KFlod)——在下采样的训练集+验证集中找到最好的模型参数
先说2个概念:召回率+正则化
第1个概念:召回率——评价模型的效果
召回率 Recall,是覆盖面的度量。可以看到召回率与灵敏度是一样的。
1 计算公式:Recall = TP/(TP+FN)。
2 引入四个小定义:TP、TN、FP、FN
“____(正确/错误)地判断成____(正/负)例”,用这样一句话去理解很简单。
TP,即 True Positive =正确地判断成正例
TN,即 True negative=正确地判断成负例
FP,即False Positive =错误地判断成正例
FN ,即False negative =错误地判断成负例
参考:机器学习算法中的准确率(Precision)、召回率(Recall)、F值(F-Measure)机器学习算法中的准确率(Precision)、召回率(Recall)、F值(F-Measure) - Zhi-Z - 博客园www.cnblogs.com
第2个概念:正则化——为了提高模型的泛化能力
许多正则化方法,通过对目标函数 J 添加惩罚项。
惩罚项=惩罚系数
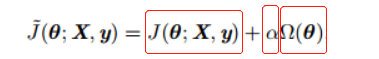
惩罚系数α,也称惩罚力度
惩罚函数——正则项L1、L2
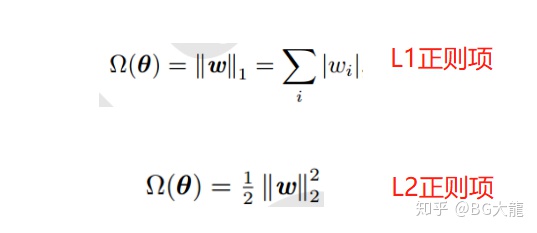
对于神经网络中,参数通常是包括权重w和偏置项b,而我们通常对w做惩罚而不对偏置b做处理。

参考:对于正则化的理解 - 禅在心中 - 博客园对于正则化的理解 - 禅在心中 - 博客园www.cnblogs.com
1 分步骤理解代码
【步骤1】导入工具包
【步骤2】编写Kflod函数,打印“正则化惩罚力度c_param”
【步骤3】5次迭代“正则化惩罚系数c_param”后,计算每一次迭代的召回率,并打印出来
【步骤4】找到best_c,使得召回率Recall最高
【步骤1】导入工具包
#【1】导入工具包
from sklearn.linear_model import LogisticRegression
#在sklearn库的线性模块中,调取“逻辑回归”
from sklearn.cross_validation import KFold, cross_val_score
#交叉验证模块中,选用“K折交叉验证”。
#cross_val_score函数返回的是一个使用交叉验证以后的评分标准。可以通过交叉验证评估分数,非常方便。
from sklearn.metrics import confusion_matrix,recall_score,classification_report
#混淆矩阵、召回率
#sklearn中的classification_report函数用于显示主要分类指标的文本报告,在报告中显示每个类的精确度,召回率,F1值等信息。
from sklearn.model_selection import cross_val_predict
#cross_val_predict 和 cross_val_score的使用方法是一样的,但是它返回的是一个使用交叉验证以后的输出值,而不是评分标准。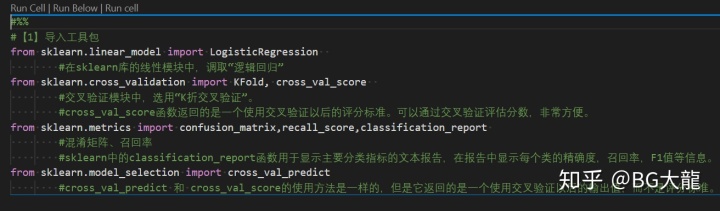
【注解】cross_val_score ——对数据集进行指定次数的交叉验证并为每次验证效果评测
其中,score 默认是以 scoring='f1_macro’进行评测的,此外针对分类或回归还有:
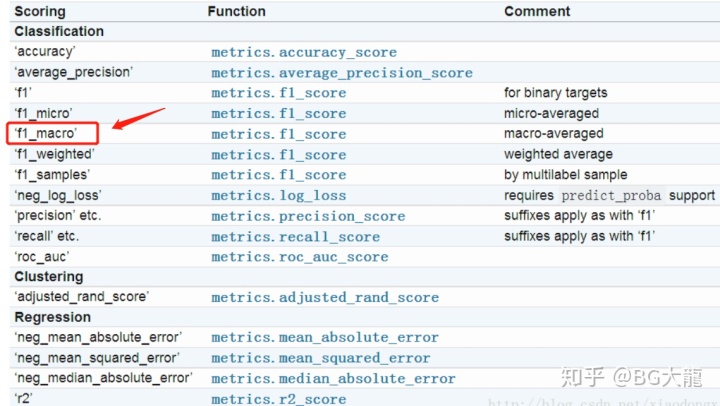
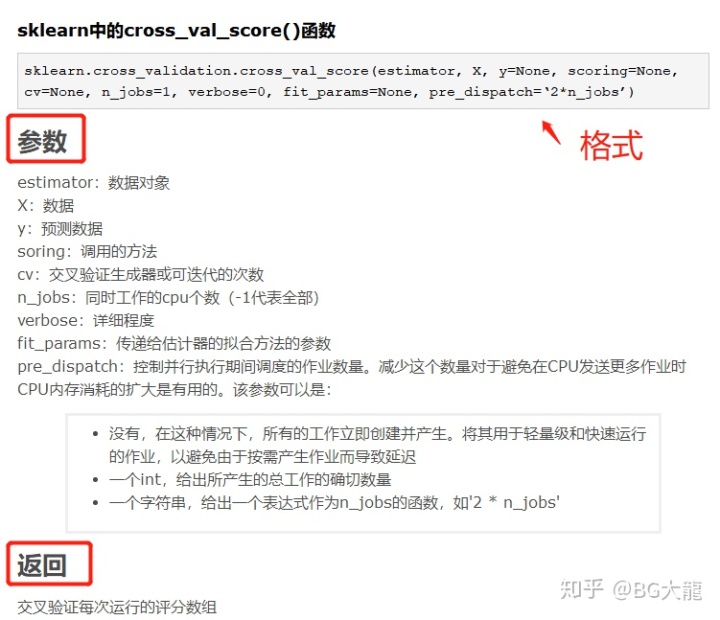
【注解】sklearn.metrics
sklearn中的模型评估模块,用于构建评估函数/选定评估方法,这里选的是召回率recall
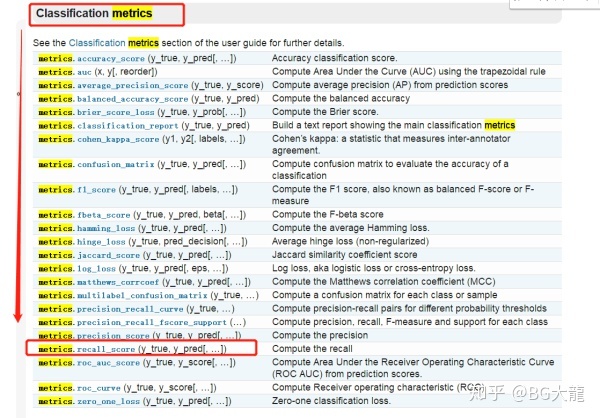
【注解】classification_report

