






 本文深入探讨了Python的全局解释器锁(GIL),解释了它的作用、优缺点,以及如何影响多线程执行。GIL使得在多核处理器上Python解释器在同一时间仅执行一个线程,简化了C扩展库的开发,但也限制了多核并行执行。文章介绍了Python3.2之前的基于ticks的GIL切换机制和之后基于时间片的切换,以及新GIL对I/O性能的影响。尽管存在GIL,多线程在某些场景下仍能提供良好的性能,但对于多核处理器,需要理解GIL带来的限制。
本文深入探讨了Python的全局解释器锁(GIL),解释了它的作用、优缺点,以及如何影响多线程执行。GIL使得在多核处理器上Python解释器在同一时间仅执行一个线程,简化了C扩展库的开发,但也限制了多核并行执行。文章介绍了Python3.2之前的基于ticks的GIL切换机制和之后基于时间片的切换,以及新GIL对I/O性能的影响。尽管存在GIL,多线程在某些场景下仍能提供良好的性能,但对于多核处理器,需要理解GIL带来的限制。
Python的全局解释器锁
全局解释器锁(GlobalInterpreter Lock,缩写GIL),是解释器同步线程的一种机制,它使得任何时刻仅有一个线程在执行。 即便在多核心处理器上,使用GIL 的解释器也只允许同一时间执行一个线程。 常见的使用GIL 的解释器有CPython与Ruby MRI。
Python解释器是一个进程,全局解释器锁用于给编译后的字节码程序上个锁,以便只有一个线程在一个时段执行这个程序。这意味着即使具有多个CPU内核的多线程体系结构中,在任何时间点也只能有一个线程运行。
Python用GIL这把大锁,锁住了整个线程,从而实现多任务的合作执行。这样做有优点也有缺点。
GIL的优点:
这种一把大锁的最大优点是容易实现。其实Python问世时操作系统还没有线程的概念。Python的宗旨是易于使用,以加快开发速度,果然越来越多的开发人员开始使用它。
由于只用一把大锁来解决问题,所以不同社区的可以容易地写出不同的应用,使得Python的C扩展库极为丰富。可以这样说,GIL是一个历史现象,是CPython开发人员在Python生命早期面临一个难题时的务实解决方案。也正是得益于此,Python才有现在的成功。
另外,GIL由于只需要管理一个锁,因此它可以提高单线程程序的性能。
GIL的缺点:
对于多核处理器来说,GIL不能很好地解决线程在多核上的并行执行,而随着物理尺寸极限的到来,单核CPU性能的提高越来越难,所以多核处理器越来越占据C位!
大佬David Beazley曾经做过一个实验,验证不同数量的线程在不同处理器的运行时间

程序如下:
from threading import Threadimport timedef countdown(n): whilen > 0: n -= 1COUNT = 100000000 # 100 milliont_start = time.time()countdown(COUNT)print(f'sequential time is{time.time()-t_start}')t1 = Thread(target=countdown,args=(COUNT//2,))t2 = Thread(target=countdown,args=(COUNT//2,))t_start = time.time()t1.start(); t2.start()t1.join(); t2.join()print(f'2 threads time is{time.time()-t_start}')t1 = Thread(target=countdown,args=(COUNT//4,))t2 =Thread(target=countdown,args=(COUNT//4,))t3 =Thread(target=countdown,args=(COUNT//4,))t4 =Thread(target=countdown,args=(COUNT//4,))t_start = time.time()t1.start(); t2.start();t3.start();t4.start()t1.join(); t2.join();t3.join(); t4.join()print(f'4 threads time is{time.time()-t_start}') 说实话,我也在自己的电脑上运行了,我的电脑是Thinkpad T450s,I5-5300u,双核CPU,WIN10,运行得出的结果却不一样:
sequential time is 6.1884415149688722 threads time is 6.1984374523162844 threads time is 6.2104058265686035串行与后面的多线程运行时间一样!这是因为我的Python版本是3.9的原因, GIL已经做了重大修改。
