







目录
追问:TCP有TCP的分段,IP层有IP分片。这两个有什么区别?现在用的是哪个?
mysql 两次写(double write buffer)了解吗?
单核CPU如何执行多个程序?
操作系统会为每个程序分配一个时间片,这个时间片是一个很短的时间间隔,例如几十毫秒。
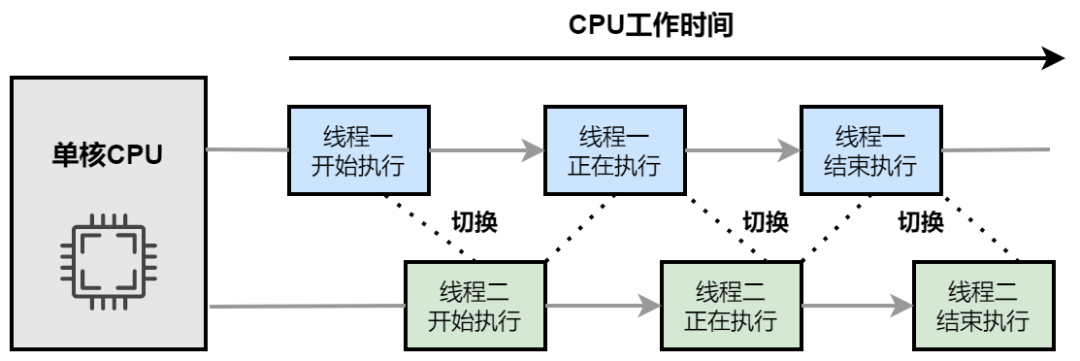
单核 CPU 会轮流执行每个程序,在一个时间片内执行一个程序,当这个时间片用完后,就切换到下一个程序。这种方式给用户一种多个程序在同时运行的假象,因为切换速度非常快,用户难以察觉程序之间的切换。
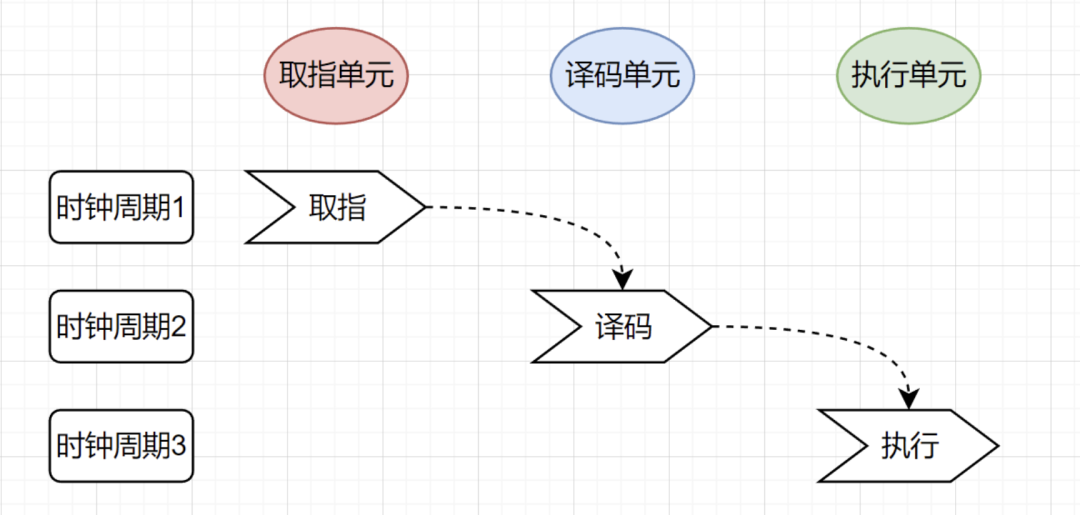
CPU的流水线设计有了解吗?
