






 本文探讨了在编程中遇到的函数调用参数过多的问题,以及如何通过利用for循环实现批量插入数据的方法,以提高效率。同时,针对递归调用层数过多导致的性能下降,提出了相应的优化思路。
本文探讨了在编程中遇到的函数调用参数过多的问题,以及如何通过利用for循环实现批量插入数据的方法,以提高效率。同时,针对递归调用层数过多导致的性能下降,提出了相应的优化思路。
在开发软件的过程中我们经常会遇到错误,如果你用 Google 搜过出错信息,那你多少应该都访问过Stack Overflow这个网站。作为全球最大的程序员问答网站,Stack Overflow 的名字来自于一个常见的报错,就是栈溢出(stack overflow)。本篇我们就从程序的函数调用开始,讲讲函数间的相互调用,在计算机指令层面是怎么实现的,以及什么情况下会发生栈溢出这个错误。为什么我们需要程序栈?和前面几篇一样,我们还是从一个非常简单的 C 程序 function_example.c 看起。
// function_example.c#include int static add(int a, int b){ return a+b;}int main(){ int x = 5; int y = 10; int u = add(x, y);}$ gcc -g -c function_example.c$ objdump -d -M intel -S function_example.oint static add(int a, int b){ 0: 55 push rbp 1: 48 89 e5 mov rbp,rsp 4: 89 7d fc mov DWORD PTR [rbp-0x4],edi 7: 89 75 f8 mov DWORD PTR [rbp-0x8],esi return a+b; a: 8b 55 fc mov edx,DWORD PTR [rbp-0x4] d: 8b 45 f8 mov eax,DWORD PTR [rbp-0x8] 10: 01 d0 add eax,edx} 12: 5d pop rbp 13: c3 ret 0000000000000014 :int main(){ 14: 55 push rbp 15: 48 89 