



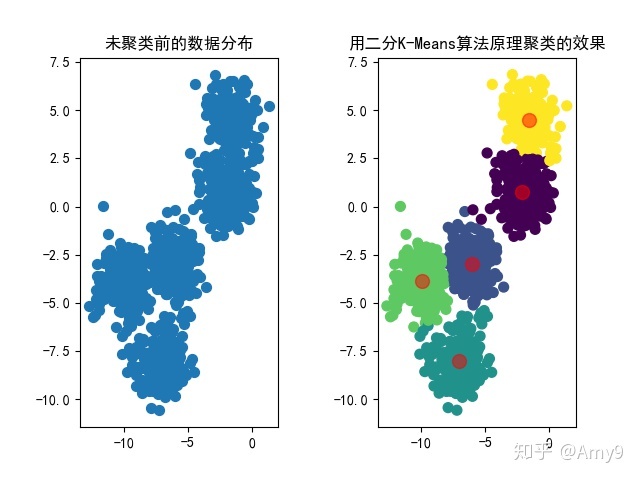
 为解决K-Means算法易陷入局部最优的问题,本文介绍了一种改进算法——二分K-Means。该算法从所有数据点作为单一簇开始,通过反复将簇一分为二来逐步降低误差平方和(SSE),直至达到指定的簇数量。
为解决K-Means算法易陷入局部最优的问题,本文介绍了一种改进算法——二分K-Means。该算法从所有数据点作为单一簇开始,通过反复将簇一分为二来逐步降低误差平方和(SSE),直至达到指定的簇数量。
为克服K-Means算法收敛于局部最小值问题,提出了二分K-Means算法
二分K-Means算法首先将所有点作为一个簇,然后将该簇一分为二。之后选择其中一个簇继续进行划分,选择哪一个簇进行划分取决于对其划分是否可以最大程度降低SSE的值。上述基于SSE的划分过程不断重复,直到得到用户指定的簇数目为止。
步骤
1. 将所有点看成一个簇;
2. 对每个簇,进行如下操作
计算总误差
在给定的簇上进行K-Means聚类(k=2)
计算将该簇一分为二之后的总误差
3. 选择使得误差SSE最小的那个簇进行划分操作
4. 重复2—3操作,直到达到用户指定的簇数目为止;
另一种做法是:选择SSE最大的簇进行划分,直到簇数目达到用户指定的数目为止。
python代码
import 结果如下
相关链接
K-Means算法链接

















 1049
1049

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