一条指令的执行需要经过取指令,翻译指令,执行指令三个基本流程。CPU内部的电路也分为不同的单元:取指单元、译码单元、执行单元等,指令的执行也是按照流水线的工序一步一步执行的。
如果采用流水线技术,则每个时钟周期内只有一个单元在工作,其余两个单元在“观望”
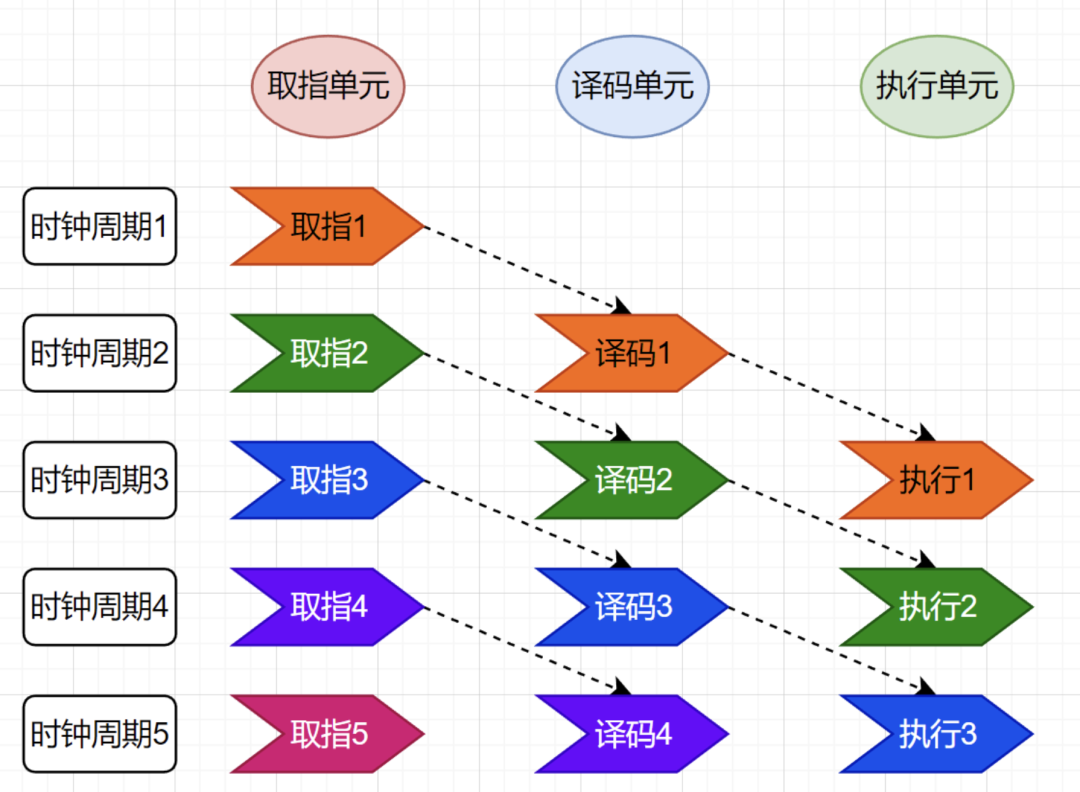
流水线设计将这些操作分成多个独立的阶段,每个阶段由专门的硬件单元负责,使不同指令的不同阶段可以并行执行,流水线的本质就是拿空间换时间。将每条指令的步骤分解到不同的电路单元,从而使得多个指令并行执行。
这就好像我们的后端程序员不需要等待功能上线,就会从产品经理手中拿到下一个需求,开始开发 API。这样的协作模式,就是我们所说的 指令流水线 。这里面每一个独立的步骤,我们就称之为 流水线阶段 或者流水线级。
如果我们把一个指令拆分成“取指令 - 指令译码 - 执行指令”这样三个部分,那这就是一个三级的流水线。如果我们进一步把“执行指令”拆分成“ALU 计算(指令执行)- 内存访问 - 数据写回”,那么它就会变成一个五级的流水线。
例如,在一个简单的 5 级流水线中,当一条指令在执行阶段时,下一条指令可以在译码阶段,再下一条指令可以在取指阶段。
尽管流水线无法减少单条指令执行时的 “延时” 这一性能指标,不过,借助于同时对多条指令的不同阶段展开执行,我们能够有效地提升 CPU 的 “吞吐率”。从外部视角来看,CPU 仿佛具备了 “一心多用” 的能力,在同一时刻,可以同时对 5 条不同指令的不同阶段进行处理。在 CPU 内部,其运行机制就好似一条生产线,不同分工的组件持续处理着从上游传递过来的内容,而无需像传统模式那样,等到一件商品完全生产完毕之后,才开始下一件商品的生产流程。
CPU绑定的操作有了解吗?
