 SQL基础教程
SQL基础教程










 本文详细介绍了SQL语言的基础知识,包括数据定义、数据操作、数据控制和数据查询等方面,涵盖了数据库表的创建、数据的增删改查、条件筛选、聚合函数应用及分组查询等内容。
本文详细介绍了SQL语言的基础知识,包括数据定义、数据操作、数据控制和数据查询等方面,涵盖了数据库表的创建、数据的增删改查、条件筛选、聚合函数应用及分组查询等内容。
【数据库】
数据库是存储数据的仓库,本质是一个文件系统,将数据按照特定的格式存储起来,使用户可以对数据库中的数据进行增加、删除、修改和查询。
【数据库管理系统】
数据库管理系统(DataBase Management System,DBMS)是指一种操作和管理数据库的大型软件,用于建立、使用和维护数据库,对数据库进行统一管理和控制,以保证数据库的安全和完整性。用户通过数据库管理系统访问数据库中表内的数据。与java相关的数据库管理系统:MySQL、Oracle
【数据库表】
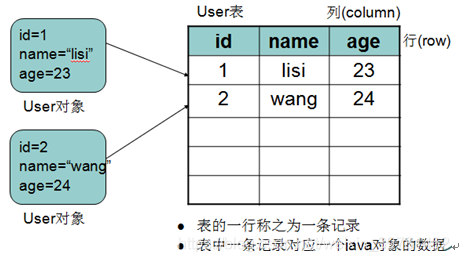
数据库中以表为组织单位存储数据,表类似于java中的类(字段类似于类中属性),有以下对应关系:
【DOS命令下】
启动服务 > net start mysql
停止服务 > net stop mysql
登录MySQL :格式1 > mysql -u用户名 -p密码 例如:mysql -uroot -p123
格式2 > mysql --host=ip地址 --user用户名 --password=密码
命令行中中文乱码问题:Windows命令行中的编码表是GBK, MySQL中的是UTF-8,使用set names 'gbk';设置成GBK格式
【SQL语句】
(1)数据定义语言:简称DDL(Data Definition Language),用来定义数据库对象:数据库,表,列等 关键字creat、alter、drop等。
1)创建数据库格式:create database 数据库名;(不要忘记分号)
create database 数据库名 character 字符集;
2)删除数据库: drop database 数据库名;
3)删除表:drop table 表名;
4)查看MySQL数据库中的所有数据库:show databases;
5)查看库中所有的表: show tables;
6)查看某个数据库的定义的信息:show create database 数据库名;
7)查看表结构:desc 表名;
8)创建表: create table 表名(列名1 数据类型 约束, 列名2 数据类型 约束, 列名3 数据类型 约束 ); 约束可以设置为 主键约束 primary key 保证列数据的唯一性,非空性;primary key AUTO_INCREMENT 让主键数据实现自动增长。
-- 创建一个商品数据表
CREATE TABLE users1(
-- 商品编号 主键列 可自动增长
id INT PRIMARY KEY AUTO_INCREMENT,
-- 商品的名字
pname VARCHAR(100) NOT NULL,
-- 商品的价格
price DOUBLE
);
-- 删除主键 ALTER TABLE users1 DROP PRIMARY KEY;
-- 添加列 (alter table 表名 add 列名 数据类型 约束;)
ALTER TABLE users ADD tel INT ;
-- 修改列 在原有列上修改(alter table 表名 modify 列名 数据类型 约束 )
ALTER TABLE users MODIFY uname VARCHAR(30);
-- 修改列名 (alter table 表名 change 旧列名 新列名 数据类型 约束;)
ALTER TABLE users CHANGE tel newtel DOUBLE;
-- 删除列 (alter table 表名 drop 列名;)
ALTER TABLE users DROP newtel;
-- 修改表的字符集
ALTER TABLE users1 CHARACTER SET gbk;
-- 修改表名 (rename table 表名 to 新名;)
RENAME TABLE users TO user1;
-- 查看表结构
DESC users;
(2)数据操作语言:简称DML(Data Manipulation Language),用来对数据库中表的记录进行更新,关键字insert、delete、updata
1)向数据表添加数据。insert into 表名 (列名) values (值); 注意表的编码格式
-- 方式1. 向商品数据表中添加数据
INSERT INTO users1 (id,pname,price) VALUES (1,'笔记本',8999.89);
-- 方式2. 不考虑主键
INSERT INTO users1 (pname,price) VALUES ('洗衣机',790);
-- 方式3.
