






 本文探讨了PostgreSQL从集中式到分布式架构的转变,包括伪分布式和原生分布式的特点,强调了云原生分布式架构的重要性。文章介绍了PostgreSQL的noshard、主从、RAC集群(Oracle)以及分布式和共享存储的云架构,并讨论了Citus和PGXL的分布式核心架构。
本文探讨了PostgreSQL从集中式到分布式架构的转变,包括伪分布式和原生分布式的特点,强调了云原生分布式架构的重要性。文章介绍了PostgreSQL的noshard、主从、RAC集群(Oracle)以及分布式和共享存储的云架构,并讨论了Citus和PGXL的分布式核心架构。
文章目录
一、PG未来主流架构为什么是分布式二、PostgreSQL集中式到分布式架构总结一、PG未来主流架构为什么是分布式
如果说5年前DB的分布式还只是一种趋势,如今分布式数据库正逐渐从趋势变成主流。说到分布式,我想我们不能不提一下集中式和分库分表。
01
集中式和分布式
集中式数据库架构可以理解为CA模型,具备良好的单体可用性和一致性,但随着高速互联时代的发展,当到达单体容量瓶颈的时候,集中式架构在纵向扩容及横向扩展上的缺陷会越来越明显。而分布式数据库架构,主要就是为了解决横向扩展问题出现的,分布式首先要解决的就是保障AP模型下分区容错及可用性,如数据分配、跨中心、自愈能力、弹性扩缩容等,并且在此基础上尽可能地提高CP模型能力。
02
伪分布式和原生分布式
横向扩展能力的实现,可以使用中间件+分库分表的方案实现,也可以采用原分布式数据库的方案实现。前者(如采用proxy中间件+分库分表),由于在SQL解析和执行计划等方面和存储节点存在重复性工作,效率相对低效,单个分片之间传统的主备复制协议(如MySQL中的半同步)还无法完全保障数据的一致性。而原生分布式数据库,在cn节点可以利用全局元数据进行全局的SQL解析及全局执行计划的生成,分片主副本之间通过paxos或Raft一致性协议保障一致性。