在单核 CPU,虽然只能执行一个线程,但是操作系统给每个线程分配了一个时间片,时间片用完了,就调度下一个线程,于是各个线程就按时间片交替地占用 CPU,从宏观上看起来各个线程同时在执行。
而现代 CPU 都是多核心的,线程可能在不同 CPU 核心来回切换执行,这对 CPU Cache 不是有利的,虽然 L3 Cache 是多核心之间共享的,但是 L1 和 L2 Cache 都是每个核心独有的,如果一个线程在不同核心来回切换,各个核心的缓存命中率就会受到影响,相反如果线程都在同一个核心上执行,那么其数据的 L1 和 L2 Cache 的缓存命中率可以得到有效提高,缓存命中率高就意味着 CPU 可以减少访问 内存的频率。
当有多个同时执行「计算密集型」的线程,为了防止因为切换到不同的核心,而导致缓存命中率下降的问题,我们可以把线程绑定在某一个 CPU 核心上,这样性能可以得到非常可观的提升。
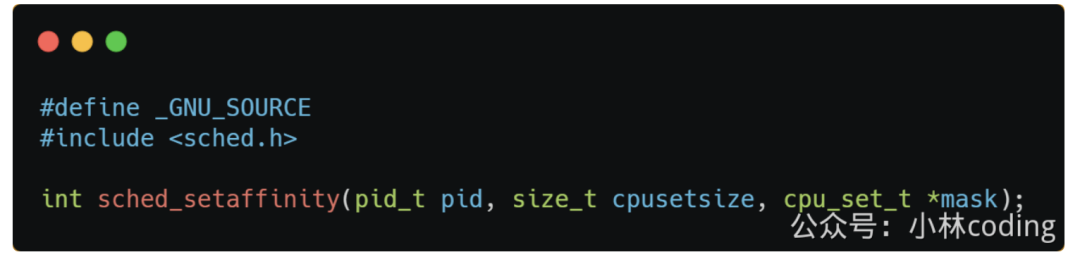
在 Linux 上提供了 sched_setaffinity 方法,来实现将线程绑定到某个 CPU 核心这一功能。
网络
URL从输入到响应的流程?
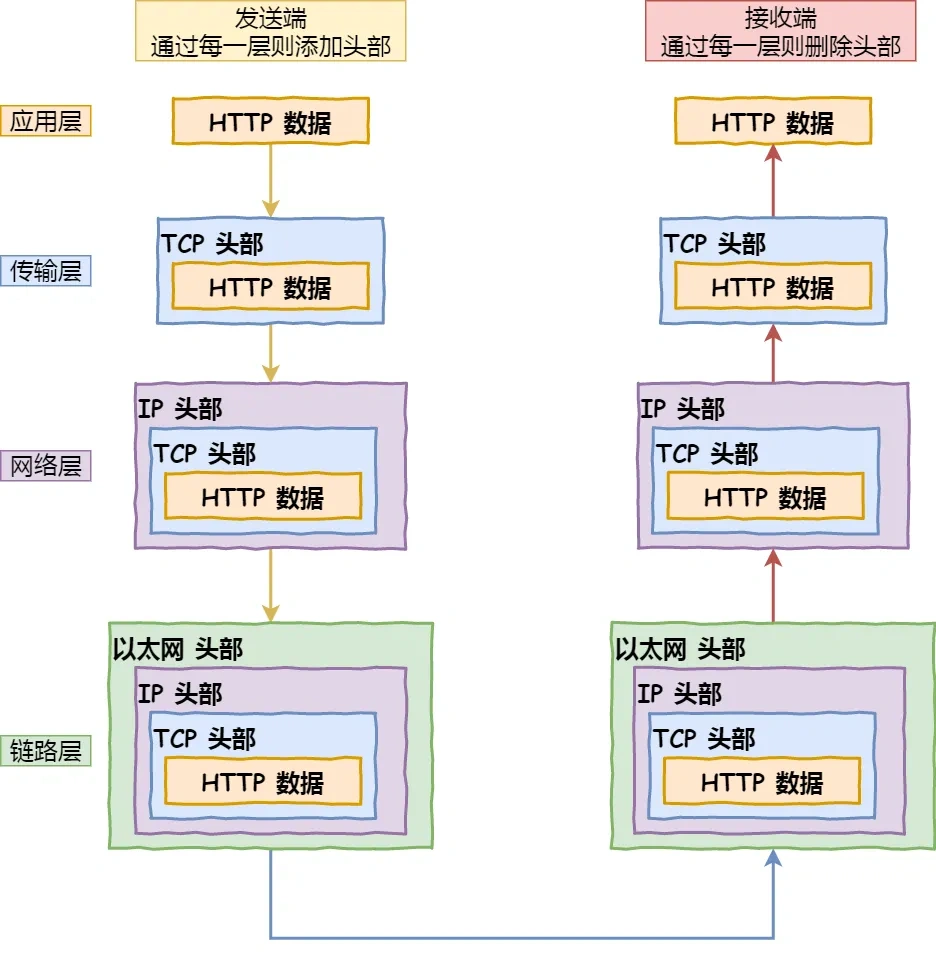
null
-
解析URL:分析 URL 所需要使用的传输协议和请求的资源路径。如果输入的 URL 中的协议或者主机名不合法,将会把地址栏中输入的内容传递给搜索引擎。如果没有问题,浏览器会检查 URL 中是否出现了非法字符,则对非法字符进行转义后在进行下一过程。
-
缓存判断:浏览器会判断所请求的资源是否在缓存里,如果请求的资源在缓存里且没有失效,那么就直接使用,否则向服务器发起新的请求。
-
DNS解析:如果资源不在本地缓存,首先需要进行DNS解析。浏览器会向本地DNS服务器发送域名解析请求,本地DNS服务器会逐级查询,最终找到对应的IP地址。
-