e5 mov rbp,rsp 18: 48 83 ec 10 sub rsp,0x10 int x = 5; 1c: c7 45 fc 05 00 00 00 mov DWORD PTR [rbp-0x4],0x5 int y = 10; 23: c7 45 f8 0a 00 00 00 mov DWORD PTR [rbp-0x8],0xa int u = add(x, y); 2a: 8b 55 f8 mov edx,DWORD PTR [rbp-0x8] 2d: 8b 45 fc mov eax,DWORD PTR [rbp-0x4] 30: 89 d6 mov esi,edx 32: 89 c7 mov edi,eax 34: e8 c7 ff ff ff call 0 39: 89 45 f4 mov DWORD PTR [rbp-0xc],eax 3c: b8 00 00 00 00 mov eax,0x0} 41: c9 leave 42: c3 ret
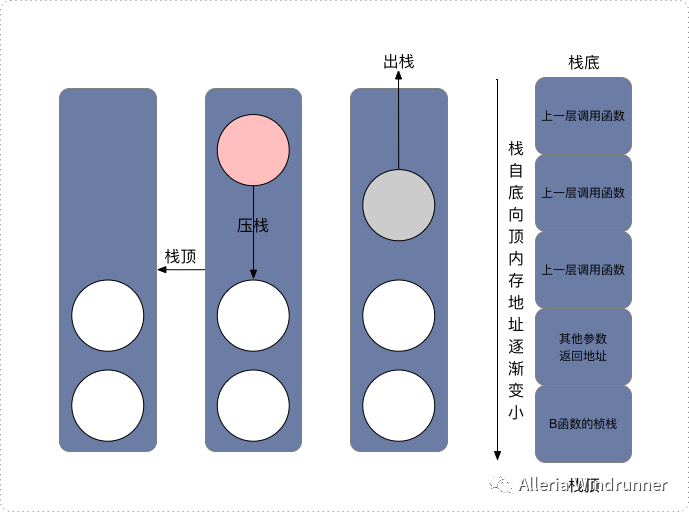
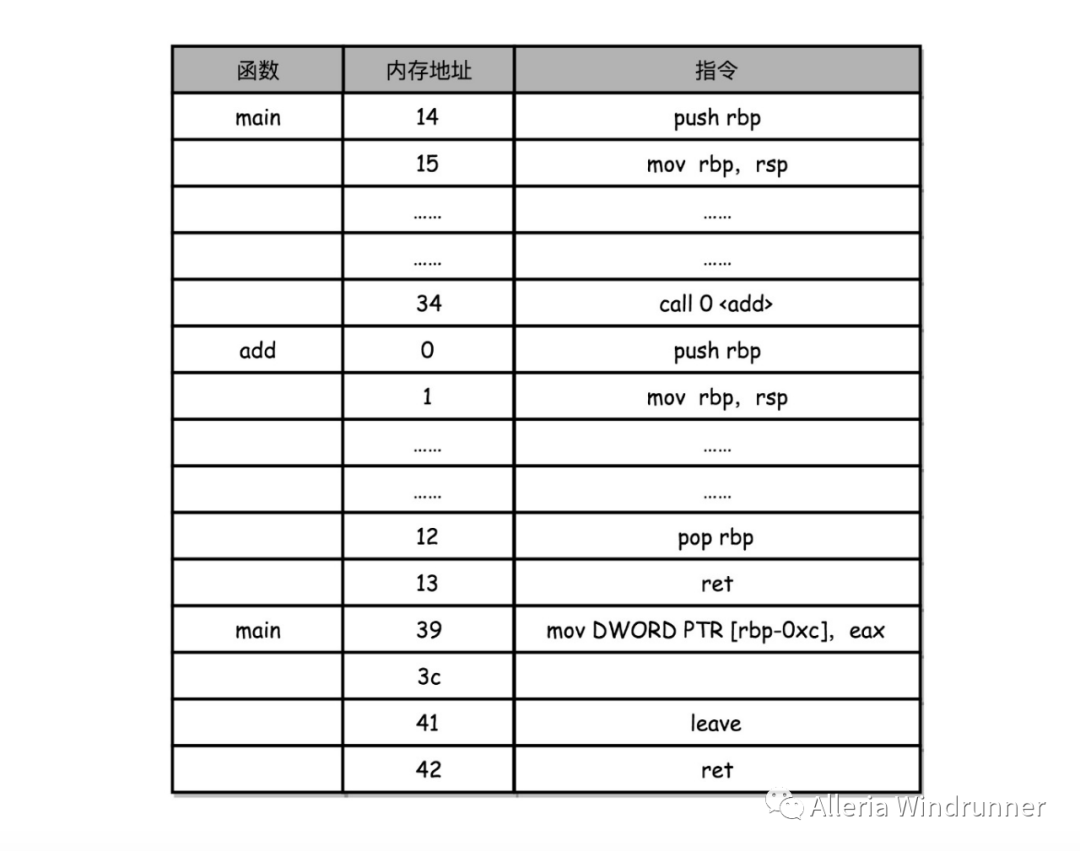
int a(){ return a();}int main(){ a(); return 0;}#include #include #include int static add(int a, int b){ return a+b;}int main(){ srand(time(NULL)); int x = rand() % 5 int y = rand() % 10; int u = add(x, y) printf("u = %d\n", u)}$ gcc -g -c -O function_example_inline.c$ objdump -d -M intel -S function_example_inline.o return a+b; 4c: 01 de add esi,ebx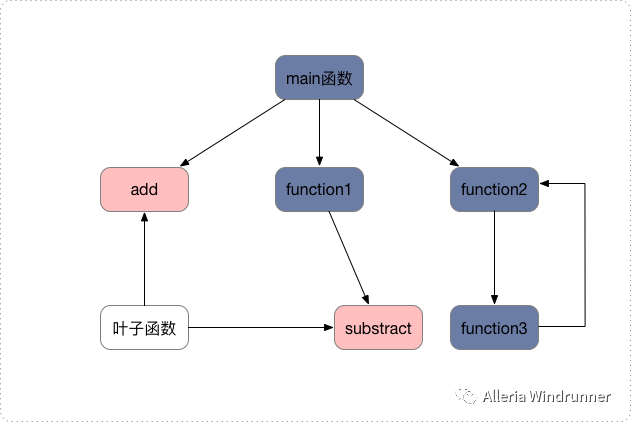


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









