







图文原创:亲爱的数据
最前沿的芯片,
没有教材,
再叠加大语言模型(LLM)
这一轮在芯片上的新需求。
谭老师我写芯片,
想给每篇文章前面加一个修饰词,
《作者直到最近才费劲弄清楚的……》
2.AI推理红海战:百万Token一元钱,低价背后藏何种猫腻?
3.质疑美国芯片Etched:AI领域最大赌注的尽头是散热?
做科技博主的好处,
可以抓大佬,
求教,
研讨,
审稿。
一路上有你,
苦一点也愿意,
苦太多,
就算了。
我们努力做到,
在“亲爱的数据”的100%微信文章中,
专家未审就发的稿件,数量为0。
所以,发文做不到太密集。
审稿专家也很忙。
借微信张小龙大神的名言:
“一个好的产品不需要费口舌解释,
解释了这么多,说明我们做得不够好。”
深感惭愧。
要不然,
先把试题做了,
咱再聊。
和上次一样,
开卷测试。

全球卷
并不绝密
★
启用前
(一)选择题
(送分题)
1.下图中CPU的功耗,位于?
A. 左上
回答错误 ✕
解析:不在这
B. 左下
回答错误 ✕
解析:不在这
C. 右下
回答正确 √
解析:就是这里,CPU功耗很高。
D. 右上
回答错误 ✕
解析:不在这
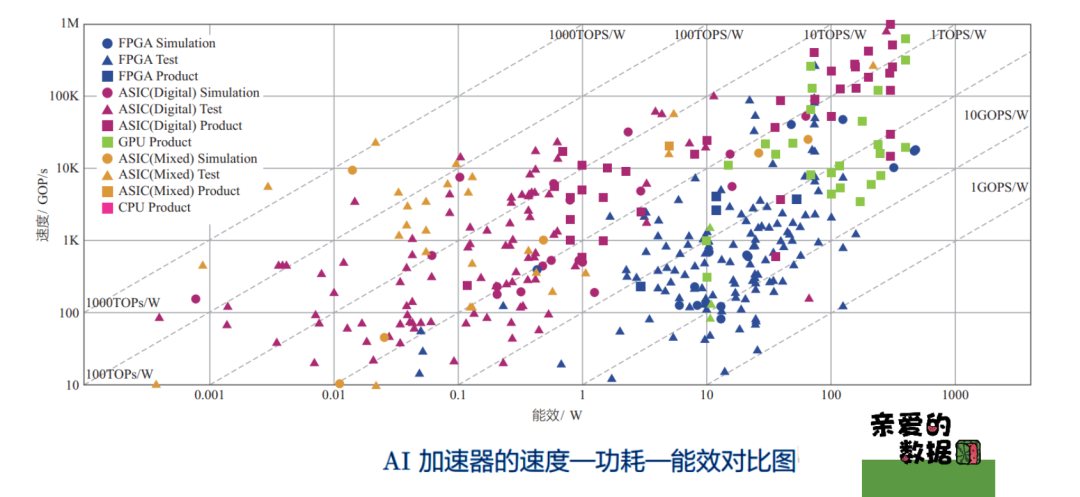
点击选项,查看正确选项。
全球卷
并不绝密
★
启用前
(二)问答题
(送分题)
为什么加速大模型推理,有KV Cache而没有Q Cache?
解:因为是当前Token的Q,
和之前所有Token的K和V,
以及当前Token的K 和V做计算,
用不到之前Token的Q,
当然不需要缓存。
送命题
(三)看图问答题