获取MAC地址:当浏览器得到 IP 地址后,数据传输还需要知道目的主机 MAC 地址,因为应用层下发数据给传输层,TCP 协议会指定源端口号和目的端口号,然后下发给网络层。网络层会将本机地址作为源地址,获取的 IP 地址作为目的地址。然后将下发给数据链路层,数据链路层的发送需要加入通信双方的 MAC 地址,本机的 MAC 地址作为源 MAC 地址,目的 MAC 地址需要分情况处理。通过将 IP 地址与本机的子网掩码相结合,可以判断是否与请求主机在同一个子网里,如果在同一个子网里,可以使用 APR 协议获取到目的主机的 MAC 地址,如果不在一个子网里,那么请求应该转发给网关,由它代为转发,此时同样可以通过 ARP 协议来获取网关的 MAC 地址,此时目的主机的 MAC 地址应该为网关的地址。
-
建立TCP连接:主机将使用目标 IP地址和目标MAC地址发送一个TCP SYN包,请求建立一个TCP连接,然后交给路由器转发,等路由器转到目标服务器后,服务器回复一个SYN-ACK包,确认连接请求。然后,主机发送一个ACK包,确认已收到服务器的确认,然后 TCP 连接建立完成。
-
HTTPS 的 TLS 四次握手:如果使用的是 HTTPS 协议,在通信前还存在 TLS 的四次握手。
-
发送HTTP请求:连接建立后,浏览器会向服务器发送HTTP请求。请求中包含了用户需要获取的资源的信息,例如网页的URL、请求方法(GET、POST等)等。
-
服务器处理请求并返回响应:服务器收到请求后,会根据请求的内容进行相应的处理。例如,如果是请求网页,服务器会读取相应的网页文件,并生成HTTP响应。
追问:TCP连接除了IP地址还需要什么?
还需要端口号,端口号用于标识一个主机上的特定服务或进程。
-
源端口号是发送端应用程序使用的端口,它是一个 16 位的数字,范围从 0 到 65535。一般来说,客户端通常使用一个大于 1023 的临时端口号。
-
目的端口号是接收端应用程序使用的端口,不同的服务通常使用固定的知名端口号,例如 HTTP 使用端口 80 或 8080,HTTPS 使用端口 443,FTP 使用端口 21 等。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 838
838

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











