



 本文介绍了Python中常用的数据挖掘与机器学习算法,包括KNN、贝叶斯、决策树、逻辑回归和SVM。通过鸢尾花分类案例展示了算法的应用,讨论了算法的选择思路与技巧。KNN算法通过计算距离进行分类,贝叶斯算法基于概率进行预测,决策树通过信息熵选择特征,逻辑回归利用线性转换实现二分类,SVM通过核函数解决线性不可分问题。此外,还提到了Adaboost算法用于提升弱分类器的性能。
本文介绍了Python中常用的数据挖掘与机器学习算法,包括KNN、贝叶斯、决策树、逻辑回归和SVM。通过鸢尾花分类案例展示了算法的应用,讨论了算法的选择思路与技巧。KNN算法通过计算距离进行分类,贝叶斯算法基于概率进行预测,决策树通过信息熵选择特征,逻辑回归利用线性转换实现二分类,SVM通过核函数解决线性不可分问题。此外,还提到了Adaboost算法用于提升弱分类器的性能。
Python数据挖掘与机器学习技术入门实战(1)
作者:韦玮;来源:Python爱好者社区
三、常见分类算法介绍
常见的分类算法有很多,如下图所示:

其中KNN算法和贝叶斯算法都是较为重要的算法,除此之外还有其他的一些算法,如决策树算法、逻辑回归算法和SVM算法。Adaboost算法主要是用于弱分类算法改造成强分类算法。
四、对鸢尾花进行分类案例实战
假如现有一些鸢尾花的数据,这些数据包含了鸢尾花的一些特征,如花瓣长度、花瓣宽度、花萼长度和花萼宽度这四个特征。有了这些历史数据之后,可以利用这些数据进行分类模型的训练,在模型训练完成后,当新出现一朵不知类型的鸢尾花时,便可以借助已训练的模型判断出这朵鸢尾花的类型。这个案例有着不同的实现方法,但是借助哪种分类算法进行实现会更好呢?
1、KNN算法
(1)、KNN算法简介
首先考虑这样一个问题,在上文的淘宝商品中,有三类商品,分别是零食、名牌包包和电器,它们都有两个特征:price和comment。按照价格来排序,名牌包包最贵,电器次之,零食最便宜;按照评论数来排序,零食评论数最多,电器次之,名牌包包最少。然后以price为x轴、comment为y轴建立直角坐标系,将这三类商品的分布绘制在坐标系中,如下图所示:
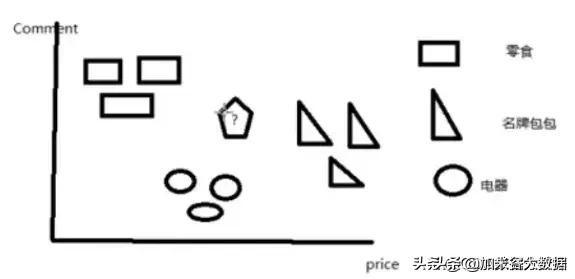
显然可以发现,这三类商品都集中分布在不同的区域。如果现在出现了一个已知其特征的新商品,用?表示这个新商品。根据其特征,该商品在坐标系映射的位置如图所示,问该商品最有可能是这三类商品中的哪种?
这类问题可以采用KNN算法进行解决,该算法的实现思路是,分别计算未知商品到其他各个商品的欧几里得距离之和,然后进行排序,距离之和越小,说明该未知商品与这类商品越相似。例如在经过计算之后,得出该未知商品与电器类的商品的欧几里得距离之和最小,那么就可以认为该商品属于电器类商品。
(2)、实现方式
上述过程的具体实现如下:
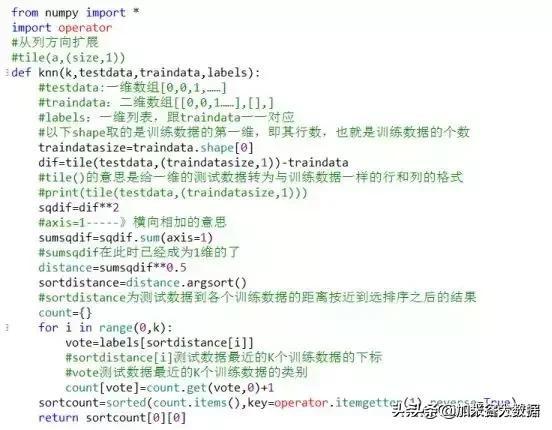
当然也可以直接调包,这样更加简洁和方便,缺点在于使用的人无法理解它的原理:

(3)、使用KNN算法解决鸢尾花的分类问题
首先加载鸢尾花数据。具体有两种加载方案,一种是直接从鸢尾花数据集中读取,在设置好路径之后,通过read_csv()方法进行读取,分离数据集的特征和结果,具体操作如下:

还有一种加载方法是借助sklearn来实现加载。sklearn的datasets中自带有鸢尾花的数据集,通过使用datasets的load_iris()方法就可以将数据加载出来,随后同样获取特征和类别,然后进行训练数据和测试数据的分离(一般做交叉验证),具体是使用train_test_split()方法进行分离,该方法第三个参数代表测试比例,第四个参数是随机种子,具体操作如下:

在加载完成之后,就可以调用上文中提到的KNN算法进行分类了。
2、贝叶斯算法
(1)、贝叶斯算法的介绍
首先介绍朴素贝叶斯公式:P(B|A)=P(A|B)P(B)/P(A)。假如现在有一些课程的数据,如下表所示,价格和课时数是课程的特征,销量是课程的结果,若出现了一门新课,其价格高且课时多,根据已有的数据预测新课的销量。
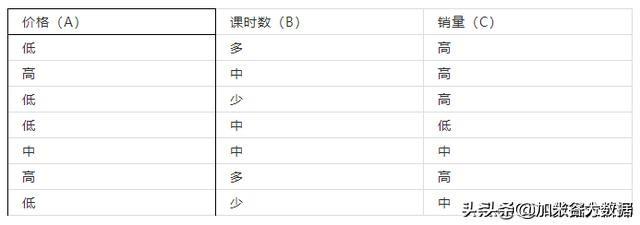
显然这个问题属于分类问题。先对表格进行处理,将特征一与特征二转化成数字,即0代表低,1代表中,2代表高。在进行数字化之后,[[t1,t2],[t1,t2],[t1,t2]]------[[0,2],[2,1],[0,0]],然后对这个二维列表进行转置(便于后续统计),得到[[t1,t1,t1],[t2,t2,t2]]-------[[0,2,0],[2,1,0]]。其中[0,2,0]代表着各个课程价格,[2,1,0]代表各个课程的课时数。
而原问题可以等价于求在价格高、课时多的情况下,新课程销量分别为高、中、低的概率。即P(C|AB)=P(AB|C)P(C)/P(AB)=P(A|C)P(B|C)P(C)/P(AB)=》P(A|C)P(B|C)P(C),其中C有三种情况:c0=高,c1=中,c2=低。而最终需要比较P(c0|AB)、P(c1|AB)和P(c2|AB)这三者的大小,又
P(c0|AB)=P(A|C0)P(B|C0)P(C0)=2/4*2/4*4/7=1/7 P(c1|AB)=P(A|C1)P(B|C1)P(C1)=0=0 P(c2|AB)=P(A|C2)P(B|C2)P(C2)=0=0 显然P(c0|AB)最大,即可预测这门新课的销量为高。
