





 本文介绍了如何在Windows 10环境下使用Python 3.6和CUDA 9.0搭建TensorFlow-GPU 1.5.0环境,包括从GitHub克隆SSD-Tensorflow库、数据预处理(将VOC2007数据转为TFRecord)、训练过程中遇到的GPU资源限制及解决方法。重点讲述了修改代码以简化命令行参数和优化内存使用以避免OOM错误。
本文介绍了如何在Windows 10环境下使用Python 3.6和CUDA 9.0搭建TensorFlow-GPU 1.5.0环境,包括从GitHub克隆SSD-Tensorflow库、数据预处理(将VOC2007数据转为TFRecord)、训练过程中遇到的GPU资源限制及解决方法。重点讲述了修改代码以简化命令行参数和优化内存使用以避免OOM错误。

环境
- Windows10
- Python == 3.6
- cuda == 9.0
- tensorflow-gpu == 1.5.0
-----------------------分割线------------------------------
仓库
https://github.com/balancap/SSD-Tensorflowgithub.comgit clone https://github.com/balancap/SSD-Tensorflow.git
cd SSD-Tensorflow数据集
http://host.robots.ox.ac.uk/pascal/VOC/voc2007/host.robots.ox.ac.uk解压模型
将SSD-Tensorflow/checkpoints下的ssd_300_vgg.ckpt.zip解压到当前文件夹下:
-----------------------分割线------------------------------
踩坑过程
将数据和标签文件序列化为tfrecord
修改SSD-Tensorflow/datasets/pascalvoc_to_tfrecords.py中187行
# 修改前
def run(dataset_dir, output_dir, name='voc_train', shuffling=False):
#修改后
def run(dataset_dir, output_dir, name='voc_2007_train', shuffling=False):并在SSD-Tensorflow目录下新建文件夹tfrecords文件夹, 在SSD-Tensorflow/datasets/pascalvoc_to_tfrecords.py最后添加:
if __name__ == '__main__':
dataset = '你的数据集路径VOC2007'
output = '../tfrecords/'
run(dataset, output)运行pascalvoc_to_tfrecords.py, 在SSD-Tensorflow/tfrecords下看到:
序列化成功。
训练
修改SSD-Tensorflow/train_ssd_network.py文件,
# 修改前
sync_optimizer=None)
if __name__ == '__main__':
tf.app.run()
# 修改后:
sync_optimizer=None)
def run():
FLAGS.train_dir = './logs/'
FLAGS.dataset_dir = './tfrecords'
FLAGS.dataset_name = 'pascalvoc_2007'
FLAGS.dataset_split_name = 'train'
FLAGS.model_name = 'ssd_300_vgg'
FLAGS.checkpoint_path = './checkpoints/ssd_300_vgg.ckpt'
FLAGS.save_summaries_secs = 60
FLAGS.save_interval_secs = 600
FLAGS.weight_decay = 0.0005
FLAGS.optimizer = 'adam'
FLAGS.learning_rate = 0.001
FLAGS.batch_size = 16
tf.app.run()
if __name__ == '__main__':
# tf.app.run()
run()这样修改的目的是不用在cmd中输入一堆参数。
修改后运行,如果遇到下列错误:
F tensorflow/core/kernels/conv_ops.cc:459] Check failed: stream->parent()->GetConvolveAlgorithms(&algorithms)
Aborted (core dumped)修改SSD-Tensorflow/train_ssd_network.py文件第368行后面增加:
config.gpu_options.allow_growth = True再次运行,如果遇到下面错误:
ResourceExhaustedError (see above for traceback): OOM when allocating tensor with shape请将batch_size改小一些。
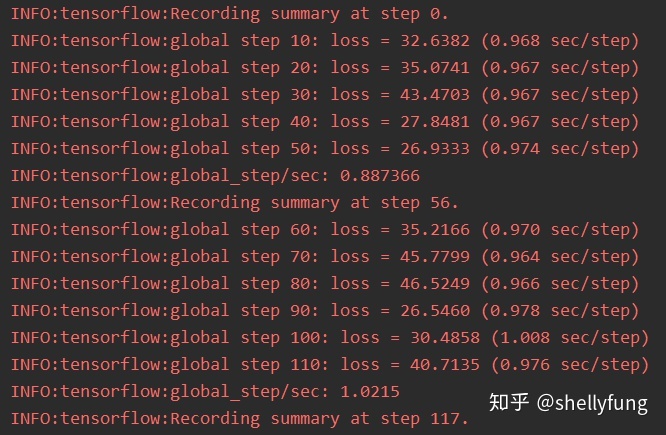
训练过程

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