【注解】cross_val_predict
cross_val_predict 与cross_val_score 很相像,不过不同于返回的是评测效果,cross_val_predict 返回的是estimator 的分类结果(或回归值)。
这个对于后期模型的改善很重要,可以通过该预测输出对比实际目标值,准确定位到预测出错的地方,为参数优化及问题排查提供方便。
【步骤2】编写Kflod函数,打印“正则化惩罚力度c_param”
#【2】编写Kflod函数——printing_Kfold_scores,实际中我们可以直接调用
def printing_Kfold_scores(x_train_data,y_train_data):
fold = KFold(len(y_train_data),5,shuffle=False) #shuffle=False是指数据集不用洗牌
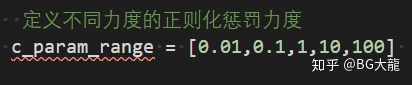
# 【2.1】定义不同力度的正则化惩罚力度
c_param_range = [0.01,0.1,1,10,100]
# 【2.2】展示结果用的表格
results_table = pd.DataFrame(index = range(len(c_param_range),2), columns = ['C_parameter','Mean recall score'])
results_table['C_parameter'] = c_param_range
# 【2.3】k-fold 表示K折的交叉验证,这里会得到两个索引集合: 训练集 = indices[0], 验证集 = indices[1]
j = 0
# 【2.4】循环遍历不同的参数(这里的c_param_rang是5个——5折交叉验证)
for c_param in c_param_range:
print('-------------------------------------------')
print('正则化惩罚力度: ', c_param)
print('-------------------------------------------')
print('')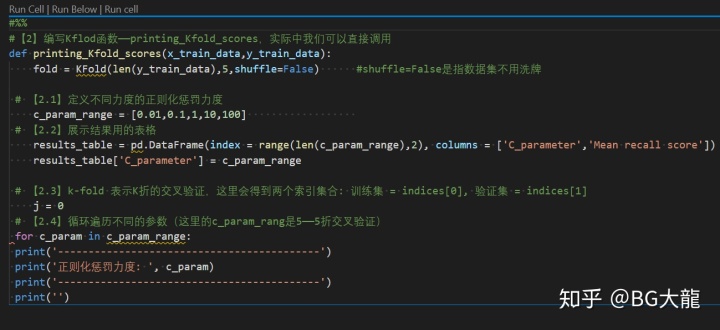
【注解】range()函数
【注解】K折交叉验证——KFold()
K折交叉验证,这是将数据集分成K份的官方给定方案,所谓K折就是将数据集通过K次分割,使得所有数据既在训练集出现过,又在测试集出现过,当然,每次分割中不会有重叠。
相当于无放回抽样。
详细介绍请见:
使用sklearn进行交叉验证 - 小舔哥 - 博客园www.cnblogs.com
【步骤3】5次迭代“正则化惩罚系数c_param”后,计算每一次迭代的召回率,并打印
#【3】计算每一次迭代后的召回率,一次5次
recall_accs = []
#一步步分解来执行交叉验证
for iteration, indices in enumerate(fold,start=1):
# 选择算法模型+给定参数
lr = LogisticRegression(C = c_param, penalty = 'l1') #L1正则化防止过拟合,通过k折交叉验证寻找最佳的参数C。
# 训练模型。注意索引不要给错了,训练的时候一定传入的是训练集,所以X和Y的索引都是0
lr.fit(x_train_data.iloc[indices[0],:],y_train_data.iloc[indices[0],:].values.ravel())
# 测试模型。这里用验证集预测模型结果,这里用的就是验证集,索引为1,验证集 = indices[1]
y_pred_undersample = lr.predict(x_train_data.iloc[indices[1],:].values)
# 评估模型。有了预测结果之后就可以来进行评估了,这里recall_score需要传入预测值和真实值。
recall_acc = recall_score(y_train_data.iloc[indices[1],:].values,y_pred_undersample)
# 一会还要算平均,所以把每一步的结果都先保存起来。
recall_accs.append(recall_acc)
print('Iteration ', iteration,': 召回率 = ', recall_acc)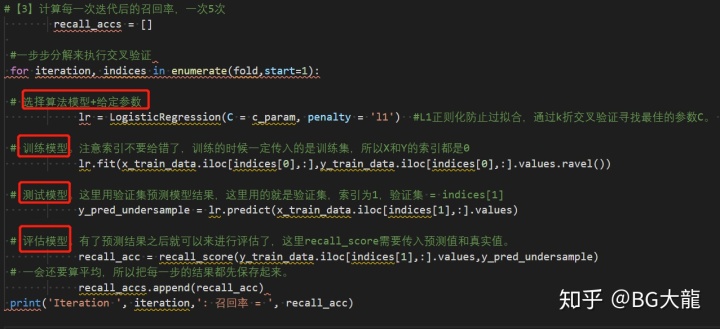
【注解】enumerate()
用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
【注解】LogisticRegression中的C参数——越小的C值,有着越大的惩罚力度

