






前言:
近期推出的嵌入式AI系列直播公开课受到广大开发者的喜爱,并收到非常多的反馈信息,其中对如何在EAIDK上面部署Tengine开发AI应用感兴趣的开发者不在少数,我们将分2期以案例实操的形式详细介绍。
Tengine开源版本GitHub链接 https://github.com/OAID/Tengine
欢迎Git
Clone!技术交流QQ群
829565581
,群里各位大佬坐镇,日常技术讨(
shui)
论(
qun)
~~
 AI推动了社会智能化的发展进程,极大的提高了人们的工作效率,节省了工作时间。在AI赋能社会的同时,作为开发者也要了解AI如何从0到1,1到2,乃至2到3等的过程。
作为刚接触AI开发的开发者而言,了解AI的开发框架是至关重要的。AI的开发是一项庞大的系统性的工程,开发人员需要掌握一定的数学原理,编程能力,建模能力与数据分析能力等。AI开发的整体框架如图1所示:
AI推动了社会智能化的发展进程,极大的提高了人们的工作效率,节省了工作时间。在AI赋能社会的同时,作为开发者也要了解AI如何从0到1,1到2,乃至2到3等的过程。
作为刚接触AI开发的开发者而言,了解AI的开发框架是至关重要的。AI的开发是一项庞大的系统性的工程,开发人员需要掌握一定的数学原理,编程能力,建模能力与数据分析能力等。AI开发的整体框架如图1所示:
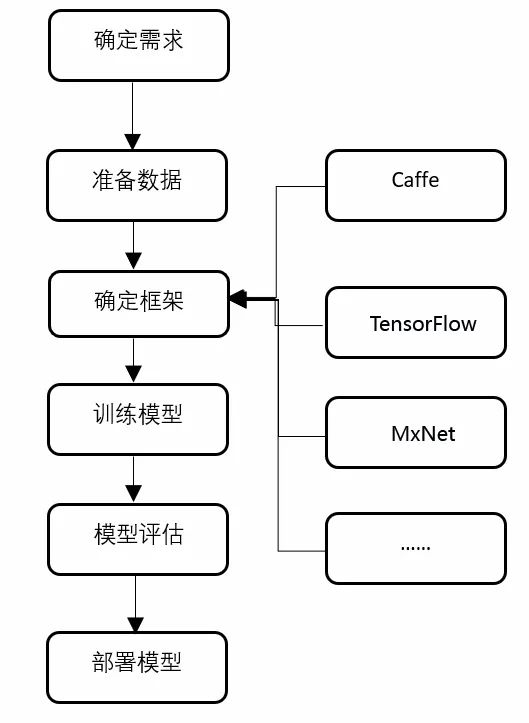 图1 AI开发框架图
对于新开发者而言,先从相对简单的部署模型阶段学习,可以快速了解整个AI系统的运作,以及了解AI如何在人们的日常生活中产生实际作用。
图1 AI开发框架图
对于新开发者而言,先从相对简单的部署模型阶段学习,可以快速了解整个AI系统的运作,以及了解AI如何在人们的日常生活中产生实际作用。



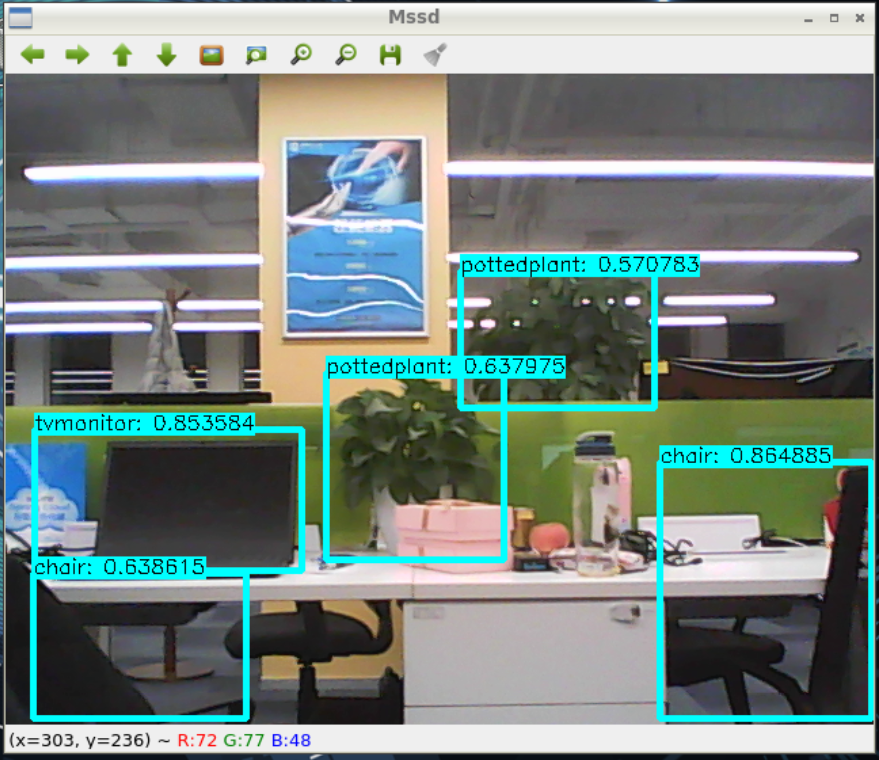 图3 Demo 运行效果
图3 Demo 运行效果
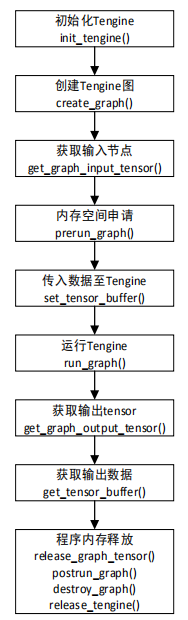 图 4 C++ Demo 流程图
库文件包含
图 4 C++ Demo 流程图
库文件包含
 用命令来查询端口设备信息:
用命令来查询端口设备信息:
欢迎您加入EAIDK开发者大本营,
AI推动了社会智能化的发展进程,极大的提高了人们的工作效率,节省了工作时间。在AI赋能社会的同时,作为开发者也要了解AI如何从0到1,1到2,乃至2到3等的过程。
作为刚接触AI开发的开发者而言,了解AI的开发框架是至关重要的。AI的开发是一项庞大的系统性的工程,开发人员需要掌握一定的数学原理,编程能力,建模能力与数据分析能力等。AI开发的整体框架如图1所示:
图1 AI开发框架图
对于新开发者而言,先从相对简单的部署模型阶段学习,可以快速了解整个AI系统的运作,以及了解AI如何在人们的日常生活中产生实际作用。
一、EAIDK常见的模型部署方式
对于现在市场上的AI框架而言,具有群雄争锋的局面,有 Caffe,PyTorch,TensorFlow,MxNet,ONNX 等一系列耳熟能详的训练与推理框架,但经过这些训练框架所训练出的模型在性能,精度,以及不同平台的适应性也各有千秋。对于初学者而言,从推理框架入手是一种很好的选择,在学习推理框架的同时,可以帮助初学者了解AI的整套体系是如何运作的。 在选择推理框架的时候需要结合现今模型部署的环境进行考虑。往日的AI模型训练常见于PC端,其往往忽略运行模型对于资源的调度,模型对于其加载设备功耗的使用。在AI的发展路程上,越来越多的开发者希望AI能融入我们的生活,所以对于PC端的推理框架部署则越来越不被人们所接受。AI从往日的PC端,需要渐渐的转化到可移动设备端。在现今生活中,通过社会各界不断的努力,AI逐渐被人们所熟悉,例如人脸门禁检测系统,工业自动化中的物体分拣检测系统,以及现在众所周知的无人驾驶项目等一系列贴近人们生活的具体项目。 EAIDK 常见的模型部署方式如下: ◢ 部署原始训练框架 直接部署原始训练框架具有如下特点: 1) 需安装如TensorFlow/PyTorch/Caffe等环境; 2) 推理性能差; 3) 很多冗余功能; 4) 内存占用大; ◢ 手动模型重构 不依赖框架,手写C/C++代码,实现计算图,并导入权重数据。该种方法需要构造者对模型有充分的了解。对初学者而言,有一定的技术难度。 ◢ 使用TensorFlow-Lite/PyTorch-Mobile等训练框架的部署引擎 除了直接部署原始的训练框架,训练框架也有一些部署引擎,如TensorFlow 训练框架有TensorFlow-Lite ,PyTorch 训练框架有PyTorch-Mobile. 使用这些部署引擎具有如下问题: 1) 只支持自己框架训练的模型; 2) 需要进行模型转换; 3) 支持硬件/OS有限; ◢ 使用Tengine推理框架进行部署 Tengine推理框架具有如下特点: 1) 可以直接加载主流框架模型,也支持主流框架模型直接转换为Tengine模型, Tengine提供一键转换工具; 2) 只依赖C/C++库,无任何第三方库依赖; 3) 自带图像处理已支持图像缩放、图像像素格式转换、旋转、镜像翻转、映射、腐蚀膨胀、阈值处理、高斯模糊处理、图像编解码等; 4) 自带语音处理(Roadmap)支持FFT/IFFT、MFCC等信号处理方式,方便完成噪声抑制、回声清除等语音处理工作; 5) 支持Android/Linux/RTOS/裸板环境; 6) PyThon/C++/AAP 等API接口,方便不同语言调用; 7) 高性能计算,在板子上也可以跑出炫酷的Demo; 8) 无需手动安装,EAIDK自带Tengine环境,直接使用即可。 快速上手教程:物体检测应用入门(C版本)
