






 本文探讨了语音交互的优势和劣势,包括在家居、车载出行和企业应用等领域的应用,并介绍了相关技术,如ASR、NLP和TTS。尽管存在注意力、心理和技术障碍,语音交互因其高效、自然的特性在多个场景中展现出潜力。
本文探讨了语音交互的优势和劣势,包括在家居、车载出行和企业应用等领域的应用,并介绍了相关技术,如ASR、NLP和TTS。尽管存在注意力、心理和技术障碍,语音交互因其高效、自然的特性在多个场景中展现出潜力。
从功能机时代到智能机时代,人与机器的交互方式一直在变化。尤其是近几年来,语音交互一直是研究的热点,从天猫精灵,小爱音箱到『理解万岁』的TNT,都用到了语音交互。

VUI(语音交互方式)不再依赖固定的路径完成操作指令,而且是每个人都可以有自己的方式和特色。

1、什么是语音交互
语音交互作为新一代的交互模式,通俗的讲,就是用人类最自然的语言(开口说话)给机器下达指令,达成自己的目的的过程,这一过程包括三个环节:能听、会说、懂你。

自动语音识别:Automatic Speech Recognition, ASR
自然语言处理:Natural Language Processing, NLP
文字转语音:Text to Speech, TTS
2、交互方式强在哪里?
在这里,小原引用TXD设计原则对语音交互方式进行优势分析(该方法可用在日常交互设计评判中)

TXD设计原则


GUI与VUI交互方式横向优势对比图
总结来说,语音交互具备以下四点优势:
①输入更高效。研究结果表明,语音输入比键盘输入快3倍。如果你从解锁手机到设置闹钟需要两分钟,直接说一句话设置闹钟,可能只需要10秒钟;
②表达更自然。人类是先有语音再有文字,每个人都会说话但有一部分人不会写字,语音交互比界面交互更自然,学习成本更低;
③感官占用更少。一张嘴,将人的双手、眼睛从图形界面交互中解放出来,想象一下当你手握方向盘时,说一句话就直接接听电话、播放音乐,是不是更方便也更安全。腾出来的感官,意味着可以并行处理其他任务,理论上有更高的效率。
④信息容量更大。语音中包含了语气、音量、语调和语速这些特征,交流的双方可以传达大量的信息,特别是情绪的表达,其表达的方式也更带有个人特色和场景特色。当见不着面,听不到声音的时候,人与人之间的真实感就会下降很多。
2、劣势
语音交互走到今天,已经付出了非常大的努力,但依然是有多少人工,就有多少智能。


GUI与VUI交互方式横向劣势对比图
总结来说,语音交互具备以下三点劣势:
①注意力障碍
语音交互是非可视化的,带来的问题就是增加人的记忆负担。你打过银行的客户电话就知道,你必须集中精力听完语音播报之后才能做下一步动作,如果你比较着急的话,那你就会非常的难受。
事实上,人在获取信息的适合,视觉要强过听觉。对于语音的效率问题,可以说是单方面的输入更高效,而双向互动反而效率不高。或者说,获取信息的时候,视觉有很大的优势,而声音的效率并不高(现实中为什么总会出现“打断”对话的现象,就是因为语音的表达效率不高,听者等不及)。
②心理障碍
从心理感受出发,没有多少人愿意对着冰冷的机器说话,然后得到毫无感情的甚至是错误的回应。语音交互存在的另一个心理障碍是,语音交互的不可预设和预判性。
不同的人,在同样的情境下都可能产生完全不同的行为和预期。这给设计者带来很大困扰,也为用户带来不确定性的担忧。在面对不可预知的状况下,设计者和使用者互相难以领会彼此的意图,就会形成一种博弈消耗。
为了应对这种不确定性,可能导致系统必须通过更多的场景理解和上下文关系,去解析用户的意图来做出可能合理的信息反馈,这将进一步带来技术的复杂度。
③技术障碍
语音交互为什么如此受到期待,是因为太富有想象空间了,能够让我们尽可能的释放被占用的感官。想象一下,你只说一句“订一箱牛奶”,快递就会在约定好的时间送过来,多美好的生活。现实生活中,人与人的交流,甚至一个眼神一个动作就可以引起对方的注意和反馈。
而现阶段的智能音箱需要定义一个将助手从待机状态切换到工作状态的词语,即所谓的“唤醒词”,这是一个不得已而为之的蹩脚设计,你想做什么之前都要先来一句“小明小明”,这种叠词的对话方式特别让人反感。
3、交互方式用在哪里?
语音交互同互联网诞生以来用户就习惯的GUI界面交互相比,主要是输入方式不同导致的,最显著特性就是“解放了双手”——你在使用语音请求时,眼睛和手可以同时忙于其他的事情。