GIL的历史
David Beazley做实验是在2010年,应该是在旧的GIL下运行的结果。就在那一年GIL做了重大修改,Python发布了3.2版本。我们就沿着历史,仔细探究一下GIL的更多细节。
GIL机制的细节
Python锁
用C语言编写的Python解释器只提供了一个锁类型,构建了所有线程的同步原语。它不是一个简单的互斥锁,而是由一个Pthread的互斥锁和条件变量构成的一个二进制信号量。GIL是这种锁类型的一个实例。
锁由三部分组成
locked = 0 # Lock statusmutex = pthreads_mutex() # 这个互斥锁用于lock状态设置cond = pthreads_cond() # 用于等待/唤醒 函数acquire()和release()用于获得和释放GIL,其伪代码如下:
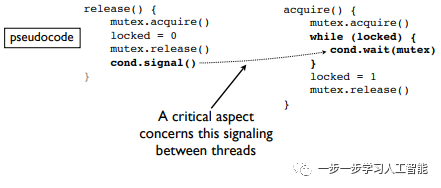
注意线程之间的信号很关键
下面我们将分析GIL的同步线程机制。在讲GIL之前,先看看Python线程及其工作机制。
Python线程
Python线程其实是系统线程:它可以是一个跨平台的POSIX线程(pthreads),也可以是一个windows线程。它完全由主操作系统管理。Cpython解释器实际是一个用C语言写的进程,Python的线程在其中执行。
GIL下的线程执行模型
GIL禁止并行执行:有一个全局解释器锁小心地控制着线程执行,以确保解释器一次只能执行一个线程。GIL简化了许多底层的细节(比如内存管理,对C扩展的调用等)。
使用GIL,可以合作执行多个任务。一个运行的线程持有GIL,当遇到I/O操作时(比如读,写,发送,接收等操作),线程释放GIL:
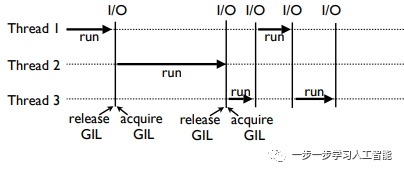
Python3.2之前的GIL(基于ticks的切换)
Python3.2 之前是基于虚拟机指令数量的调度方式。为了简化叙述,我们将调度分为两种:
﹒ CPU-BOUND型线程,意思是这个线程运行高度依赖CPU,有人译为CPU密集型,我这里译为CPU捆绑型线程。﹒ I/O-BOUND,这种线程主要用于输入/输出操作,比如网络与硬盘的数据读写,可以译为I/O密集型线程。一,CPU捆绑型任务
没有任I/O操作的CPU捆绑型线程比较特殊,通常每隔100个ticks检查一次, 这个间隔周期可以用sys.setcheckinterval()来修改:
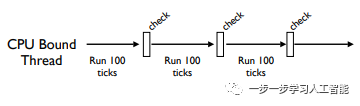
啥是tick?
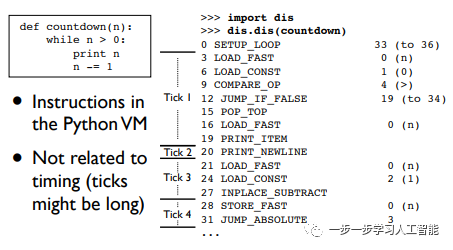
Python定义了一个完全独立于线程调度的全局tick计数器。一条Python的虚拟机指令为一个tick,它与时间并不相干。一条虚拟机指令可以包括多条汇编指令,有时,一条长的Python操作指令很长,这段时间一切其它操作都会被阻塞:
>>> list(range(200000000))[-1] # 这里1 tick大概是13.86秒199999999 这期间,我想用Ctrl-C强制中断运行,但并不如愿!因为tick是不能中断的。
>>> list(range(200000000))[-1]^C^C # 运行时,按下Ctrl-C没有反应,也没有任何显示...KeyboardInterrupt 我们对一段Python代码反汇编,会看到1 tick可以包含多条汇编指令:
Check过程
线程会在tick计数器到达 100 之后释放GIL, 给其他线程一个获得GIL的机会。检查过程其实蛮简单:
首先重新设置计数器如果是主线程就运行信号处理器释放GIL重新获取GIL 其程序如下:

线程切换分析
操作系统调度
操作系统有一个将要运行的线程/进程的优先级队列捕获了信号的线程只是进入了这个队列操作系统然后运行具有最高优先级的队列它或许是,也或许不是那个捕获了信号的线程/进程线程切换
假定有两个线程,线程1运行,线程2处于等待GIL状态
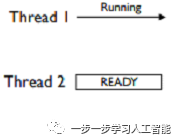
线程1执行I/O(比如读写)操作,它可能会阻塞,便释放GIL。

1,比较简单的情况是:
线程1执行I/O(比如读写)操作,释放GIL引起一个信号操作,信号操作由线程库和操作系统处理:
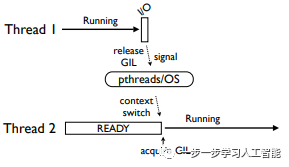
2,比较麻烦的是:
线程1没有I/O操作,一直运行到检查时段,接着两个线程都可能运行:
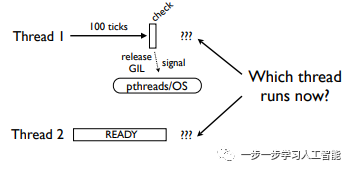
到底会运行哪一个线程呢?