二、Tengine 环境搭建
a. Tengine预编译库
EAIDK自带Tengine预编译库,无需手动编译。 Tengine预编译库路径:/usr/local/AID/Tengine/[openailab@localhost ~]$ ls /usr/local/AID/Tengine/lib/libhclcpu.so libtengine.so[openailab@localhost ~]$ ls /usr/local/AID/Tengine/include/cpu_device.h tengine_c_api.h tengine_c_compat.h tengine_operations.hb. Tengine版本信息
输入下列命令可以查看Tengine版本信息:sudo dnf info TengineName : tengineVersion : 1.7.1Release : 1.openailab.fc28Arch : aarch64Size : 5.8 MSource : tengine-1.7.1-1.openailab.fc28.src.rpmRepo : @SystemSummary : openailab tengine libraryURL : https://github.com/OAID/Tengine…sudo dnf updateTengine三、Tengine物体检测Demo(C++)
a. Demo 简介
对EAIDK初学者进行物体检测的环境搭建与运行,其目的是让初学者对Tengine在物体检测方面进行学习,为后期开发做好铺垫. 此指导教学为运用EAIDK自带后方摄像头进行图像的拍摄,可对图像中的物体进行检测,例如人,瓶子等.在此教学中运用了Tengine相关的函数以及运用OpenCV对图像检测方面的前后处理进行基础的教学指导.b. 运行环境
安装环境需要在root权限下:sudo sui. 安装OpenCV
依据以下指令安装OpenCV依赖库sudo yum install opencvsudo yum install opencv-develprotobuf-3.5.0-4.fc28.aarch64protobuf-compiler-3.5.0-4.fc28.aarch64protobuf-devel-3.5.0-4.fc28.aarch64 sudo dnf install protobuf-compiler-3.5.0-4.fc28.aarch64sudo dnf install protobuf-3.5.0-4.fc28.aarch64sudo dnf install protobuf-devel-3.5.0-4.fc28.aarch64yum install v4l-utilsc. Demo 编译与运行效果
i. 创建目录
目录Demo下进行编写,其路径:/home/openailab/Demo[openailab@localhost ~]$ mkdir mobilenetSSD[openailab@localhost ~]$ cd mobilenetSSD[openailab@localhost ~]$ mkdir modelsii. 转换模型
在models 文件夹中,执行如下命令,将caffe模型转换为Tengine模型。export LD_LIBRARY_PATH=/usr/local/AID/Tengine/lib/./convert_model_to_tm -f caffe -p models/MobileNetSSD_deploy.prototxt -m models/MobileNetSSD_deploy.caffemodel -o models/tm_mssd.tmfileiii. 编译
回到 mobilenetSSD 目录,编译可执行文件。g++ mobilenet_ssd.cpp `pkg-config --libs --cflags opencv` -I /usr/local/AID/Tengine/include/ -L /usr/local/AID/Tengine/lib -l tengine -o mssdiv. 设置多核运行
设置高性能运行程序可用以下环境变量来设定,默认为1核运行,可设置成6核运行该程序:export TENGINE_CPU_LIST=0,1,2,3,4,5 ./mssdd. Demo 代码解析
此Demo通过调用Tengine各接口进行读取模型、图的创建等功能,其软件流程图如图4所示:
图 4 C++ Demo 流程图