①家居:在家庭“相对封闭与安全”(特指针对语音信号采集的干扰程度),通过语音交互指令控制家居开关是很好的切入点。相信在不久的将来,搭载了语音交互系统的智能家居,都可以听你的话,你说所说的每个指令,都会直接影响/控制到当前家居的运行状态。“你可能越来越惬意,也可能越来越懒……”

②车载出行语音交互系统:释放了驾驶员的手和眼,让司机专注于前方的路况,如接听电话、开关车窗、播放广播音乐、路线导航等语音交互指令。

③企业应用:未来会有各种各样专业的知识工作者会在或大或小的程度被简化或者被替代,比如文本、数据的录入工作,比如客服机器人。但,极不太可能的是直接对着一个设备吼两嗓子做一个PPT的方式。

④医疗&教育:如语音记录病历,不管对医生来说还是患者来说,都是提高看病效率的很好的辅助手段之一。以目前的技术条件而言,单向的指令性动作是最适合语音来表达的,因为它足够清晰和直接。

4、语音交互涉及技术
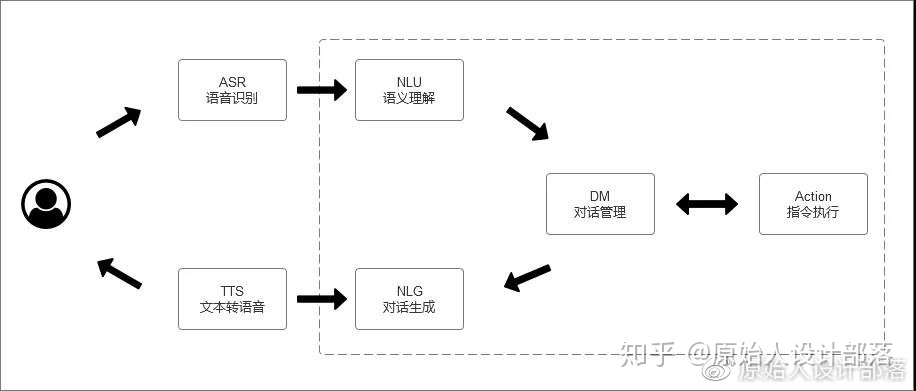
语音所涉及的技术模块有 4 个部分,分别为:
自动语音识别:Automatic Speech Recognition, ASR
自然语言理解:Natural Language Understanding, NLU
自然语言生成:Natural Language Generation, NLG
文字转语音:Text to Speech, TTS
上图即为语音交互技术包括的识别、理解和对话三个部分。
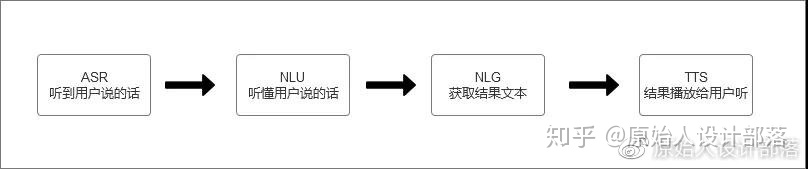
整个过程通俗的说,就是通过麦克风让机器能听到用户说的话,然后听懂用户想要表达的意思,并把反馈的结果“说给用户听”。

小明:明天什么天气?
助手:晴,37摄氏度。
整个过程分解之后,就变成这样一个过程:
a.小明对着机器说一句话后,机器内置的麦克风识别到小明说的话,把口语化的文本归一、纠错,并书面化(ASR相当于耳朵);
b.机器根据文本理解小明的意图并进入对话管理(DM相当于人脑)(当意图不明确时,还需要机器发起确认对话,继续补充相关内容,这就是多轮对话)
c.在明确小明意图后,去获取相关的数据,或者执行相关的命令;
d.最后通过TTS将文本信息合成为声音,通过扬声器播放给小明听(TTS相当于嘴)
至此完成一个完成对话过程。
好了,今天的分享就到这里了
大家有任何疑惑可以随时联系小原
下期再见,一同学习设计相关知识吧~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