Pthread的秘密
条件变量(Condition variables)有一个内部线程等待队列,它有两个口,因而是先进先出。系统收到信号后就从队列中弹出一个线程:
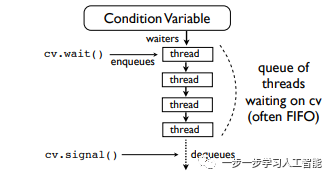
但弹出后又怎么操作呢?
系统调度
操作系统有一个准备运行的具有优先级的线程/进程队列,获得信号的线程只是简单地加入队列,而操作系统要运行的是优先级最高的线程或进程。它可能是也可能不是那个获得了信号的进程。
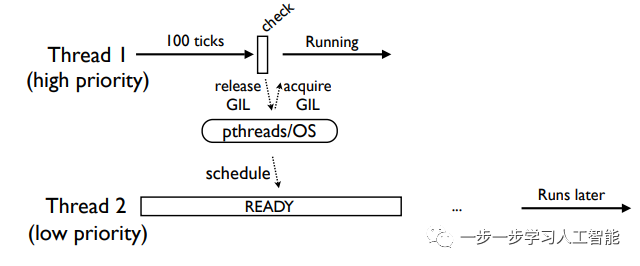
第一种情况
线程1继续运行,线程2移到系统的准备队列,过段时间才能执行:
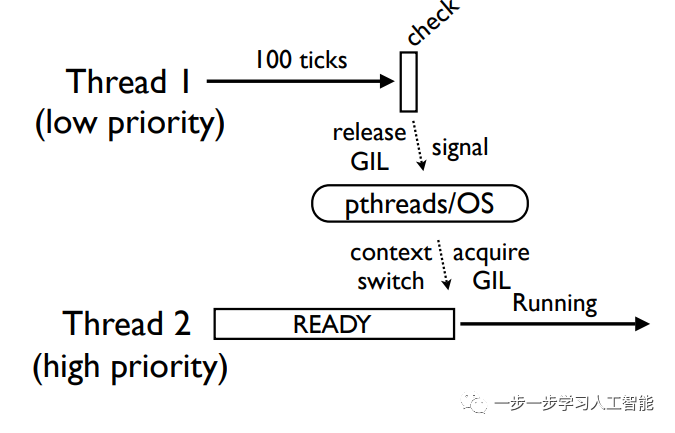
第二种情况
线程2的优先级最高,它会立即接管运行:
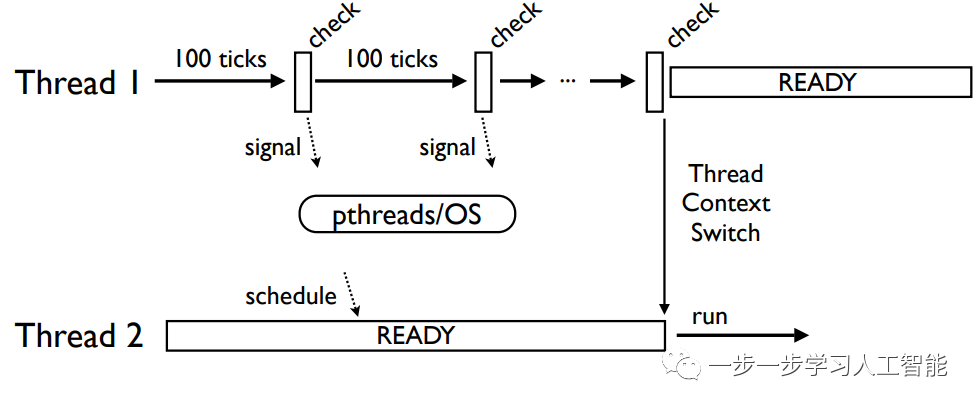
单核CPU线程的线程切换
线程交替执行,但切换的频率比您想象的要低得多,在线程上下文切换之前,可能会发生成百上千次的检查(这很有益处)
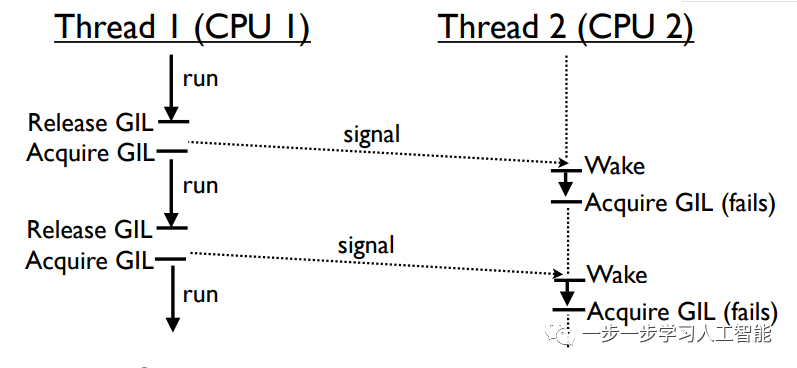
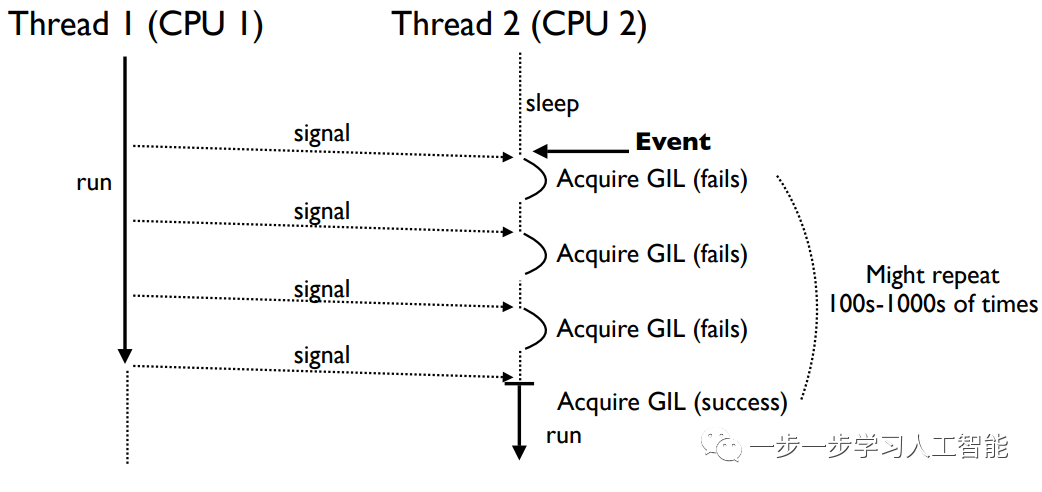
多核情况下的GIL竞争
在多核的情况下,可运行线程同时在不同的核上调度,并争夺GIL。线程2反复接收信号,但是当它醒来时,GIL可能已经被线程1重新获得了,所以总是不能获得GIL:
多核事件处理
CPU捆绑的线程使得那些想要处理事件的线程很难获得GIL
二,I/O行为
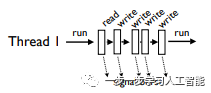
I/O 操作通常并不会阻塞。因为缓冲的原因,操作系统能够立即满足 I/O 需求,并保持一个线程的运行。但是 GIL 却总是释放,频繁的释放和获取导致GIL剧烈抖动(时密又时疏)。
Python3.2后的GIL
(基于时间片的切换)
Python3.2有一个新的GIL实现,它是基于时间片的切换。这是自Python线程1992年创建以来的首次重大改革,它旨在解决GIL所有槽点,它是安托万·皮特鲁(Antoine Pitrou)的作品。让我们一探究竟:
新线程切换
用一个全局变量替代ticks:
/* Python/ceval.c */ ...static volatile int gil_drop_request = 0; 线程会一直运行到这个值被置为1,而后线程必须放弃GIL.那到底是如何实现的呢?