库文件包含
#include #include #include #include #include "opencv2/opencv.hpp"#include "opencv2/core/core.hpp"#include "opencv2/highgui/highgui.hpp" #include #include "tengine_c_api.h"int main(int argc, char* argv[]){int ret = -1;std::string model_file = "models/tm_mssd.tmfile ";if(init_tengine() < 0) {std::cout << " init tengine failed\n";return 1; }graph_t graph = create_graph(nullptr, "tengine", model_file.c_str());if(graph == nullptr) {std::cout << "Create graph failed\n";std::cout << " ,errno: " << get_tengine_errno() << "\n";return 1; }int node_idx = 0;int tensor_idx = 0;tensor_t input_tensor = get_graph_input_tensor(graph, node_idx, tensor_idx);if(input_tensor == nullptr) {std::printf("Cannot find input tensor,node_idx: %d,tensor_idx: %d\n", node_idx, tensor_idx);return -1; }int img_h = 300;int img_w = 300;int channel = 3;int img_size = img_h * img_w * channel;float* input_data = ( float* )malloc(sizeof(float) * img_size);int dims[] = {1, channel, img_h, img_w};set_tensor_shape(input_tensor, dims, 4);ret = prerun_graph(graph);if(ret != 0) {std::cout << "Prerun graph failed, errno: " << get_tengine_errno() << "\n";return 1; }cv::Mat frame;cv::VideoCapture capture(0);v4l2-ctl -d /dev/video4 --allv4l2-ctl -d /dev/video4while(1){capture >> frame;get_input_data_ssd(frame, input_data, img_h, img_w);void get_input_data_ssd(cv::Mat img, float* input_data, int img_h, int img_w) {cv::resize(img, img, cv::Size(img_h, img_w));img.convertTo(img, CV_32FC3);float* img_data = ( float* )img.data;int hw = img_h * img_w;float mean[3] = {127.5, 127.5, 127.5};for(int h = 0; h < img_h; h++) {for(int w = 0; w < img_w; w++) {for(int c = 0; c < 3; c++) {input_data[c * hw + h * img_w + w] = 0.007843 * (*img_data - mean[c]);img_data++; } } } }int main(){...}set_tensor_buffer(input_tensor, input_data, img_size*sizeof(float));run_graph(graph, 1);tensor_t out_tensor = get_graph_output_tensor(graph, 0, 0);int out_dim[4];ret = get_tensor_shape(out_tensor, out_dim, 4);if(ret <= 0) {std::cout << "get tensor shape failed, errno: " << get_tengine_errno() << "\n";return 1; }float* outdata = ( float* )get_tensor_buffer(out_tensor);int num = out_dim[1];float show_threshold = 