INSERT INTO users1 VALUES (3,'智能手机',2999);
-- 方式4. 批量写入数据
INSERT INTO users1 (pname,price) VALUES
('智能机器人',12111),('运动鞋',1212),('路虎',500000);
2)对数据进行更新操作。格式:update 表名 set 列1=值1, 列2=值2 where 条件 (条件--数据中的唯一性)
-- 修改路虎的价格 上调到600000
UPDATE users1 SET price=600000 WHERE id=6;
-- 修改运动鞋为耐克 价格变为2000
UPDATE users1 SET pname='耐克',price=2000 WHERE id=5;
/*
修改条件的写法
id=6 id等于6 id<>6 id不等于6 id<=6 id小于等于6
and 与 or 或 not 非
*/
-- 将id=1笔记本和id=2洗衣机的价格全部改为4000
UPDATE users1 SET price=4000 WHERE id=1 OR id=2;
UPDATE users1 SET price=3000 WHERE id IN (1,2);
3)删除表中数据。格式:delete from 表名 where 条件
-- 删除数据(有条件) 格式:delete from 表名 [where 条件]
DELETE FROM users1 WHERE id=3; -- 不清空对应的auto_increment记录数
-- 删除表中所有数据
-- 格式:truncate table 表名 truncate 直接将表删除,重新建表 auto_increment将置0,重新开始
被删除的数据所占的空间会被立即释放,数据不可恢复。
-- 格式:delete from 表名 delete 一条一条的删除,不清空auto_increment记录数。被删除数
据占用的空间不会被立即释放,数据可恢复。
(3)数据控制语言:简称DCL(Data Contral Language),用来定义数据库的访问权限和安全级别,及创建用户
(4)数据查询语言:简称DQL(Data Query Language),用来查询数据中表的记录。关键字select,from,where等
-- 1.查询指定列的数据 格式:select 列名1,列名2 from 表名
SELECT zname FROM zhanghu;
-- 2.查询表中所有数据 格式:select * from 表名
SELECT * FROM zhanghu;
-- 3.查询去掉重复记录
SELECT DISTINCT zname FROM zhanghu;
-- 4.查询临时重新命名列
SELECT zname AS 'name' FROM zhanghu;
-- 5.查询数据中,直接进行数据计算 将zmoney列 加1 临时命名为sum
SELECT zname,zmoney+10000 AS 'sum' FROM zhanghu;
【条件查询】
where 语句表条件过滤。满足条件操作,不满足条件不操作。多用于数据的查询与修改。
格式:select 字段 from 表名 where 条件;
| 比较运算符 | > < <= >= <> | 大于、小于、小于等于、大于等于、不等于 |
| between ... and ... | 显示在某一区间的值(包头包尾) | |
| in(set) | 显示在in列表中的值 | |
| like 通配符 | 模糊查询,like语句中有两个通配符 | |
| % 用来匹配多个字符 | ||
| _ 用来匹配一个字符 | ||
| is null | ||
| is null; 判断为空 | ||
| is not null ; 判断不为空 | ||
| 逻辑运算符 | and | 多个条件同时成立 |
| or | 多个条件任一成立 | |
| not | 不成立 |
-- 查询所有的吃饭支出
SELECT * FROM zhanghu WHERE zname='吃饭支出';
-- 查询金额大于10000
SELECT * FROM zhanghu WHERE zmoney>10000;
-- 查询金额在50000到100000之间 包头包尾
SELECT * FROM zhanghu WHERE zmoney >= 50000 AND zmoney <= 100000;
-- 改进 使用 between and
SELECT * FROM zhanghu WHERE zmoney BETWEEN 50000 AND 100000;
-- 查询金额是 1000 2000 3000 其中一个
SELECT * FROM zhanghu WHERE zmoney=1000 OR zmoney=2000 OR zmoney=3000;
-- 改造成in方法
SELECT * FROM zhanghu WHERE zmoney IN (1000,2000,3000);