新线程分析
假定只有一个线程运行,那么它会一直运行,不用释放GIL,不用发出任何信号:

假定有了第二个线程Thread 2,它没有GIL,所以被挂了起来。它必须从线程1获得GIL。
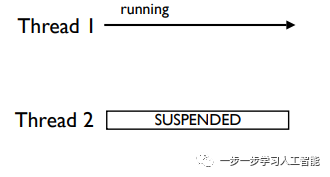
正在等待的线程运行cv_wait函数定时等待GIL。也就是说,线程2等待线程1自愿释放GIL。线程1释放的原因或许是因为有输入/输出操作,或许是因为某种原因而休眠。

TIMEOUT的默认设置是5ms,但也可以改变
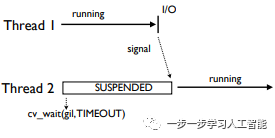
一种简单的情况,当第一个线程进行I/O操作时,它自愿释放GIL,第二个线抓住了GIL:
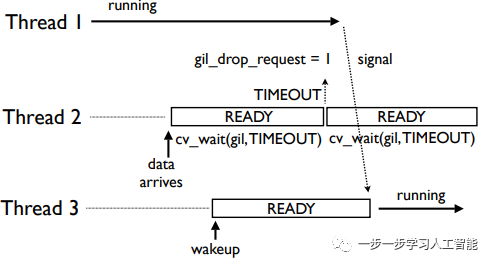
如果等待时间超时,那么系统将变量gil_drop_request置1,线程2重新开始新一轮的等待:
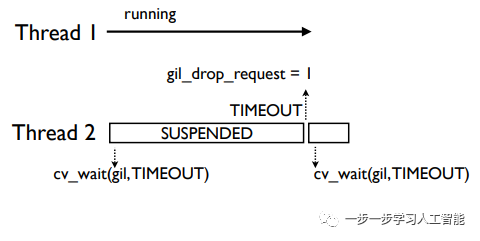
在系统将变量gil_drop_request置1后,线程1就被挂起来,然后发送信号表示GIL被它释放了:
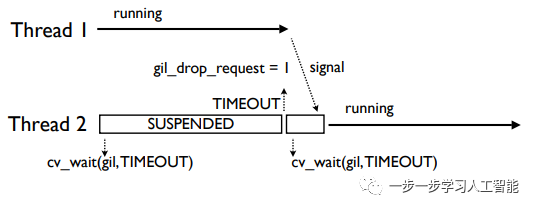
当线程强制释放后,它会等待一个应答信号。当其它线程成功获得GIL并开始运行时,它就会发出一个应答信号。这就消除了“GIL冲突”:
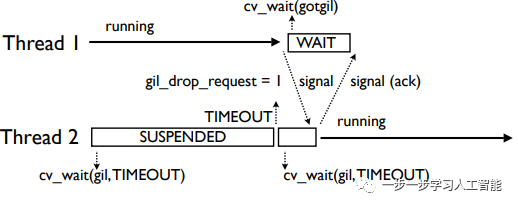
而后,线程1一直会重复这个过程。所以,当CPU捆绑的线程执行时,这种超时序列会一次又一次地发生。
这种GIL的效果还是挺明显地,对于我们的例子,我的电脑的串行和多线程运行结果都是6.2s左右(请看前面的部分)。
虽然有所改善,但在常见的应用中,Python仍然受到GIL的限制,多线程的性能仍然没有多大的提升。
新GIL影响I/O性能
新GIL影响I/O性能,我们来看一段网络代码:

一个线程正工作于CPU捆绑模式,另一个线程接受并回显套接字上的数据:新的GIL实际增加了响应时间。如果I/O或事件没有高的优先级,线程2必须跨越整个超时序列才能处理I/O操作:
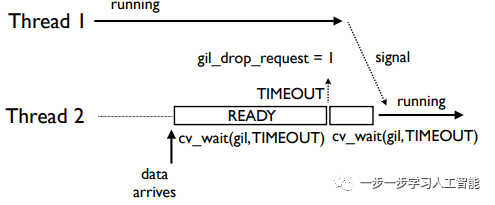
不公平的唤醒和空等
大多数应该得到的线程可能得不到GIL,这是由于内部条件变量排队导致的,这进一步增加了响应时间:
车队效应 (Convoyeffect):
用这种GIL,即使不阻塞的 I/O 操作也会卡顿,请看下图:
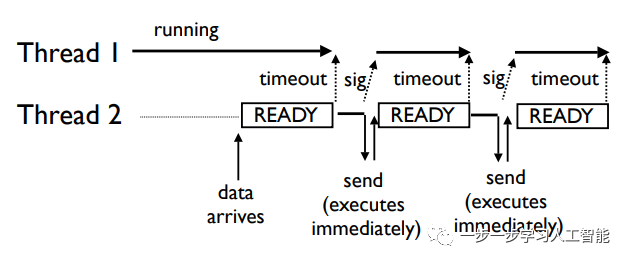