【注解】fit()——求得训练集X的均值,方差,最大值,最小值,这些训练集固有的属性。
相对于整个代码而言,fit是为后续的API函数服务的。
【注解】ravel()——将多维数组转换为一维数组。
之所以会关注这个,是因为,在sklearn.linear_model.LogisticRegression()应该过程中fit(X,Y)时,Y没有用ravel()出现warrning。——发现fit()的Y是多维数组:fit(X, y, sample_weight=None)
【注解】append()—— 用于向列表末尾追加指定元素
【步骤4】找到best_c,使得Recall最高
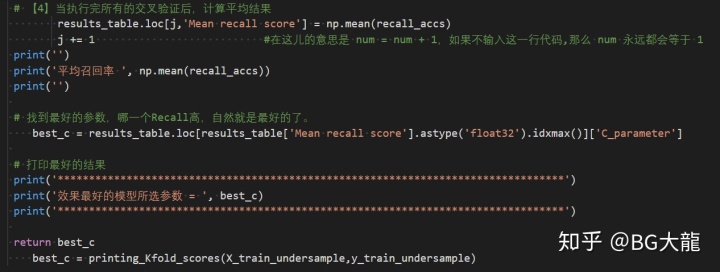
# 【4】当执行完所有的交叉验证后,计算平均结果
results_table.loc[j,'Mean recall score'] = np.mean(recall_accs)
j += 1 #在这儿的意思是 num = num + 1,如果不输入这一行代码,那么 num 永远都会等于 1
print('')
print('平均召回率 ', np.mean(recall_accs))
print('')
# 找到最好的参数,哪一个Recall高,自然就是最好的了。
best_c = results_table.loc[results_table['Mean recall score'].astype('float32').idxmax()]['C_parameter']
# 打印最好的结果
print('*********************************************************************************')
print('效果最好的模型所选参数 = ', best_c)
print('*********************************************************************************')
return best_c
best_c = printing_Kfold_scores(X_train_undersample,y_train_undersample)
【注解】mean()

