





 本文详细解析了Android中Handler的工作原理,包括Looper、MessageQueue及Message的运作机制,探讨了Handler在UI线程与子线程间通信的重要作用。
本文详细解析了Android中Handler的工作原理,包括Looper、MessageQueue及Message的运作机制,探讨了Handler在UI线程与子线程间通信的重要作用。
Handler使用主要作用一句话概括:线程间通信。
在日常开发中主要作用于两方面:
1、在UI线程进行耗时操作时,将耗时操作抛到子线程进行处理,否则容易ANR。
2、在子线程中刷新UI。
一、Handler简介
[Handler]、[Looper]、[MessageQueue] 和 [Message] 是组成Handler通信机制的基础。
1.1Handler简单使用
Handler的使用基本如以下代码所示,或者继承Handler重写handleMessage,处理不同what标识的Message。不是本文讨论的重点,不做过多叙述。
//创建子线程HandlerHandlerThread mHandlerThread = new HandlerThread("daqi");mHandlerThread.start();Handler mHandler = new Handler(mHandlerThread.getLooper());//创建MessageMessage message = mHandler.obtainMessage();//发送MessagemHandler.sendMessage(message);//postmHandler.post(new Runnable() { @Override public void run() { }});1.2Handler工作流程
创建Handler,并绑定Looper -> Handler发送Message -> Message存储到Looper的MessageQueue中 -> Looper在MessageQueue中拿取顶部Message -> 将Message发送给目标Handler
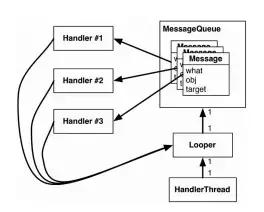
Handler、Looper、MessageQueue 和 Message的关系:
- 一个线程只能有一个Looper;
- 一个Handler只能绑定一个Looper;
- 多个Handler可以绑定同一个Looper;
- 一个Looper管理着一个MessageQueue。
- MssageQueue作为Message“收信箱”,收纳着Handler发送的Message。
二、提出问题
带着问题看源码:
1、Looper如何确保线程中只有一个单例。
2、为什么建议使用Handler#obtainMessage()获取Message对象,而不是直接new。
3、Handler的sendMessage() 和 post()有什么区别。
4、Looper如何管理Message队列(即先后发送不同延迟时间的Message,Message队列如何排序)。
5、removeCallbacks、removeMessages 和 removeCallbacksAndMessages都移除了什么。
推荐阅读:阿里腾讯Android开发十年,到中年危机就只剩下这套移动架构体系了!
三、源码分析
3.1、Looper机制
Handler在创建时,默认构造方法会绑定当前线程。所以我们选择先从Handler的默认构造方法看起。
#Handler.java//无参构造函数public Handler() { this(null, false);}public Handler(Callback callback, boolean async) { //.... mLooper = Looper.myLooper(); if (mLooper == null) { throw new RuntimeException( "Can't create handler inside thread " + Thread.currentThread() + " that has not called Looper.prepare()"); } mQueue = mLooper.mQueue; mCallback = callback;}创建Handler对象时,无参构造函数会获取当前线程的Looper并获取到其MessageQueue存储到Handler自身变量中。
但我们也观察到,如果没有Looper的Thread中创建,会抛出RuntimeException,并告诉你该线程无Looper。

从Handler的默认构造方法中得知,在创建Handler前,需要先在当前线程中创建Looper对象和MessageQueue对象。而创建Looper对象和MessageQueue对象只需要调用如下方法:
Looper.prepare();Looper.loop();prepare的意思是准备,即可以猜测Looper是在Looper#prepare()中初始化的,所以先从Looper#prepare()的源码看起:
#Looper.java//主要用于作为存储的Looper实例的key。static final ThreadLocal sThreadLocal = new ThreadLocal();private Looper(boolean quitAllowed) { mQueue = new MessageQueue(quitAllowed); mThread = Thread.currentThread();}public static void prepare() { prepare(true);}private static void prepare(boolean quitAllowed) { //ThreadLocal#get()获取当前线程的looper对象 if (sThreadLocal.get() != null) { //如果Looper已经实例化完,则会抛出异常 throw new RuntimeException("Only one Looper may be created per thread"); } //如果之前当前线程没有初始化过Looper,则创建Looper并添加到sThreadLocal中 sThreadLocal.set(new Looper(quitAllowed));}我们发现Looper#prepare()调用重载函数Looper#prepare(boolean)。在这方法中,Looper会被初始化。查看Looper私有构造函数,发现Looper会初始化MessageQueue并存储当前线程。
