





 本文对Mask-RCNN技术进行解析,它在Faster-RCNN基础上添加分支网络,实现目标检测与像素分割。介绍了其特点,如训练简单、可扩展到其他任务等。阐述技术要点,包括强化基础网络、ROIAlign、Loss Function。还给出对比实验效果及在姿态估计上的扩展。
本文对Mask-RCNN技术进行解析,它在Faster-RCNN基础上添加分支网络,实现目标检测与像素分割。介绍了其特点,如训练简单、可扩展到其他任务等。阐述技术要点,包括强化基础网络、ROIAlign、Loss Function。还给出对比实验效果及在姿态估计上的扩展。
Mask-RCNN技术解析
MaskR-CNN
论文链接:https://arxiv.org/pdf/1703.06870.pdf
代码链接:https://github.com/CharlesShang/FastMaskRCNN
摘要
提出了一个概念简单,灵活,通用的对象实例分割框架。本方法有效地检测图像中的对象,同时为每个实例生成高质量的分割掩码。该方法称为Mask R-CNN,通过在已有的包围盒识别分支的基础上增加一个预测对象掩模的分支,使R-CNN扩展得更快。Mask R-CNN训练简单,仅为速度更快的R-CNN增加少量开销,运行速度为5 fps。此外,Mask R-CNN易于推广到其他任务,例如,允许在相同的框架中估计人体姿势。展示了COCO系列挑战的所有三个轨迹的最佳结果,包括实例分割、包围盒对象检测和人的关键点检测。不需要经过修饰,Mask R-CNN在每一项任务上都胜过所有现有的单模式参赛作品,包括COCO 2016挑战赛的获胜者。简单有效的方法将作为一个坚实的基线,并有助于在实例级识别的未来研究。
一. Mask-RCNN 介绍
Mask-RCNN,看着比较好理解,就是在 RCNN 的基础上添加 Mask。
Mask-RCNN 来自于Facebook的 Kaiming He,通过在 Faster-RCNN 的基础上添加一个分支网络,在实现目标检测的同时,把目标像素分割出来。
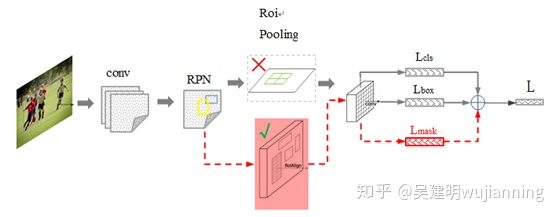
假设大家对 Faster 已经很熟悉了,其中,黑色部分为原来的 Faster-RCNN,红色部分为在 Faster网络上的修改
1)将 Roi Pooling 层替换成了 RoiAlign;
2)添加并列的 FCN 层(mask 层);
Mask-RCNN 的几个特点
1)在边框识别的基础上添加分支网络,用于 语义Mask 识别;
2)训练简单,相对于 Faster 仅增加一个小的 Overhead,可以跑到 5FPS;
3)可以方便的扩展到其他任务,比如人的姿态估计 等;
4)不借助 Trick,在每个任务上,效果优于目前所有的 single-model entries;包括 COCO 2016 的Winners。
二. Mask-RCNN 技术要点
Mask R-CNN基本结构:与Faster RCNN采用了相同的two-state步骤:首先是找出RPN,然后对RPN找到的每个RoI进行分类、定位、并找到binary mask。这与当时其他先找到mask然后在进行分类的网络是不同的。
● 技术要点1 - 强化的基础网络
通过 ResNeXt-101+FPN 用作特征提取网络,达到 state-of-the-art 的效果。
● 技术要点2 - ROIAlign
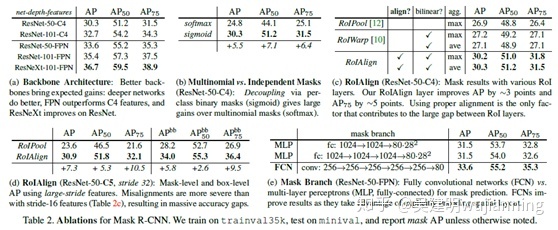
采用 ROIAlign 替代 RoiPooling(改进池化操作)。引入了一个插值过程,先通过双线性插值到14*14,再 pooling到7*7,很大程度上解决了仅通过 Pooling 直接采样带来的 Misalignment 对齐问题。
虽然 Misalignment 在分类问题上影响并不大,但在 Pixel 级别的 Mask 上会存在较大误差。
后面把结果对比贴出来(Table2 c & d),能够看到 ROIAlign 带来较大的改进,可以看到,Stride 越大改进越明显。
● 技术要点3 - Loss Function
每个 ROIAlign 对应 K * m^2 维度的输出。K 对应类别个数,即输出 K 个mask,m对应 池化分辨率(7*7)。Loss 函数定义:
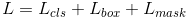
Lmask(Cls_k) = Sigmoid (Cls_k),平均二值交叉熵 (average binary cross-entropy)Loss,通过逐像素的 Sigmoid 计算得到。
Why 有K个mask?通过对每个 Class 对应一个 Mask 可以有效避免类间竞争(其他 Class 不贡献 Loss )。
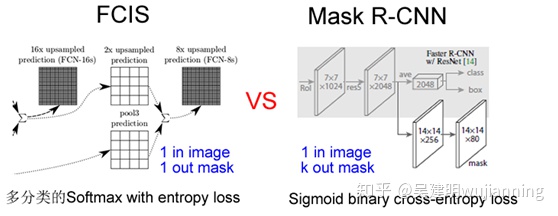
通过结果对比来看(Table2 b),也就是作者所说的 Decouple 解耦,要比多分类 的 Softmax 效果好很多。
三. 对比实验效果
Training:
1.当IoU与Ground Truth的IoU大于0.5时才会被认为有效的RoI,只把有效RoI计算进去。
2.采用image-centric training,图像短边resize到800,每个GPU的mini-batch设置为2,每个图像生成N个RoI,对于C4 backbone的N=64,对于FPN作为backbone的,N=512。使用了8块GPU,所以总的minibatch是16,迭代了160k次,初始lr=0.02,在迭代到120k次时,将lr设定到 lr=0.002,另外学习率的weight_decay=0.0001, momentum = 0.9。如果是resnext,初始lr=0.01,每个GPU的mini-batch是1。
3.RPN的anchors有5种scale,3种ratios。为了方便剥离、如果没有特别指出,则RPN网络是单独训练的且不与Mask R-CNN共享权重。RPN和Mask R-CNN使用一个backbone,所以他们的权重是共享的。
(Ablation Experiments 为了方便研究整个网络中哪个部分其的作用到底有多大,需要把各部分剥离开)
Inference: 在测试时,使用C4 backbone情况下proposal number=300,使用FPN时proposal number=1000。然后在这些proposal上运行bbox预测,接着进行非极大值抑制。mask分支只应用在得分最高的100个proposal上。顺序和train是不同的,但这样做可以提高速度和精度。mask 分支对于每个roi可以预测k个类别,只要背景和前景两种,所以只用k-th mask,k是根据分类分支得到的类型。然后把k-th mask resize成roi大小,同时使用阈值分割(threshold=0.5)二值化。
另外,给出了很多实验分割效果,下面是一张 和 FCIS 的对比图(FCIS 出现了Overlap 的问题):

四. Mask-RCNN 扩展
Mask-RCNN 在姿态估计上的扩展,效果不错。


















 999
999

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









