





 数据透视表在数据分析中起到关键作用,Python的pandas库提供了强大的pivot_table功能。本文将探讨如何利用pandas实现数据透视,并介绍相关参数,帮助你理解和应用pd.pivot_table()进行数据汇总。
数据透视表在数据分析中起到关键作用,Python的pandas库提供了强大的pivot_table功能。本文将探讨如何利用pandas实现数据透视,并介绍相关参数,帮助你理解和应用pd.pivot_table()进行数据汇总。
透视表是一种可以对数据动态排布并且分类汇总的表格格式。对于熟练使用 excel 的伙伴来说,一定很是亲切!实际上,Python使用pandas同样可以快速实现数据透视表的功能,不同方法反应不同的编程思维,以下是几种实现数据透视表的简单方法。在实际应用中,需要注意(1)数据的获取,可以通过Python读取不同结构化数据;(2)理解掌握pd.pivot_table() 语法。
# -*- coding: utf-8 -*-
"""
Created on Fri Aug 21 16:11:37 2020
@author: Romer Lyu
"""
import pandas as pd
import numpy as np
v = [1,2,3,3,3]
a = pd.DataFrame({'v':v})
d = [2 , 4, 4, 5, 4]
a['d'] = d
c = ['c' , 'h', 'd', 'e', 'c']
a['c'] = c
# df用两列进行分组grouby
a.groupby(['v', 'd'])['c'].count()
'''
方法一
'''
#把这个v当作列index,d当作行columns,
#之后把对应的分组的’c‘.count()放到对应的索引loc处,
#不存在的值用0填补
cpd = pd.crosstab(a['v'], a['d'], a['c'], aggfunc='count')
# 填充空格
cpd = cpd.fillna(0)
#转换为array和list的方法
cpd_arr1 = np.array(cpd)
cpd_arr2 = np.array(cpd.values.tolist())
cpd_list = cpd.values.tolist()
'''
整体流程——>总结一句话
'''
cpd = pd.crosstab(a['v'], a['d'], a['c'], aggfunc='count')
cpd = cpd.fillna(0)
cpd_arr = np.array(cpd)
cpd_arr
#--------------#
np.array(pd.crosstab(a['v'], a['d'], a['c'], aggfunc='count').fillna(0))
'''
方法二 pivot()
'''
a.groupby(['v', 'd'], as_index=False)['c'].count()
a.groupby(['v', 'd'], as_index=False)['c'].count().pivot('v', 'd', 'c')
'''
整体流程——>总结一句话
'''
ppd = a.groupby(['v', 'd'], as_index=False)['c'].count().pivot('v', 'd', 'c')
ppd = ppd.fillna(0)
ppd_arr = np.array(ppd)
ppd_arr
#--------------#
np.array(a.groupby(['v', 'd'], as_index=False)['c'].count().pivot('v', 'd', 'c').fillna(0))
'''
第三种方法:pivot_table
'''
pivoted_df=pd.pivot_table(a[['v','d','c']],
values='c', index=['v'],
columns=['d'], aggfunc='count')
pivoted_df
np.array(pivoted_df.fillna(0))
以下是该函数的参数介绍:
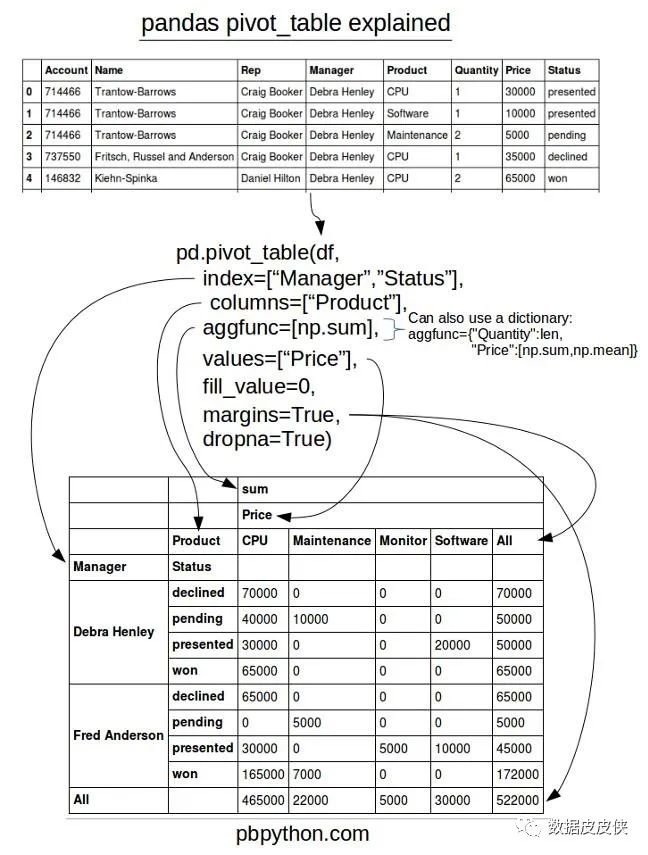
欢迎关注:数据皮皮侠



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