而Looper被初始化是有一个前提的,即sThreadLocal.get() == null。否则会抛出RuntimeException,并告诉你该线程只能创建一个Looper对象。
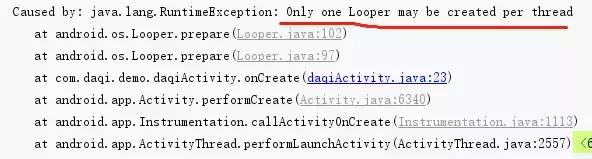
sThreadLocal是Looper类中定义的一个静态ThreadLocal常量。继续查看ThreadLocal#get()和ThreadLocal#set()方法。
#ThreadLocal.javapublic T get() { //获取当前线程 Thread t = Thread.currentThread(); //线程中存在一个ThreadLocal.ThreadLocalMap类型的变量 //根据当前线程thread获取到对应的ThreadLocal.ThreadLocalMap变量。 ThreadLocalMap map = getMap(t); if (map != null) { //this表示Looper类中的静态ThreadLocal常量sThreadLocal //因为sThreadLocal是静态常量,作为“key”,确保变量为单例。 //根据sThreadLocal获取到对应的ThreadLocalMap.Entry值。 ThreadLocalMap.Entry e = mapgetEntry(this); if (e != null) { //从ThreadLocalMap.Entry中获取到对应的Looper, @SuppressWarnings("unchecked") T result = (T)e.value; return result; } } return setInitialValue();}public void set(T value) { //获取当前线程 Thread t = Thread.currentThread(); //线程中存在一个ThreadLocal.ThreadLocalMap类型的变量 //根据当前线程thread获取到对应的ThreadLocal.ThreadLocalMap变量。 ThreadLocalMap map = getMap(t); if (map != null) //将sThreadLocal作为“key”,Looper实例作为“value”存储到ThreadLocal.ThreadLocalMap中 map.set(this, value); else //创建Map并存储值 createMap(t, value);}void createMap(Thread t, T firstValue) { //创建ThreadLocalMap,构造方法中传入第一次存储的键值对,并赋值到当前线程的threadLocals变量中。 t.threadLocals = new ThreadLocalMap(this, firstValue);}可以观察到,get()和set()方法获取当前线程中的ThreadLocal.ThreadLocalMap变量。再将Looper#sThreadLocal作为key,存储或获取对应的value,而value就是当前线程创建的Looper实例。
get()时是根据当前线程获取的Looper单例,再结合Looper#prepare(boolean),可以知道单个线程只会生成Looper单个实例。
问题1:Looper如何确保线程中只有一个单例。
回答:将Looper构造方法私有化。通过Looper的静态方法,确保只创建一次Looper对象,再将静态常量sThreadLocal作为key,Looper对象作为value,存储到当前线程的ThreadLocal.ThreadLocalMap变量中。
查看完Looper初始化的流程,再看看Looper#loop()的源码
#Looper.javapublic static void loop() { //获取当前线程的Looper final Looper me = myLooper(); //如果Looper没有初始化,则抛异常 if (me == null) { throw new RuntimeException("No Looper; Looper.prepare() wasn't called on this thread."); } //从Looper实例中获取当前线程的MessageQueue final MessageQueue queue = me.mQueue; //消息循环(通过for循环) for (;;) { //1、从消息队列中获取消息 Message msg = queue.next(); if (msg == null) { //没有消息表明消息队列正在退出。 return; } //省略代码..... //2、将Message发送给其标记的targetHandler msg.target.dispatchMessage(msg); //省略代码..... //3、回收可继续使用的Message msg.recycleUnchecked(); }}Looper#loop()主要做3件事:
1、不断从MessageQueue中取出Message,若暂无Message,则无限等待
2、将Message发送给目标Handler进行处理。
3、回收Message对象。
但发现有一种情况,当next获取到的Message为空时,则会退出Looper#loop()方法,即意味着消息循环结束。那什么时候MessageQueue#next()返回null?