03
未来已来,分布式1.0到分布式2.0,云原生分布式架构。
PostgreSQL技术生态在分布式上已经有比较成熟的方案,如原生的Citus、PGXL,严格来说,第一代分布式数据库未能做到完全的计算和存储分离,云原生分布式架构则是在云上实现了分布式下的共享存储的存储与计算分离。
二、PostgreSQL架构演变
首先,是最简单的noshard单体架构,这个是Postgresql和其他rdbms都共有的架构:
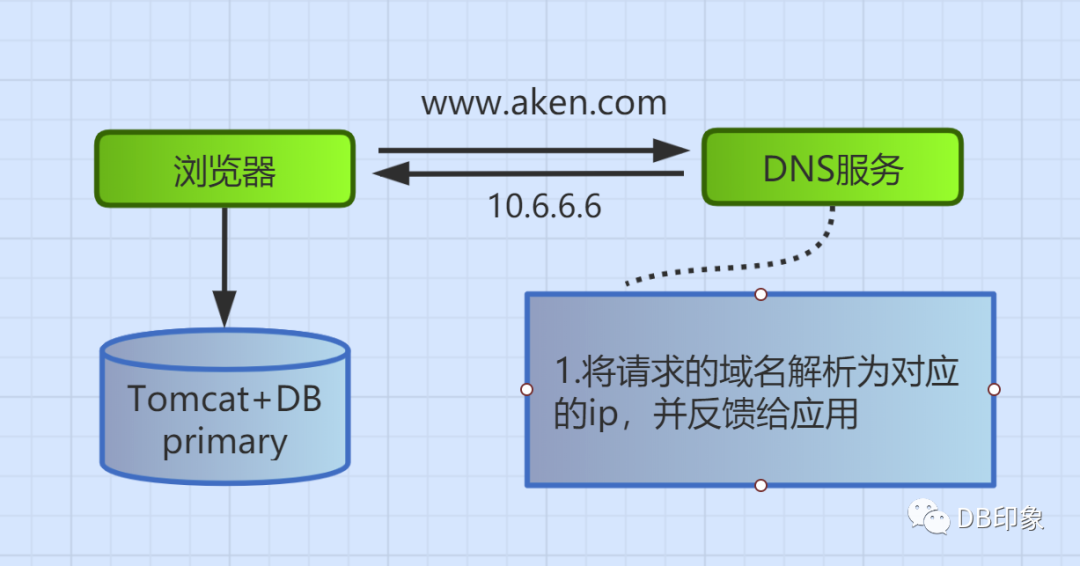
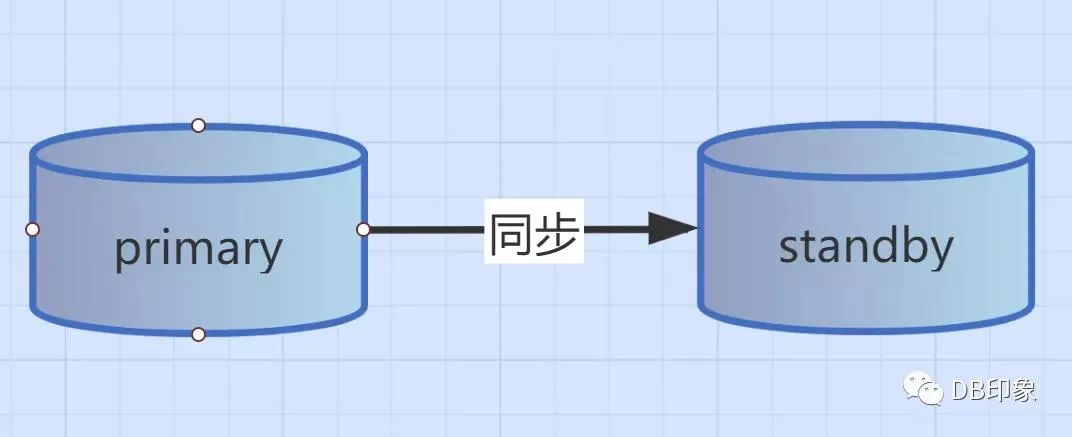
又或者是为了读写分离、容灾的而做的主从架构,也属于单体集中式架构。该架构可以做到一主多从跨IDC,比如我目前接手的一套MySQL系统,1主10从,对于读多写少又不想引入cache层的场景,该架构没太大的问题。
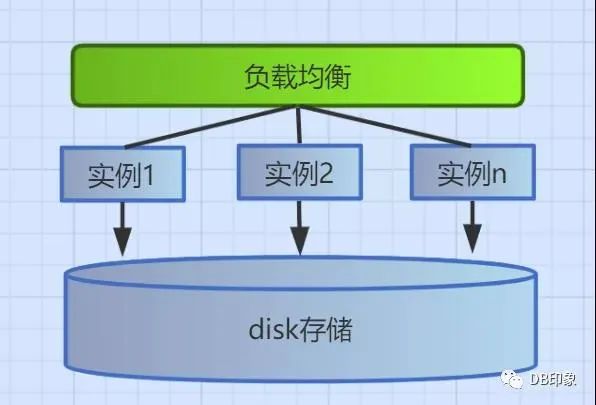
为了防止主库的单点瓶颈,提高整改系统的读写吞吐能力及系统可用性,Oracle引入了RAC集群,是一种share everything的集中式架构,多个实例共享一份数据存储,实例节点均可读写。该架构理论上实例的数量可以横向扩展,底层共享的disk存储纵向扩容,扩容的成本高昂。
目前PostgreSQL没有上面这种架构的,在个人看来,这种架构对PostgreSQL在云架构的发展有很大的启发意义。
接着,在高并发及海量数据场景下,迎来了我们目前的分布式架构,该架构应该是一种过渡阶段,最终会向云架构转变。
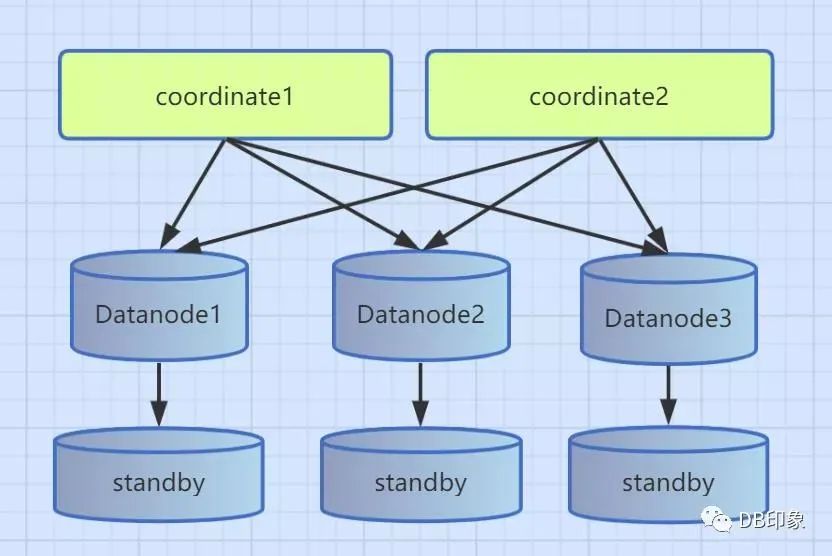