因为不阻塞的 I/O 操作完成后,总是释放 GIL,CPU 绑定的线程又总是试图重新获得 GIL。不阻塞的 I/O 操作几乎是立即完成,然后释放 GIL 给线程1,线程1有一个长度为timeout的延时,这个时间段线程2就处于空等待状态。
在这种情况下,CPU和I/O 设备并没有得到有效的利用。至于这个Convoy effect的准确翻译和意思,可以查看一下网络与。
实验一下
发送10MB 的数据到回显服务器线程,这个线程与一个CPU绑定线程竞争:
Python 2.6.4 (2 CPU) : 0.57s (10次采样的平均值)Python 3.2 (2 CPU) : 12.4s (新的GIL机制,比老的慢了20多倍) 如果回显线程与2个 CPU 绑定线程竞争呢?
Python 2.6.4 (2 CPU) : 0.25s (看起来比较好)Python 3.2 (2 CPU) : 46.9s (我去,比老GIL慢了40多倍)Python 3.2 (1 CPU) : 0.14s (单核比2核快了330多倍) 这足以说明新的GIL机制的优缺点够了!
GIL完善思路
这里展示的新GIL已经有相当大的改进,但是还需要进一步完善:
﹒优先级:必须有某种方法将CPU绑定(低优先级)和 I/O绑定(高优先级)的线程分开处理。﹒抢占:高优先级线程必须能够立即抢占低优先级线程。解决办法
操作系统使用超时来自动调整任务优先级(多级反馈排队)
﹒如果一个线程被超时抢占,它的优先级就会降低﹒如果一个线程挂起得早,它的优先级就会提高﹒高优先级线程总是抢占低优先级线程 也许这一思路能用于新的GIL。
还是干脆不要GIL了?
这整个讨论都是关于一个锁的实现问题。由于历史原因,用删除GIL来修改Python非常困难!有多少个理由去删除它,就有多少个实际的理由留下它!
最后说一下
不要因为这篇文章就决定不用多线程!对于许多并发问题,多线程是一种非常有用的编程工具。即便使用GIL,多线程也可以提供出色的性能,只是您需要花点力气去研究它。
但是,你应该了解一些棘手的极端情况。
多核处理器不会消失。所以,改进GIL是所有Python程序员都应该关心的事情。
您自己可能不使用线程,但是在你可能使用的框架和库中,它们被用于各种底层实现。无论如何,对线程行为更多点了解是有好处的。
请注意,实际上只是Cpython和PyPy有GIL的问题。Jython和IronPython没有GIL。作为一名Python开发人员,除非您正在编写C扩展,否则通常不会遇到GIL。C扩展编写者需要在其扩展阻塞I/O时释放GIL,以便让Python进程中的其他线程有机会运行。

















 630
630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