-- like 模糊查询 配合通配符使用
-- 查询所有支出
SELECT * FROM zhanghu WHERE zname LIKE '%支出%';
-- 查询账户名称为5个字符的
SELECT * FROM zhanghu WHERE zname LIKE '_____';
-- 查询账户名不为空
SELECT * FROM zhanghu WHERE zname IS NOT NULL;
-- 查询 对结果集进行排序
-- order by 列名 desc\asc desc 降序 asc 升序
-- 查询账务表 价格进行升序
SELECT * FROM zhanghu ORDER BY zmoney;
-- 查询账务表 价格进行降序
SELECT * FROM zhanghu ORDER BY zmoney DESC;
-- 查询账务表 查询所有的支出 对金额进行降序排序
-- 先过滤条件 再对结果进行排序
SELECT * FROM zhanghu WHERE zname LIKE '%支出%' ORDER BY zmoney DESC;
【聚合函数】
-- 使用聚合函数 进行查询计算 返回一个单一的值
-- count 统计指定列不为null 的记录行数 count(列名)
-- 查询账务表中一共有多少条数据
SELECT COUNT(*) FROM zhanghu;
-- sum求和 ,对一列中的所有数据进行求和计算 sum(列名)
-- 对财务表进行查询,对所有的金额进行求和计算
SELECT SUM(zmoney) FROM zhanghu;
-- 统计所有支出的总金额
SELECT SUM(zmoney) FROM zhanghu WHERE zname LIKE '%支出%';
-- max 获取某一列的最大值
-- 获取金额的最大值
SELECT MAX(zmoney) FROM zhanghu;
-- avg 计算某一列的平均数
SELECT AVG(zmoney) FROM zhanghu;
【分组查询】
-- 分组查询:group by 被分组的列名 必须跟随聚合函数
-- select 查询金额时候 被分组的列 ,要出现在select 选择列的后面
SELECT SUM(zmoney),zname FROM zhanghu GROUP BY zname;
-- 对zname内容进行分组查询求和(zname相同的,为一组),但只要支出的和 再对和进行降序
SELECT SUM(zmoney) AS 'getsum',zname FROM zhanghu WHERE zname LIKE '%支出%'
GROUP BY zname
ORDER BY getsum DESC;
-- 分组后进行过滤 显示金额大于50000的
-- where 过滤行 having过滤分组
SELECT SUM(zmoney) AS 'getsum',zname FROM zhanghu WHERE zname LIKE '%支出%'
GROUP BY zname HAVING getsum > 50000;
【总结】
(1)SQL语句可以单行或多行书写,以分号结尾
(2)可使用空格和缩进增强语句的可读性
(3)MySQL数据库中的SQL语句不区分大小写,关键字建议大写
(4)同样可以使用/**/来进行注释
(5)MySQL中常用的数据类型如下:
| 类型 | 描述 |
| int | 整型 |
| double | 浮点型 |
| varchar | 字符串型 |
| date | 日期类型,格式:yyyy-MM--dd 只有年月日,没有时分秒 |
(6)varchar(10) 与char(10) 的区别?
varchar 长度可变,char(10)长度不可变。若都存储"abc",varchar(10)长度为3;char(10)长度为10,后面有7个空格。
在SQLyog中向表中插入数据时中文乱码问题:
利用此语句查看:
表的默认字符集和排序规则为: utf8 & utf8_general_ci
SHOW FULL COLUMNS FROM t_pain_point_status_report;
若不是,利用以下语句进行修改:
ALTER TABLE t_pain_point_status_report CHANGE current_progress current_progress VARCHAR(1000) CHARACTER SET utf8 COLLATE utf8_general_ci;
ALTER TABLE t_pain_point_status_report CHANGE pain_point_id pain_point_id VARCHAR(20) CHARACTER SET utf8 COLLATE utf8_general_ci;

















 1283
1283

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