相对于Oracle中Rac的share everything,PostgreSQL这种分布式中DN节点之间数据是无共享的,是一种share nothing架构:
1、每个DN节点根据分布算法存储逻辑表的数据分片
2、CN节点接收SQL请求、解析SQL并生成执行计划、下推分发请求。
3、抛开gtm之间的区别,这个就是目前citus和pgxl的核心架构。
最后,就是云原生分布式架构,是一种分布式和共享存储的结合体,比如亚马逊AWS Aurora,阿里PolarDB。
这种架构primary实例的写请求只写日志而不写数据页,redo逻辑下沉到存储节点,Pg实例架构层只处理计算请求,不存储数据,多个实例共享一个存储集群。
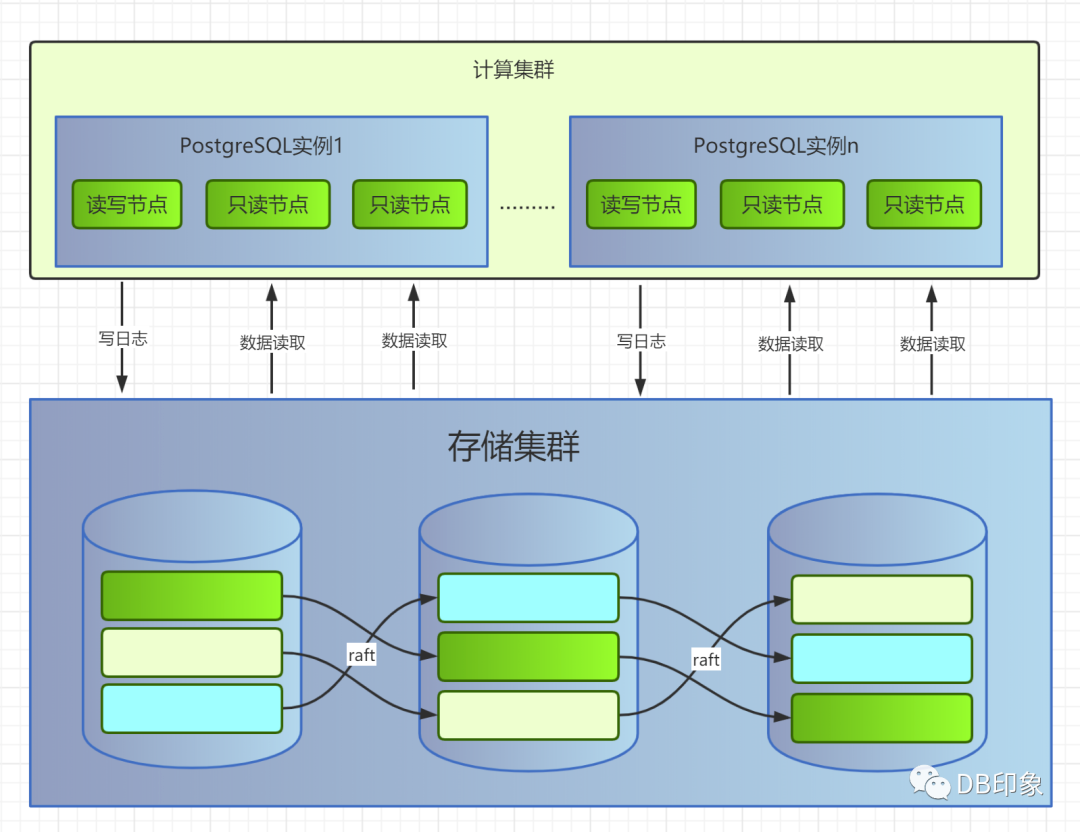
该架构最大的特点就是"log is database":
1、计算集群与存储集群之间只传递日志,而不传递脏页,日志数据页面的合并由存储端在适当的时机来完成。
2、存储集群内部多个数据副本之间通过一致性协议进行复制。
I Love PG关于我们
中国开源软件推进联盟PostgreSQL分会(简称:中国PG分会)于2017年成立,由国内多家PostgreSQL生态企业所共同发起,业务上接受工信部中国电子信息产业发展研究院指导。中国PG分会是一个非盈利行业协会组织。我们致力于在中国构建PostgreSQL产业生态,推动PostgreSQL产学研用发展。
欢迎投稿
做你的舞台,show出自己的才华 。
投稿邮箱:partner@postgresqlchina.com
——愿能安放你不羁的灵魂
技术文章精彩回顾PostgreSQL学习的九层宝塔PostgreSQL职业发展与学习攻略搞懂PostgreSQL数据库透明数据加密之加密算法介绍一文读懂PostgreSQL-12分区表一文搞懂PostgreSQL物化视图PostgreSQL源码学习之:RegularLockPostgresql源码学习之词法和语法分析2019,年度数据库舍 