【注解】astype()
Python中与数据类型相关函数及属性有如下三个:type、dtype、astype
type() ——返回参数的数据类型
dtype()——返回数组中元素的数据类型
astype() ——返回对数据类型进行转换
【注解】idxmax()——返回最大值的索引


2 结果:
效果最好的模型参应该是0.01

10. 上述‘最好的模型’,观察在‘下采样的测试集’中的表现——混淆矩阵
1个概念:混淆矩阵——评判模型结果的指标,属于模型评估的一部分
一句话解释:
分别统计分类模型归错类,归对类的观测值个数,然后把结果放在一个表里展示出来。这个表就是混淆矩阵
应用:
混淆矩阵多用于判断分类器(Classifier)的优劣。
适用于分类型的数据模型——如分类树(Classification Tree)、逻辑回归(Logistic Regression)、线性判别分析(Linear Discriminant Analysis)等方法。
1 分步骤理解代码
【步骤1】画出混淆矩阵(模板,用的时候直接复制)
【步骤2】通过混淆矩阵,观察‘最好的模型’在‘下采样的测试集’中的表现
【步骤1】混淆矩阵(模板,用的时候直接复制)
def plot_confusion_matrix(cm, classes,
title='Confusion matrix',
cmap=plt.cm.Blues):
"""
绘制混淆矩阵
"""
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=0)
plt.yticks(tick_marks, classes)
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j],
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')【步骤2】通过混淆矩阵,观察‘最好的模型’在‘下采样的测试集’中的表现
import itertools
# 输入参数
lr = LogisticRegression(C = best_c, penalty = 'l1')
# 训练模型
lr.fit(X_train_undersample,y_train_undersample.values.ravel())
# 测试模型
y_pred_undersample = lr.predict(X_test_undersample.values)
# 计算所需值
cnf_matrix = confusion_matrix(y_test_undersample,y_pred_undersample)
np.set_printoptions(precision=2)
print("召回率: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
# 绘制
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Confusion matrix')
plt.show()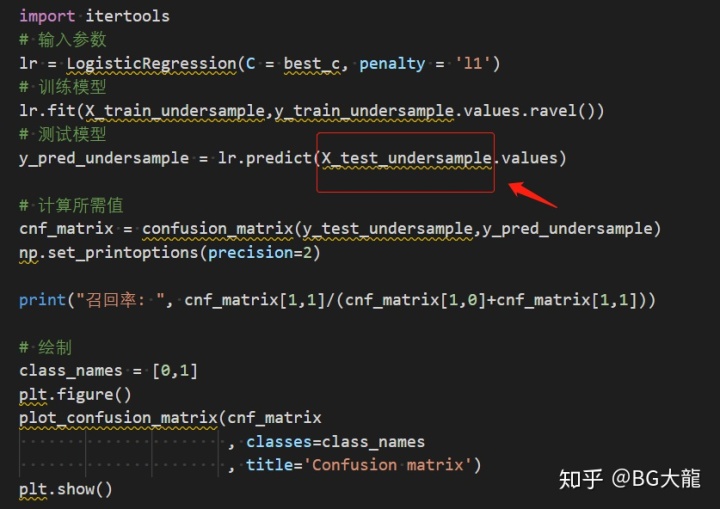
【注解】Python的内建模块 itertools——用于操作迭代对象的函数https://docs.python.org/3.7/library/itertools.htmldocs.python.org
参考:
itertools - 为高效循环创建迭代器的函数 - Python 3.7.4文档
【注解】fit()——在数据预处理中,求得训练集的均值,方差,最大值,最小值……,这些训练集固有的属性https://blog.youkuaiyun.com/weixin_38278334/article/details/82971752blog.youkuaiyun.com
fit()是为计算该类处理所需的相关参数,以标准化为例,fit()就是计算标准化所用到的均值与方差
transform()函数则是利用fit()的结果作为参数对数据进行相应的处理,比如正规化
fit_transform()就是先调用fit(),后调用transform()
参考:
fit_transform,fit,transform区别和作用详解
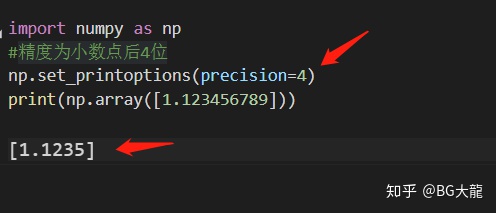
【注解】np.set_printoptions(precision=2)—— 确定浮点数字、数组、和numpy对象的显示形式。
2 结果:
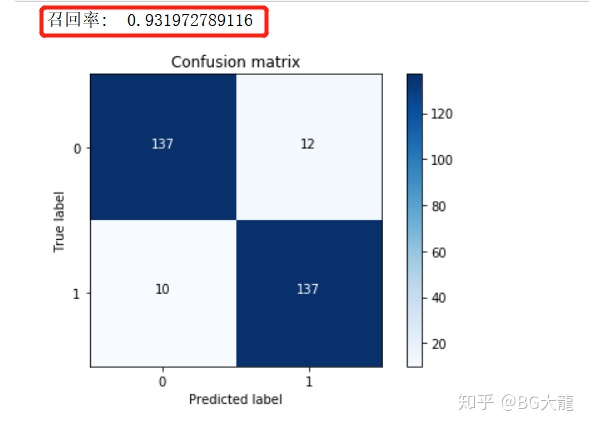
召回率:

准确率:

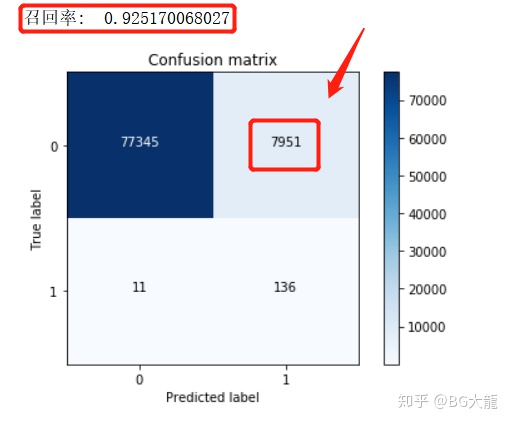
11.上述‘最好的模型’,在‘原始数据的测试集’中的表现——混淆矩阵
# 输入参数
lr = LogisticRegression(C = best_c, penalty = 'l1')
# 训练模型
lr.fit(X_train_undersample,y_train_undersample.values.ravel())
# 测试模型
y_pred = lr.predict(X_test.values)
# 计算所需值
cnf_matrix = confusion_matrix(y_test,y_pred)
np.set_printoptions(precision=2)
print("召回率: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
# 绘制
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Confusion matrix')
plt.show()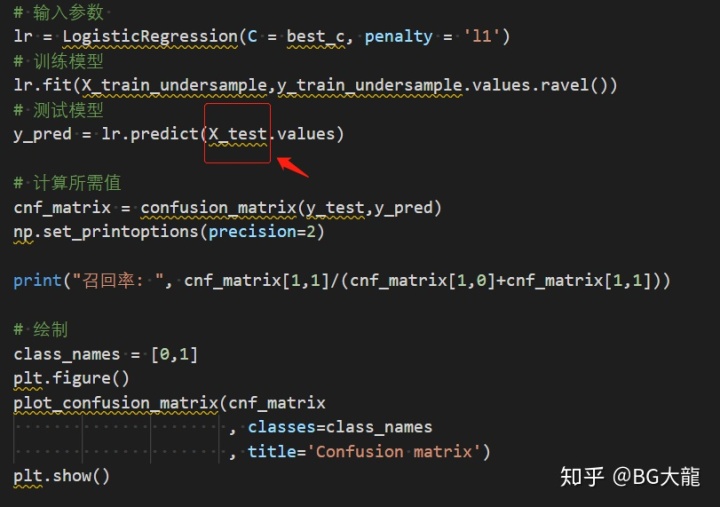
2 结果:
有一个问题,7951个样本是正常的,结果被检测成异常
未完,请见(下篇)……
参考:
1、信用卡欺诈案例(终结) - stranger_man的博客 - 优快云博客
https://blog.youkuaiyun.com/stranger_man/article/details/79055095blog.youkuaiyun.com2、【迪哥有点愁】唐宇迪的机器学习博客 - 优快云博客
https://blog.youkuaiyun.com/tangyudi?t=1blog.youkuaiyun.com
3、python 机器学习实战:信用卡欺诈异常值检测 - denghe优快云的博客 - 优快云博客


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









