







 本文深入探讨B+树索引原理,包括其数据结构、存储方式及查找机制。通过实例展示如何插入、查找数据,解释为何B+树适合数据库索引。
本文深入探讨B+树索引原理,包括其数据结构、存储方式及查找机制。通过实例展示如何插入、查找数据,解释为何B+树适合数据库索引。
一、前言
大家都知道加索引能优化对数据库的查询,但你真的了解索引吗,知道索引的数据结构是什么吗?
本文将讲解索引的相关的数据结构和算法并介绍索引是如何存储数据和查找数据的。
二、正文
1.B-Tree索引
通常我们所说的索引是指B-Tree索引,它是目前关系型数据库中查找数据最为常用和有效的索引,大多数存储引擎都支持这种索引。比如InnoDB就是使用的B+Tree。
B+Tree中的B是指balance,意为平衡,即任何节点的两个子树的高度差<=1。
需要注意的是,B+树索引并不能找到一个给定键值的具体行,它找到的只是被查找数据行所在的页,接着数据库会把页读入到内存,再在内存中进行查找,最后得到要查找的数据。
2.两个特征
B+Tree是一种多路搜索树。理解B+Tree时,只需要理解其最重要的两个特征即可:
- 所有的关键字(可以理解为数据)都存储在叶子节点(Leaf Page),非叶子节点(Index Page)并不存储真正的数据,所有记录节点都是按键值大小顺序存放在同一层叶子节点上。
- 所有的叶子节点由指针连接。
如下图为高度为2的简化了的B+Tree。
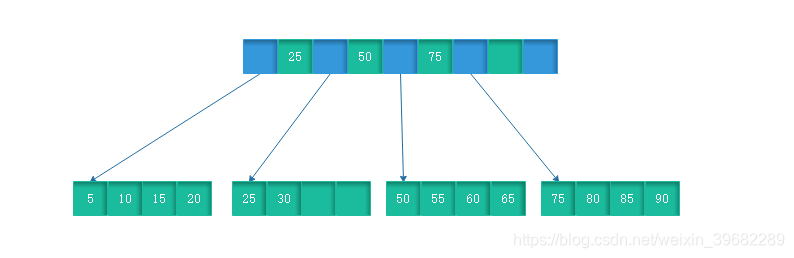
怎么理解这两个特征?MySQL将每个节点的大小设置为一个页的整数倍,也就是在节点空间大小一定的情况下,每个节点可以存储更多的内结点,这样每个结点能索引的范围更大更精确。所有的叶子节点使用指针链接的好处是可以进行区间访问,比如上图中,如果查找大于20而小于30的记录,只需要找到节点25,就可以遍历指针依次找到25、30。如果没有链接指针的话,就无法进行区间查找。这也是MySQL使用B+Tree作为索引存储结构的重要原因。
3.B+Tree节点是如何存储数据的?
通过几个例子简单了解下B+Tree节点存储数据的操作。
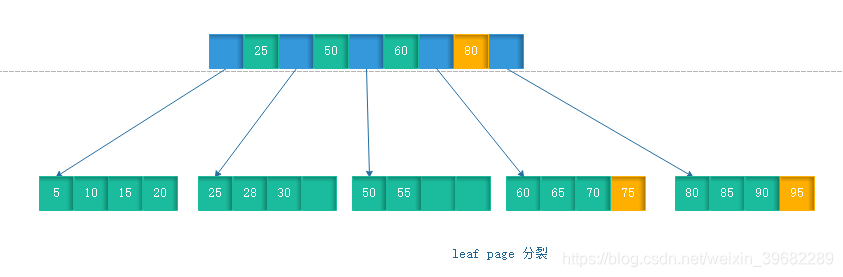
(1)leaf page 和index page都没有满
插入一个28的数据,因为叶节点没满,可以直接插入。
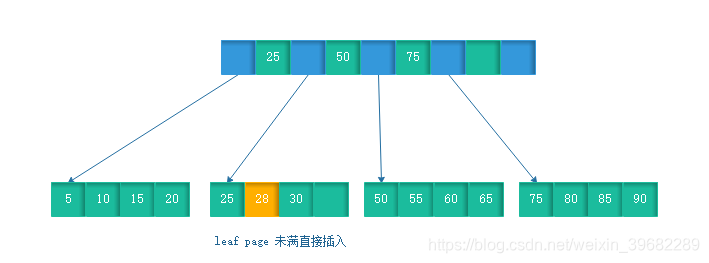
(2)leaf page满,index page未满
插入一个70的数据,但叶节点满,需要做分裂操作。
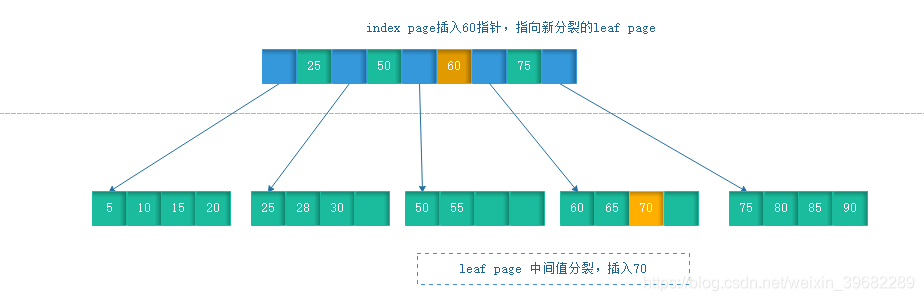
(2)leaf page满,index page满