PostgreSQL 其谁?Postgres是最好的开源软件PostgreSQL是世界上最好的数据库从Oracle迁移到PostgreSQL的十大理由从“非主流”到“潮流”,开源早已值得拥有PG活动精彩回顾创建PG全球生态!PostgresConf.CN2019大会盛大召开首站起航!2019“让PG‘象’前行”上海站成功举行走进蓉城丨2019“让PG‘象’前行”成都站成功举行中国PG象牙塔计划发布,首批合作高校授牌仪式在天津举行群英论道聚北京,共话PostgreSQL相聚巴厘岛| PG Conf.Asia 2019 DAY0、DAY1简报相知巴厘岛| PG Conf.Asia 2019 DAY2简报独家|硅谷Postgres大会简报PostgreSQL线上沙龙第一期精彩回顾PostgreSQL线上沙龙第二期精彩回顾PostgreSQL线上沙龙第三期精彩回顾PostgreSQL线上沙龙第四期精彩回顾PostgreSQL线上沙龙第五期精彩回顾PostgreSQL线上沙龙第六期精彩回顾直播回顾 | Bruce Momjian:原生分布式将在PG 14版本发布PG培训认证精彩回顾中国首批PGCA认证考试圆满结束,203位考生成功获得认证!中国第二批PGCA认证考试圆满结束,115位考生喜获认证!重要通知:三方共建,中国PostgreSQL认证权威升级!近500人参与!首次PGCE中级、第三批次PGCA初级认证考试落幕!通知:PostgreSQL技术能力电子证书上线!2020年首批 | 中国PostgreSQL初级认证考试圆满结束

















 2796
2796

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









