






 本文介绍了如何使用Python实现WebSocket爬虫抓取斗鱼直播间的弹幕和礼物消息。通过分析斗鱼的通讯协议,编写编码解码函数,抓包分析获取服务器地址,实现与服务器的交互。示例代码展示了登录、心跳、弹幕和礼物消息的处理,以及如何开启或屏蔽礼物消息。最后,通过`websocket-client`库建立WebSocket连接,监听并解析实时消息。
本文介绍了如何使用Python实现WebSocket爬虫抓取斗鱼直播间的弹幕和礼物消息。通过分析斗鱼的通讯协议,编写编码解码函数,抓包分析获取服务器地址,实现与服务器的交互。示例代码展示了登录、心跳、弹幕和礼物消息的处理,以及如何开启或屏蔽礼物消息。最后,通过`websocket-client`库建立WebSocket连接,监听并解析实时消息。
1.斗鱼弹幕协议
到斗鱼官方开放平台看斗鱼通讯协议,网址“https://open.douyu.com/source/api/63”,登录后可查看

所以根据斗鱼协议做编码函数:def msg_encode(msg):
#消息以 \0 结尾,并以utf-8编码
msg = msg + '\0'
msg_bytes = msg.encode('utf-8')
#消息长度 + 头部长度8
length_bytes = int.to_bytes(len(msg) + 8, 4, byteorder='little')
#斗鱼客户端发送消息类型 689
type = 689
type_bytes = int.to_bytes(type, 2, byteorder='little')
# 加密字段与保留字段,默认 0 长度各 1
end_bytes = int.to_bytes(0, 1, byteorder='little')
#按顺序相加 消息长度 + 消息长度 + 消息类型 + 加密字段 + 保留字段
head_bytes = length_bytes + length_bytes + type_bytes + end_bytes + end_bytes
#消息头部拼接消息内容
data = head_bytes + msg_bytes
return data
然后根据斗鱼协议做解码函数:def msg_decode(msg_bytes):
#定义一个游标位置
cursor = 0
msg = []
while cursor < len(msg_bytes):
#根据斗鱼协议,报文 前四位与第二个四位,都是消息长度,取前四位,转化成整型
content_length = int.from_bytes(msg_bytes[cursor: (cursor + 4) - 1], byteorder='little')
#报文长度不包含前4位,从第5位开始截取消息长度的字节流,并扣除前8位的协议头,取出正文,用utf-8编码成字符串
content = msg_bytes[(cursor + 4) + 8:(cursor + 4) + content_length - 1].decode(encoding='utf-8',
errors='ignore')
msg.append(content)
cursor = (cursor + 4) + content_length
# print(msg)
return msg
解码后的消息需要反序列化:def msg_format(msg_str):
try:
msg_dict = {}
msg_list = msg_str.split('/')[0:-1]
for msg in msg_list:
msg = msg.replace('@s', '/').replace('@A', '@')
msg_tmp = msg.split('@=')
msg_dict[msg_tmp[0]] = msg_tmp[1]
return msg_dict
except Exception as e:
print(str(e))
2.抓包分析
建议通过chrome开发者工具抓包,或者使用fiddler抓包,网页的东西,直接用chrome更方便
为什么不用斗鱼开放平台提供的api直接用呢,因为api是面向注册的开发者的,api都需要申请使用,普通用户只能抓包分析通用接口
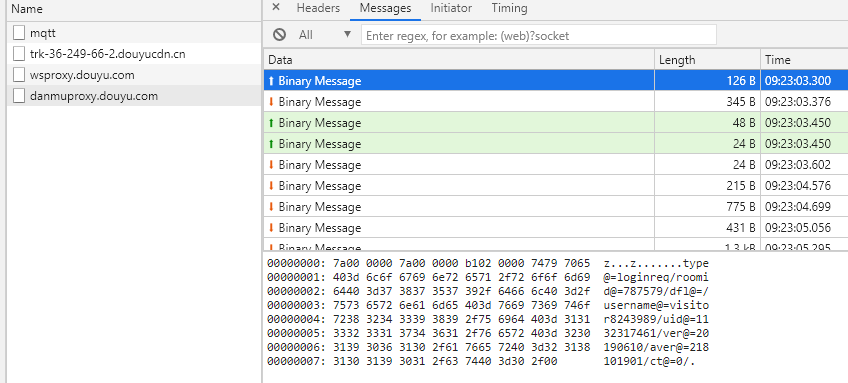
分析:
wsproxy.douyu.com中交
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1303
1303

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