插入一个95的数据,这时leaf page和index page都满了,需要对leaf page和index page都做拆分,index page拆分后,创建新的index page 指向拆分的index page
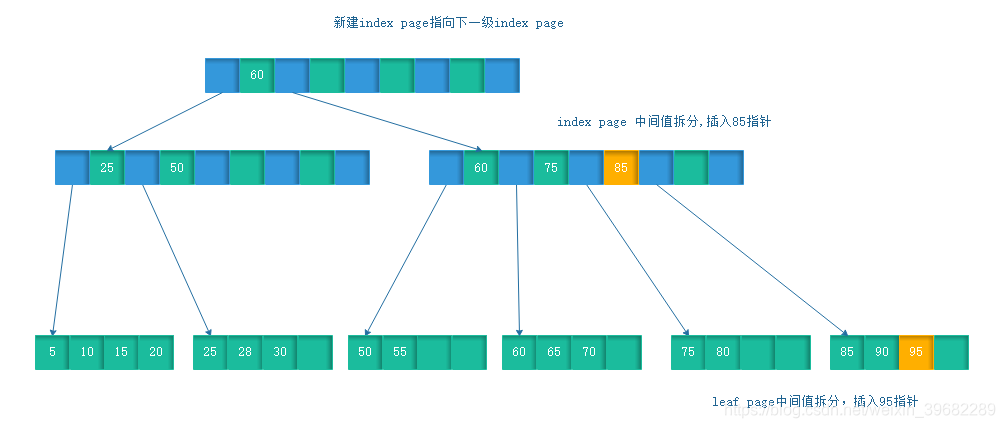
页的拆分需要I/O操作,为了尽可能的减少页的拆分操作,B+Tree也提供了类似于平衡二叉树的旋转功能。
当Leaf Page已满但其左右兄弟节点没有满的情况下,B+Tree并不急于去做拆分操作,而是将记录移到当前所在页的兄弟节点上。通常情况下,左兄弟会被先检查用来做旋转操作。如上例,当插入95时,并不会做页拆分,而是左旋操作。
4.组合索引是如何存储数据的?
以一个简单示例说明,有以下数据表:
CREATE TABLE User(
name varchar(50) not null,
stature tinyint not null,
birth_year int not null,
gender enum(`m`,`f`) not null,
key(name,stature ,birth_year)
);
对于表中每一行数据,索引中包含了nam(名称),stature (身高),birth_year (出生年份)的值,下图展示了索引是如何存储组合索引数据的。
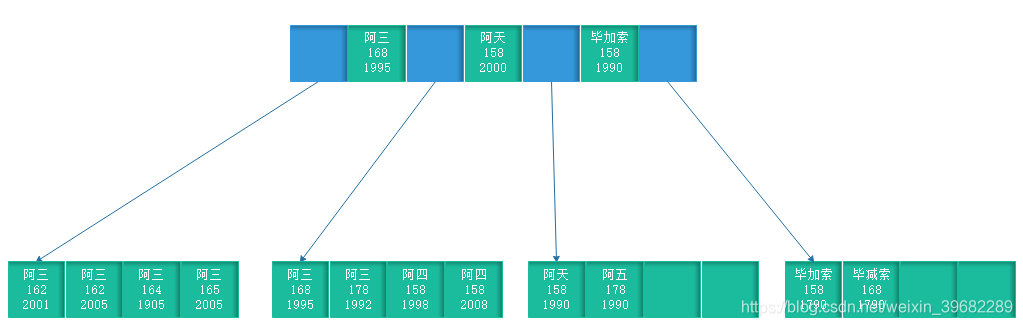
由上图可以看到,索引首先根据第一个字段来排序,当第一个字段相同时,就根据第二个字段排序,以此类推。正是因为这个原因,才有了索引的“最左原则”。
5.索引是如何查找数据的?
索引的查找会根据排序查找,如果是组合索引,则先按第一个排序查找,再按第二个排序查找,以此类推。
从上面可以看出组合索引中,如果前一个索引的值是范围值,非固定常量,则下一个索引将会是无序的,那就会导致下一个索引失效。
由上图举个栗子:
select id from User where name = '阿三' and stature < 165 and birth_year = 1992
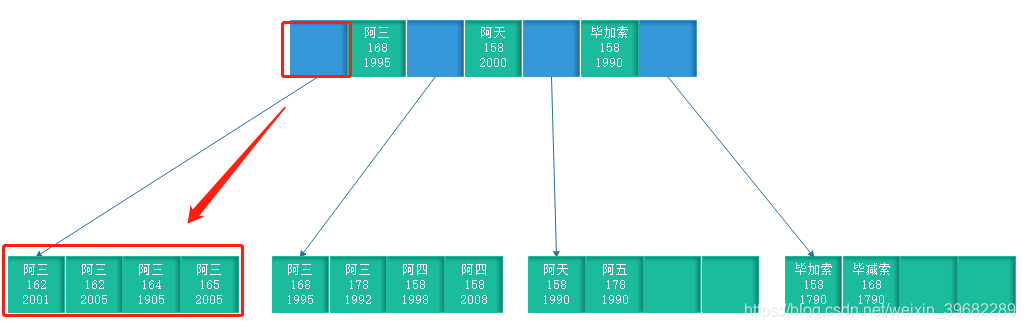
- name等于“阿三”可定位数据在 [ 阿三 168 1996]的左边或者右边。
- 168大于165,所以stature小于165的数据在 [ 阿三 168 1996]的左边leaf page中。
- 在leaf page 再过滤status小于165的数据。

从上面图可看到,birth_year已经是无序的了,说明索引到这里已经失效了。


















 462
462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