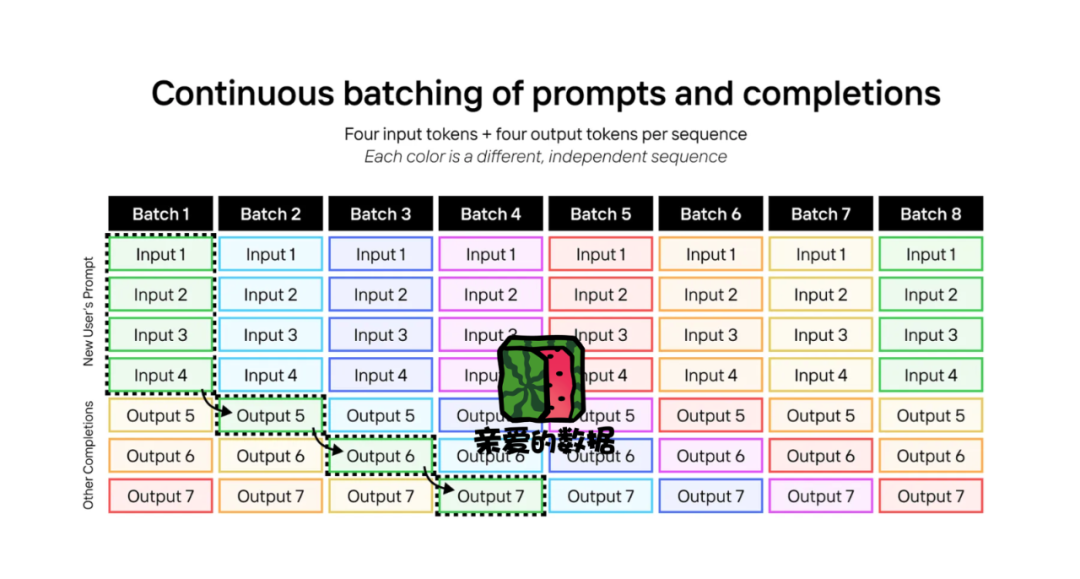
AI芯片推理是学术界和工业界关注热点,
AI推理中,
人人都面对两大“苦楚”,
准备(Prefill)阶段的算力瓶颈,
生成(Decoding)阶段的内存瓶颈,
请根据硅谷芯片公司Ethched技术博客,
和示意图,
分析Sohu芯片的推理原理。
并回答,Sohu芯片如何克服“内存瓶颈”?
解:
目前市面上,
有两种方式处理准备(Prefill),
和生成(Decoding)。
第一:分开做。
所有样本先全部一起做准备(Prefill),
再全部一起生成(Decoding)。
第二:合起来做。
一些样本准备(Prefill),
和另一些样本的生成(Decoding),
混在一起做。
Sohu这款AI芯片的技术路线,
选择的是后者。
已知条件:
输入序列长度:2048,
批次数量为:1+127=128,
此图为一个缩小版的推理实现方法。
毕竟,
如若全画,
图就太大。
那设计个小的,
也说明原理。
上图缩小版已知条件:
输入序列长度是4个词元,
批次数量是5。
别看数量少,
科技含量高,
你这么想,
第一次是做样本1的准备,
第二次做样本2的准备和样本1的生成,
第三次做的是样本3的准备和样本1样本2的生成,
依次类推。
不用多推,
很快,
准备阶段将没有输入的词元要处理,
且将变为空闲。
因为批次数量只有5,
第六次开始,准备阶段没有工作了,
开始准备摸鱼了,
而生成阶段就惨了,
挤满了样本(12345)。
一旦这样,
生成(Decoding)出现“内存瓶颈”。
谭老师,敲黑板。
这里很重要,当批次数量很小,
没有准备阶段的那部分计算什么事情。
于是,“内存瓶颈”直接站C位。
所以,这种思路,批次数量小了可不行。
关于Sohu芯片的设计结论来了,
批次数量一定要大。
怪不得,Sohu芯片的输入的序列长度是2048个词元,共128个批次。
Sohu芯片为了能极致利用它的算力,
得用很大的批处理量,
不然很容易陷入“准备(Prefill)失业”,
内存“挤爆”的窘境。
于是,顺着他们Etched公司的逻辑,
还要把内存瓶颈(Memory bound)那部分时间,
藏在了准备阶段那部分时间之中。
也就是,把第二部分内存所耗的时间,
藏在第一部分Prefill所用的时间里。
这个过程也相当的快,
(详细计算过程参见前一篇:
因为,0.0044秒×128 =0. 56秒,
所以,仅花0.56秒,
就能把所有样本都Prefill完,
有趣的是,
在Sohu芯片团队眼中,
所有的问题,
最后归结成一个计算瓶颈的问题。
两个瓶颈总算干掉一个。
日子也没有那么苦了。
那就堆计算资源来解决。
换个角度,Sohu芯片的故事是,
英伟达公司只用3%的晶体管来做计算,
这个思路不是做AI芯片最好的思路。
Sohu芯片完全有理由堆得更多,
堆出个20倍提高。
这种思路才是最好的。