#MessageQueue.javaMessage next() { //如果消息循环已经退出并处理掉,请返回此处。 //如果应用程序尝试在退出后重新启动looper,则可能会发生这种情况。 //即MessageQueue调用了quit()方法,再次调用Looper#looper()方法时。 final long ptr = mPtr; if (ptr == 0) { return null; } //决定消息队列中消息出队的等待时间 or 标记为无限等待状态 int nextPollTimeoutMillis = 0; for (;;) { //..... // nativePollOnce方法在native层方法。 //若是nextPollTimeoutMillis为-1,则无限等待,此时消息队列处于等待状态。 //若是nextPollTimeoutMillis为0,则无需等待立即返回。 //若nextPollTimeoutMillis>0,最长阻塞nextPollTimeoutMillis毫秒(超时),如果期间有程序唤醒会立即返回。 nativePollOnce(ptr, nextPollTimeoutMillis); //尝试检索下一条消息。 如果找到则返回。 synchronized (this) { //获取从开机到现在的毫秒数 final long now = SystemClock.uptimeMillis(); Message prevMsg = null; //获取MessageQueue中的顶层Message Message msg = mMessages; //..... if (msg != null) { //如果massage的时间大于当前时间 //Message的when = Handler发送Message1时的开机时间SystemClock.uptimeMillis() + Message自身的延迟时间 if (now < msg.when) { // 下一条消息尚未就绪。 设置该Message的等待时间以在准备就绪时唤醒。 //将msg.when - now(当前开机时间) 得到该Message需要多久之后发送。 //则刷新nextPollTimeoutMillis的值,设置等待时间。 nextPollTimeoutMillis = (int) Math.min(msg.when - now, Integer.MAX_VALUE); } else {//否则马上发送Message //只有当msg.target == null时,prevMsg才会赋值。 //遵从Handler#obtainMessage()则一般不为空,此情况不考虑。 if (prevMsg != null) { prevMsg.next = msg.next; } else { //刚开始时prevMsg为空 //则mMessages(顶层Message)指向当前顶层Message的下一个Message mMessages = msg.next; } //将返回的Message的下一个Message引用置空。 msg.next = null; msg.markInUse(); return msg; } } else { //如果MessageQueue中没有Message,则会将nextPollTimeoutMillis重置为-1,继续等待 nextPollTimeoutMillis = -1; } //..... } //..... }}从源码开头得知,当MessageQueue退出时,MessageQueue#next()则会返回Message对象为空,从而关闭消息循环。
MessageQueue#next()主要进行等待操作和返回Message操作。而等待操作分两种情况:
1、MessageQueue队列中无Message,则进行无限等待操作。
2、当Message还没到处理时间时,则计算该Message还需要等待的时间,进行相应时间的延迟。
查看Handler如何处理Message:
#Handler.javapublic void dispatchMessage(Message msg) { if (msg.callback != null) { //如果Message的callback不为空,则将消息交由Message的callback处理 handleCallback(msg); } else { if (mCallback != null) { //如果Handler的callback不为空,则将消息交由Handler的callback处理 if (mCallback.handleMessage(msg)) { return; } } //最后才交由Handler的handleMessage()方法处理。 handleMessage(msg); }}Handler#dispatchMessage()主要作用时将Message分发处理。
当该Message对象的callback为空,目标Handler的callback也为空时,才轮到handleMessage()进行消息处理。
3.2、Message的循环再用机制
创建Message对象时,我们一般会调用Handler#obtainMessage()获取Message对象,而不是直接new。先从Handler#obtainMessage()开始查看原由:
#Handler.javapublic final Message obtainMessage(){ return Message.obtain(this);}#Message.java//Message链表,sPool是表头private static Message sPool;//记录当前链表中的数量private static int sPoolSize = 0;public static Message obtain(Handler h) { Message m = obtain(); m.target = h; return m;}public static Message obtain() { //加锁 synchronized (sPoolSync) { if (sPool != null) { Message m = sPool; //链表表头指向其下一个对象,即将表头从链表中取出 sPool = m.next; //重置返回的Message的一些信息 m.next = null; m.flags = 0; // clear in-use flag //链表数量减一 sPoolSize--; return m; } } //如果链表表头为空,则new Message对象。 return new Message();}Message#obtain(Handler)调用了重载方法Message#obtain()获取到Message对象并将Message的目标设置为调用Handler#obtainMessage()的Message。
Message对象中拥有一个Message类型的next对象,可通过next属性连成一个Message链表。Message中维系着一个静态Message链表,当链表不为空时,取出表头的Message进行返回,否则new一个Message对象。
之前查看Looper#loop()源码时获知,Looper#loop()最后会调用Message#recycleUnchecked(),将Message进行回收。
#Message.java//Message链表最大存储数量值private static final int MAX_POOL_SIZE = 50;void recycleUnchecked() { //将消息保留在循环对象池中时将其标记为正在使用。 //清除所有其他细节。 flags = FLAG_IN_USE; what = 0; arg1 = 0; arg2 = 0; obj = null; replyTo = null; sendingUid = -1; when = 0; target = null; callback = null; data = null; //加锁 synchronized (sPoolSync) { //当前链表存储数量小于最大值,则继续回收 if (sPoolSize < MAX_POOL_SIZE) { //next代表的是该需要回收的Message自身的next对象 //将自身的next指向原表头, next = sPool; //自身替换为表头,则通过表头的加减实现该Message链表的增加和删除。 sPool = this; //链表存储数量加一 sPoolSize++; } }}Message#recycleUnchecked()将Message的参数重置,并判断当前Messag链表存储的数量是否小于最大存储值,若小于最大存储值,则将该Message存储到链表中,重复使用。
Message通过对链表表头的增删操作来进行链表的增减。
问题2:为什么建议使用Handler#obtainMessage()获取Message对象,而不是直接new。
回答:Message的回收机制其实是享元设计模式的实现,Message对象存在需要反复、较大规模创建的情况,使用享元设计模式可以减少创建对象的数量,以减少内存占用和提高性能。
总结:
- Message对象中拥有一个Message类型的next对象,可通过next属性连成一个Message链表。
- Message类中维系着个静态Message链表,并标记其存储的数量值。
- 调用Handler#obtainMessage()或Message#obtain()方法时,尝试从该静态链表中获取循环再用的Message对象,否则new Message对象返回出去。
- 当Message被Handler处理完后,Looper对象会调用Message#recycleUnchecked()将Message进行回收,并存储到静态Message链表中。
3.3、Handler两条发送路径:sendMessage 和 post
我们都知道,Handler可以通过sendMessage和post进行消息的发送,这两种方法到底有什么区别?先从sendMessage看起:
#Handler.javapublic final boolean sendMessage(Message msg){ //发送一个0延迟的message return sendMessageDelayed(msg, 0);}public final boolean sendMessageDelayed(Message msg, long delayMillis){ //延迟值不能小于0 if (delayMillis < 0) { delayMillis = 0; } //将延迟的时间和开机时间相加 return sendMessageAtTime(msg, SystemClock.uptimeMillis() + delayMillis);}public boolean sendMessageAtTime(Message msg, long uptimeMillis) { //获取Handler创建时存储的当前线程的MessageQueue MessageQueue queue = mQueue; if (queue == null) { RuntimeException e = new RuntimeException( this + " sendMessageAtTime() called with no mQueue"); Log.w("Looper
















 2824
2824

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