(2)、实现方式
跟KNN算法一样,贝叶斯算法也有两种实现方式,一种是详细的实现:
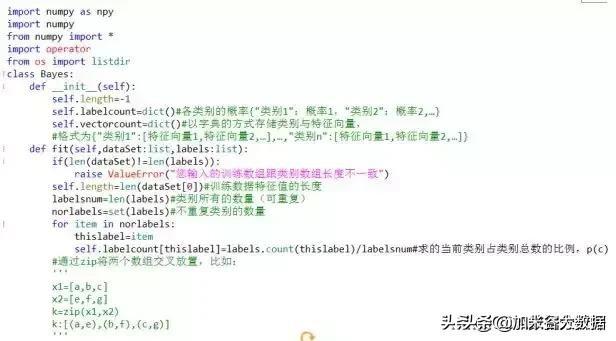
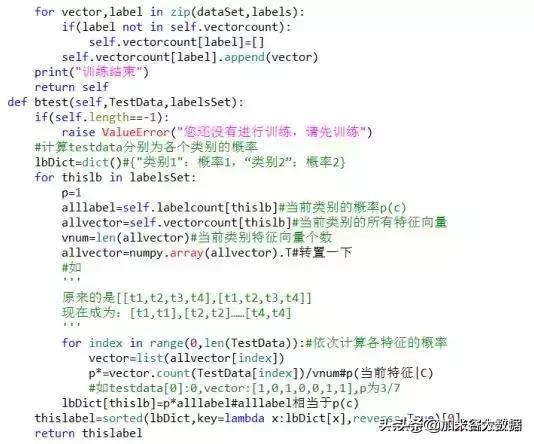
另一种是集成的实现方式:
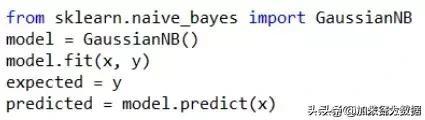
3、决策树算法
决策树算法是基于信息熵的理论去实现的,该算法的计算流程分为以下几个步骤:
- 先计算总信息熵
- 计算各个特征的信息熵
- 计算E以及信息增益,E=总信息熵-信息增益,信息增益=总信息熵-E
- E如果越小,信息增益越大,不确定因素越小
决策树是指对于多特征的数据,对于第一个特征,是否考虑这个特征(0代表不考虑,1代表考虑)会形成一颗二叉树,然后对第二个特征也这么考虑...直到所有特征都考虑完,最终形成一颗决策树。如下图就是一颗决策树:
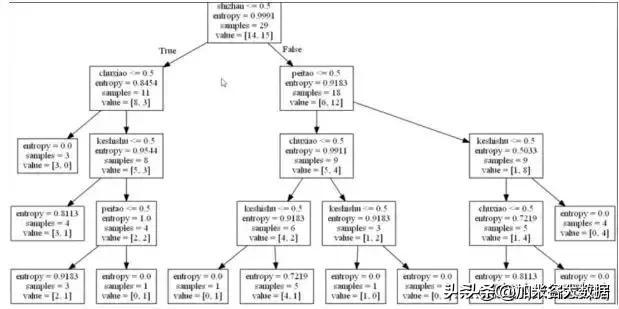
决策树算法实现过程为:首先取出数据的类别,然后对数据转化描述的方式(例如将“是”转化成1,“否”转化成0),借助于sklearn中的DecisionTreeClassifier建立决策树,使用fit()方法进行数据训练,训练完成后直接使用predict()即可得到预测结果,最后使用export_graphviz进行决策树的可视化。具体实现过程如下图所示:
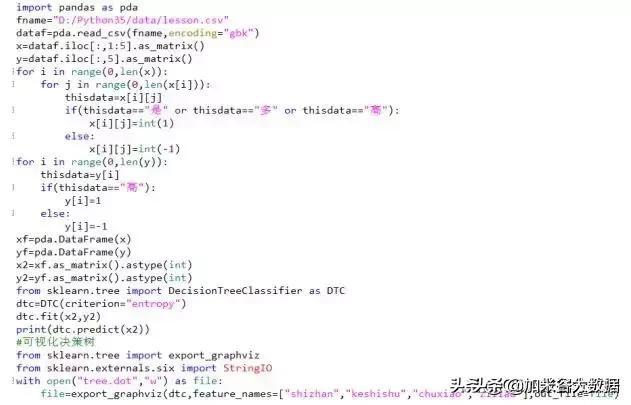
4、逻辑回归算法
逻辑回归算法是借助于线性回归的原理来实现的。假如存在一个线性回归函数:y=a1x1+a2x2+a3x3+…+anxn+b,其中x1到xn代表的是各个特征,虽然可以用这条直线去拟合它,但是由于y范围太大,导致其鲁棒性太差。若想实现分类,需要缩小y的范围到一定的空间内,如[0,1]。这时候通过换元法可以实现y范围的缩小:
令y=ln(p/(1-p)) 那么:e^y=e^(ln(p/(1-p))) => e^y=p/(1-p) =>e^y*(1-p)=p => e^y-p*e^y=p => e^y=p(1+e^y) => p=e^y/(1+e^y) => p属于[0,1] 这样y就降低了范围,从而实现了精准分类,进而实现逻辑回归。
逻辑回归算法对应的实现过程如下图所示:

5、SVM算法
SVM算法是一种精准分类的算法,但是其可解释性并不强。它可以将低维空间线性不可分的问题,变为高位空间上的线性可分。SVM算法的使用十分简单,直接导入SVC,然后训练模型,并进行预测。具体操作如下:

尽管实现非常简单,然而该算法的关键却在于如何选择核函数。核函数可分为以下几类,各个核函数也适用于不同的情况:
- 线性核函数
- 多项式核函数
- 径向基核函数
- Sigmoid核函数
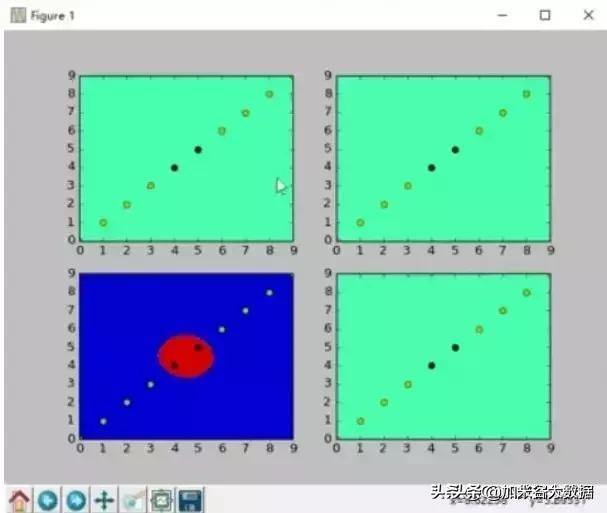
对于不是特别复杂的数据,可以采用线性核函数或者多项式核函数。对于复杂的数据,则采用径向基核函数。采用各个核函数绘制的图像如下图所示:
5、Adaboost算法
假如有一个单层决策树的算法,它是一种弱分类算法(准确率很低的算法)。如果想对这个弱分类器进行加强,可以使用boost的思想去实现,比如使用Adaboost算法,即进行多次的迭代,每次都赋予不同的权重,同时进行错误率的计算并调整权重,最终形成一个综合的结果。
Adaboost算法一般不单独使用,而是组合使用,来加强那些弱分类的算法。
加米谷大数据培训,大数据零基础课程,旨在培养符合市场和企业需求的专业的数大据人才,从编程入门,到数据的采集、预处理, 以及大数据平台的搭建、工具的使用,提供大数据技术详细专业的教学,并结合实际项目进行练习,加强学生对原理知识的理解、对大数据技术的行业应用。
五、分类算法的选择思路与技巧
首先看是二分类还是多分类问题,如果是二分类问题,一般这些算法都可以使用;如果是多分类问题,则可以使用KNN和贝叶斯算法。其次看是否要求高可解释性,如果要求高可解释性,则不能使用SVM算法。再看训练样本数量、再看训练样本数量,如果训练样本的数量太大,则不适合使用KNN算法。最后看是否需要进行弱-强算法改造,如果需要则使用Adaboost算法,否则不使用Adaboost算法。如果不确定,可以选择部分数据进行验证,并进行模型评价(耗时和准确率)。
综上所述,可以总结出各个分类算法的优缺点为:
- KNN:多分类,惰性调用,不宜训练数据过大
- 贝叶斯:多分类,计算量较大,特征间不能相关
- 决策树算法:二分类,可解释性非常好
- 逻辑回归算法:二分类,特征之间是否具有关联无所谓
- SVM算法:二分类,效果比较不错,但可解释性欠缺
- Adaboost算法:适用于对弱分类算法进行加强

















 161
161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