允许有同学举手说没有搞懂。
谭老师我也常说,
俺也一样。
不过,没关系,
总能找到“大佬”求赐教。
而至于大佬的水平,
那就和谭老师我找大佬的水平息息相关。
禁止俄罗斯套娃梗。
聊回这套试题,
答案解析如下。
解析一:
CPU做矩阵乘法有个特点:
又慢,功耗又大。
原因是它的运算单元以通用为主,
所以,做矩阵乘法并不高效。
英伟达的GPU里的Tensor Core是做矩阵运算的架构,
做矩阵乘法自然极为高效。
美国硅谷的几位专家告诉我,
英伟达花了很多人力物力去优化,
甚至可以说,在单位面积上,
Tensor Core的性能能耗比已经非常高了,
几乎和ASIC是一个量级的。
所以,机会也没有留给ASIC。
有两位硅谷芯片专家讨论如下:
其中一位原话是:“
如果ASIC优化工作做得特别好,
也许会有1.5倍到2倍的性能提升,
但是,20倍,
想都别想”。
另一位专家则补充了一句:
“话别说得太绝对,”
他继续说,
”提升20倍,脱离实际。”
解析二:
既然有两种技术路线,
Sohu这款AI芯片选哪种?
一种是,分开做。
另一种是,合起来做。
按照谭老师我的理解,
这不就是排队单打和混合双打吗?
Sohu选“混合双打”。
补充证据如下,
信息来自Sohu芯片的科技博客。

英文:
On GPUs and on Sohu, inference is run in batches. Each batch loads all of the model weights once, and re-uses them across every token in the batch. Generally, LLM inputs are compute-bound, and LLM outputs are memory-bound. When we combine input and output tokens with continuous batching, the workload becomes very compute bound.

中文
在 GPU 和Sohu的系统上,
推理过程是以批处理的方式运行的。
每个批次只加载一次所有模型权重,
然后在批次中的每一个token上重复使用。
通常,LLM 的输入是计算密集型的,
而 LLM 的输出是内存密集型的。
当我们将输入和输出token,
与连续批处理结合起来时,
整个工作负载就变成了非常计算密集型。
Sohu描述了在“混合双打”方式下,
计算的密集程度变成了非常密集。
也就是very compute bound。
上一篇文章的评论区非常热闹,
有读者暗含“批评”意味的提出,
我把“算力部分将输入和输出简单加在一起算,
说明作者以为这两部分算力区别不大”。
我把道理写在这里,
作为一种回应。
因为Sohu选择“混合双打”,
所以,需要把输入和输出的算力加在“一起算”。
解析三:
已知条件批次大小是在哪里写的?
这道题不仅考英语,
还要考AI。
这点在他们的技术博客中,
确实藏得很深,
不好找。
就算是GPT翻译完,
也还要仔细理解。
你看,技术博客上说,

英文:
We can scale up the same trick to run
Llama-3-70Bwith 2048 input tokens
and 128 output tokens.

中文:
我们可以使用同样的技巧来运行具有2048 个输入token和128个输出token的Llama-3-70B 模型。

英文
Have each batch consist of 2048 input tokens for one sequence, and 127 output tokens for 127 different sequences.

