



 本文介绍了Python爬虫在抓取网页数据时可能遇到的问题及解决方案,包括基础爬虫、添加headers、查找数据源、处理动态加载内容。重点提到数据可能隐藏在NetWork的XHR或JS中,以及动态加载数据的处理方法,如使用selenium模块。建议读者深入学习以应对更复杂的爬虫挑战。
本文介绍了Python爬虫在抓取网页数据时可能遇到的问题及解决方案,包括基础爬虫、添加headers、查找数据源、处理动态加载内容。重点提到数据可能隐藏在NetWork的XHR或JS中,以及动态加载数据的处理方法,如使用selenium模块。建议读者深入学习以应对更复杂的爬虫挑战。

近期,通过做了一些小的项目,觉得对于Python爬虫有了一定的了解,于是,就对于Python爬虫爬取数据做了一个小小的总结,希望大家喜欢!
1.最简单的Python爬虫
最简单的Python爬虫莫过于直接使用urllib.request.urlopen(url=某网站)或者requests.get(url=某网站)
例如:爬取漫客栈里面的漫画
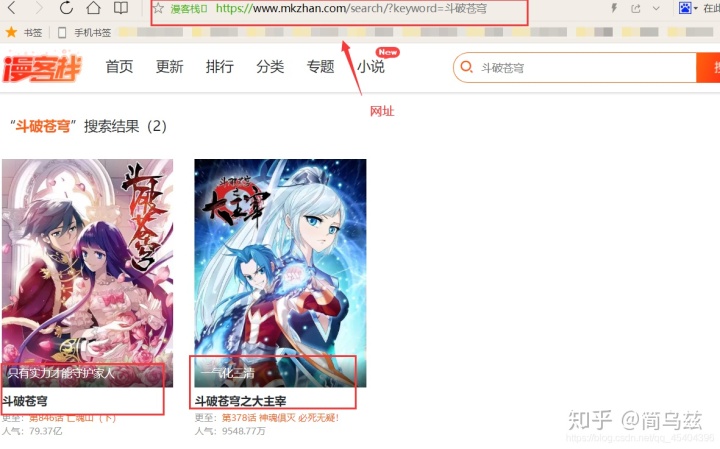
代码和运行结果:
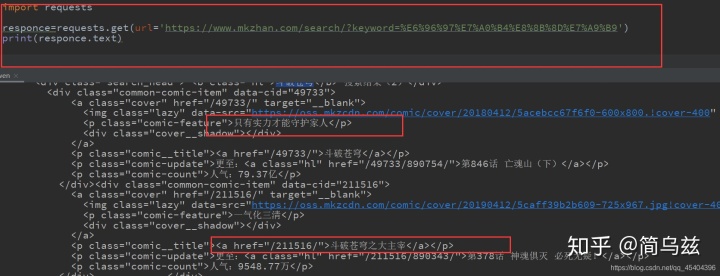
这是最简单也是最基础的Python爬虫.
2.需要添加headers的Python爬虫
有的网址爬取数据需要添加User-Sgent、Cookie等字段信息,这个时候我们需要添加一个请求头,也就是一个字典,User-Sgent、Cookie等字段信息就放这里面。
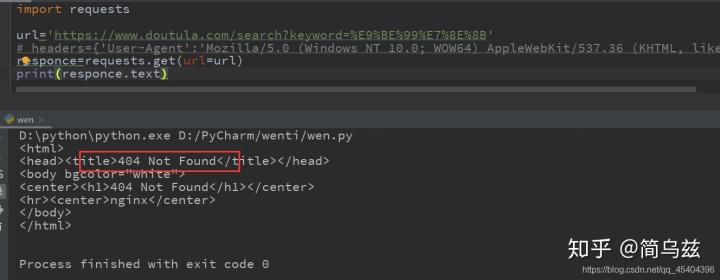
如:运用Python爬虫下载表情包
没加请求头
加上请求头:
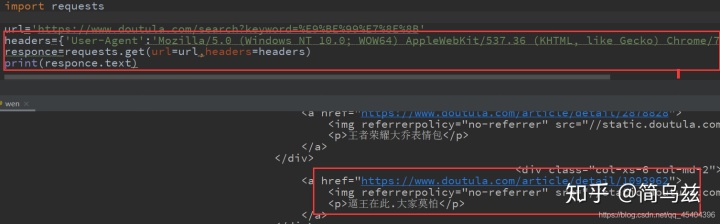
是不是加与没加,就有很大的区别.
3.所爬取的数据在NetWork里面
有个时候,我们所爬取的数据添加请求头之后,也爬取不到,这个时候,我们就需要想一想NetWork,下面有XHR和JS,也许所需要数据就在这两个其中的一个里面。
如:爬取王者荣耀英雄皮肤
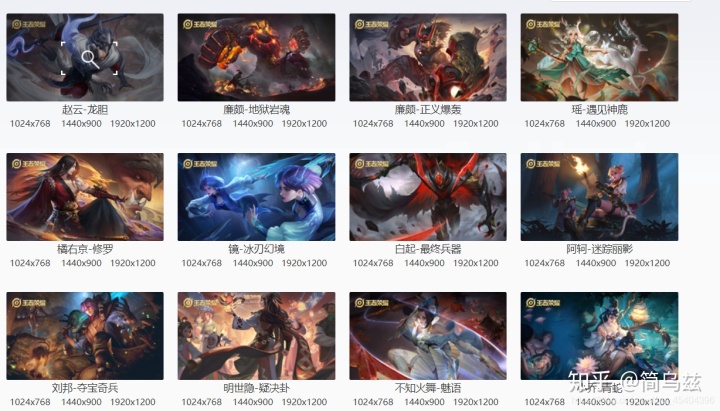
如果用上面第二种方法,可以发现,就算添加请求头,也访问不到数据,我们看一下网页源代码,发现,这些数据根本就不在源代码中,所以这样肯定爬不到数据。
我们点击电脑键盘F12,然后再点击NetWork下面的JS,按F5刷新,可以发现,这些图片的下载链接在JS下面的一个json文件里。
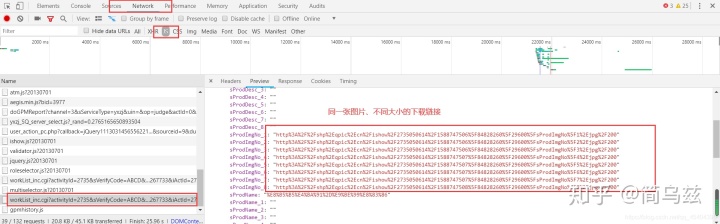
4.动态加载的数据
动态加载的,像网易云音乐,虽然我们也可以在NetWork下面找到相应的数据,但是这是一个post请求,比较复杂,我们可以使用selenium模块,这个过程我就不讲解了。
5.总结
上面讲解的这些,我都有关于它们的文章,读者可以自行找到并阅读。
也许我还是一个Python爬虫小白吧!讲解的深度还不够,希望大家谅解,在以后的日子里,我会加油学的。如果读者觉得我的这篇文章对于你有所帮助,希望大家给我点一个小小的赞,谢谢!

















 1274
1274

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