0.5;post_process_ssd(frame, show_threshold, outdata, num);#include "tengine_c_api.h"struct Box{float x0;float y0;float x1;float y1;int class_idx;float score;};void post_process_ssd(cv::Mat img, float threshold, float* outdata, int num) {const char* class_names[] = {"background", "aeroplane", "bicycle", "bird","boat","bottle","bus", "car", "cat", "chair","cow", "diningtable", "dog", "horse","motorbike", "person", "pottedplant", "sheep", "sofa", “train", "tvmonitor"};int raw_h = img.size().height;int raw_w = img.size().width;std::vector boxes;int line_width = raw_w * 0.005;for(int i = 0; i < num; i++) {if(outdata[1] >= threshold){Box box;box.class_idx = outdata[0];box.score = outdata[1];box.x0 = outdata[2] * raw_w;box.y0 = outdata[3] * raw_h;box.x1 = outdata[4] * raw_w;box.y1 = outdata[5] * raw_h;boxes.push_back(box);printf("%s\t:%.0f%%\n", class_names[box.class_idx], box.score * 100);printf("BOX:( %g , %g ),( %g , %g )\n", box.x0, box.y0, box.x1, box.y1);}outdata += 6; }for(int i = 0; i < ( int )boxes.size(); i++) {Box box = boxes[i];cv::rectangle(img, cv::Rect(box.x0, box.y0, (box.x1 - box.x0), (box.y1 - box.y0)), cv::Scalar(255, 255, 0),line_width);std::ostringstream score_str;score_str << box.score;std::string label = std::string(class_names[box.class_idx]) + ": " + score_str.str();int baseLine = 0;cv::Size label_size = cv::getTextSize(label, cv::FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);cv::rectangle(img,cv::Rect(cv::Point(box.x0, box.y0 - label_size.height),cv::Size(label_size.width, label_size.height + baseLine)),cv::Scalar(255, 255, 0), CV_FILLED);cv::putText(img, label, cv::Point(box.x0, box.y0), cv::FONT_HERSHEY_SIMPLEX, 0.5, cv::Scalar(0, 0, 0));} }int main(){...}release_graph_tensor(out_tensor);imshow("Mssd", frame);cv::waitKey(10);}release_graph_tensor(input_tensor);ret = postrun_graph(graph);if(ret != 0) {std::cout << "Postrun graph failed, errno: " << get_tengine_errno() << "\n";return 1; }free(input_data);destroy_graph(graph);release_tengine();return 0; }完
点击获取Tengine开源版本
欢迎Git Clone!
https://github.com/OAID/Tengine欢迎您加入EAIDK开发者大本营,
里面不仅有EAIDK大神
更有大量神秘大牛等你勾搭哦!
———————————————

EAIDK开发者大本营
(QQ群:625546458)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