中文
让每个批次包含一个序列的2048个输入token,和127个不同序列的127个输出token。
“127 output tokens for 127 different sequences.”
这话是说,
生成阶段(Decoding),
有127个样本,
(原文是:127个不同的序列)。
连序列都不同,
难道可能是相同的样本吗?
这句话使用助动词 “Have” ,
来营造更正式、更具指导性的语气,
这类似于给出诸如“确保”或“请确保”之类的指令。
这在需要传达精确性的技术写作中很常见。
说的这么头头是道,
别问我怎么知道的,
谷歌的Gemini告诉我的。
解析四:
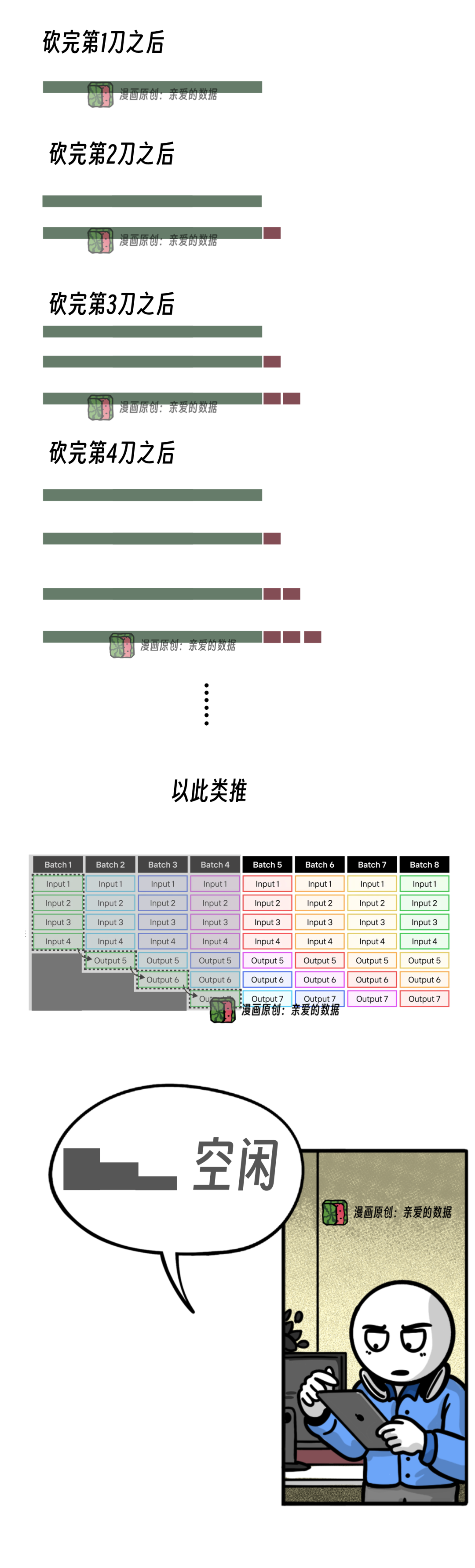
理解“微缩”示意图,
我要打一个比方,
每一个批次,就好比一截完整的房梁,128个批次,就是128根房梁。
任务是要把房梁砍成切菜用的案板。
这道题有四个规则。
一定要牢记,
第一段房梁就代表准备(Prefill),
好比一种预处理工作,
只能由木匠队长专门处理。
第二段房梁代表生成(Decoding),
只能由木匠队员专门处理。
第三,房梁先被分成两段,
先由工头砍大段(Prefill)。
队长砍完,队员才能接着砍(Decoding)。
顺序固定。
第四,无论是谁,每次
队长都只能砍一个长木头(Prefill),
队员也都只能砍一个短木头(Decode)。
话只能说到这里了,
后面就得画图了。
解析五:
如果没有KVCache这个东西,
会怎么样呢?
谭老师我能不能说,
谁不用KVCache,
谁就在搞笑么?
如果没有KVCache,
每个批次要算2048×128个词元,
而现在有了KVCache只要算2048+127个词元。
这是是一道数学题,
数学可以不会就是不会。
换个讲法,
从语文层面来讲,
一个正常人类阅读文章时候,
每多看一个字,
都要回头把之前刚读的每一个字都再读一遍吗?
那这人的记忆力得有多差。
而GPT这类模型是这么干的,
这是它工作的技术原理,
它在不停地计算关系,
以便做出更好的“预测(生成)”。
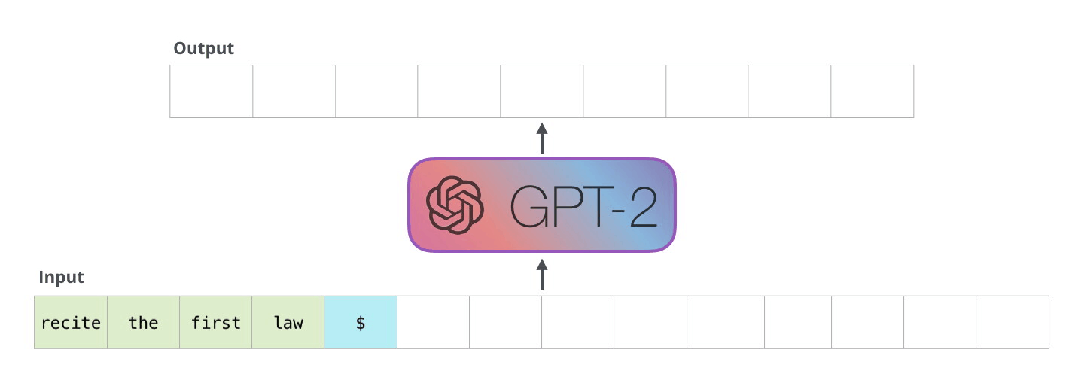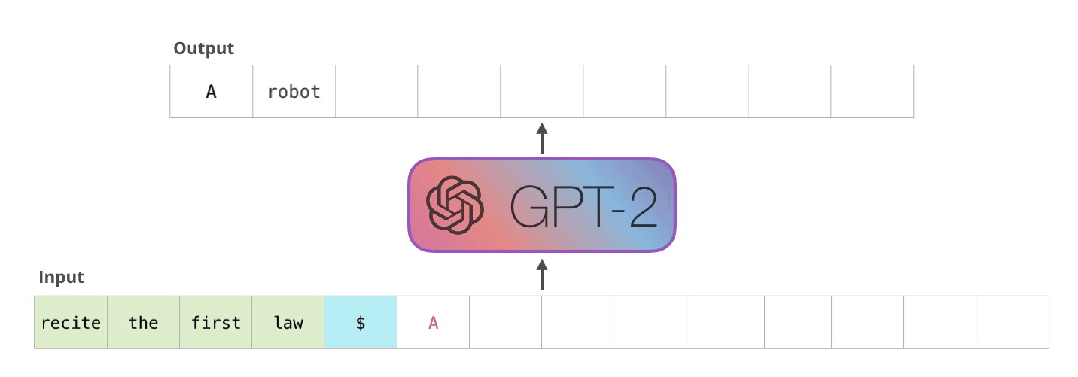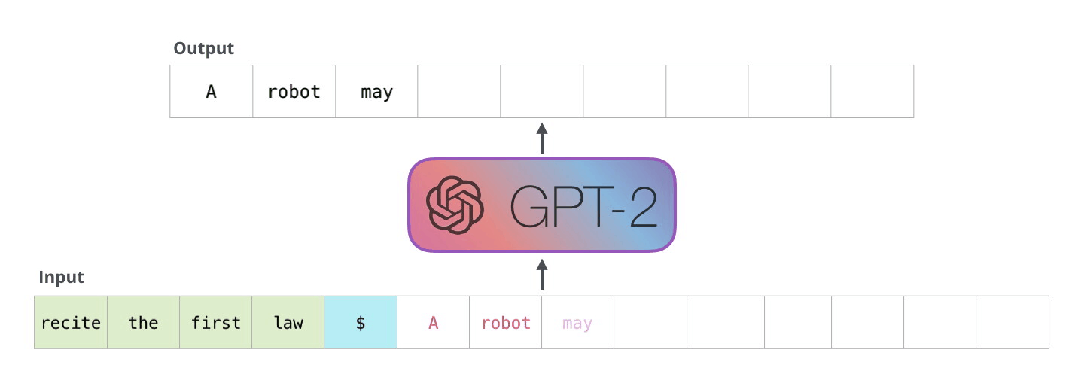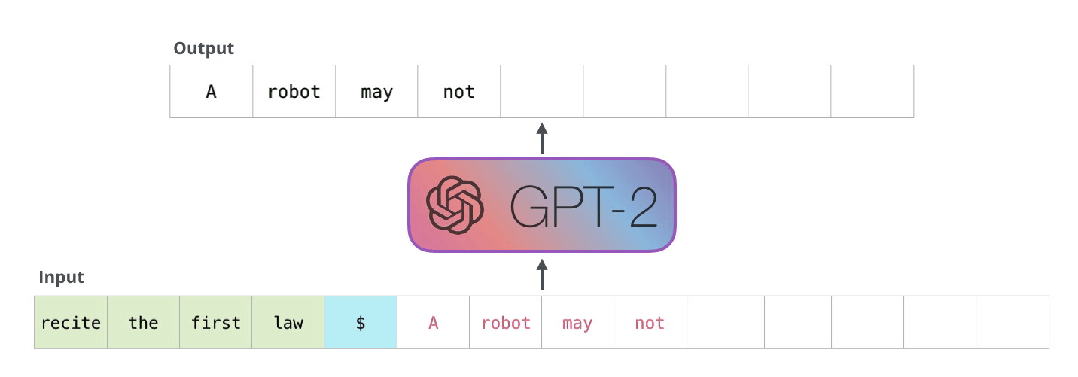
所以有很多重复计算,
得把重复计算处理好,
所以,现在大模型所面对的一堆问题中,
存的问题,比计算的问题还棘手。
KVCache技术还会再优化。
尤其是,
现在很卷,
KVCache会长期高位,
因为大模型公司它们要卷上下文长度。
(完)
One More Thing
在形式上创新这件事,
有位专家评价:风格狂野。
比如,写着写着,做了漫画。
还有些读者也看出来了,
留言说:
“这个写作方法确实很新颖,
而且读起来,更专注,
更深刻。换过来,
如果作者简单的把对话翻译过来,
可能我就没这么投入了。”
我想特意对这位读者,
说一声谢谢。

《我看见了风暴:人工智能基建革命》,
作者:谭婧



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









