






 xgboost是陈天奇博士创建的梯度提升框架,以其高效和准确著称。它采用二阶泰勒展开优化损失函数,通过正则项防止过拟合,使用近似算法和特性如收缩、列采样、处理缺失值优化计算。xgboost的并行处理和内存优化使其在数据竞赛中表现出色。
xgboost是陈天奇博士创建的梯度提升框架,以其高效和准确著称。它采用二阶泰勒展开优化损失函数,通过正则项防止过拟合,使用近似算法和特性如收缩、列采样、处理缺失值优化计算。xgboost的并行处理和内存优化使其在数据竞赛中表现出色。
xgboost是华盛顿大学博士陈天奇创造的一个梯度提升(Gradient Boosting)的开源框架。至今可以算是各种数据比赛中的大杀器,被大家广泛地运用。接下来,就简单介绍一下xgboost和普通的GBDT相比,有什么不同。(何为Gradient Boosting, GBDT请看我上篇文章)
1. 梯度下降
在GBDT中,我们每次生成下一个弱学习器,都是把损失函数的梯度作为学习目标,相当于利用梯度下降法进行优化来逼近损失函数的最小值,也就是使得损失函数为0,最终学习器尽可能接近真实结果。
而xgboost中,我们则是把损失函数的二阶泰勒展开的差值作为学习目标,相当于利用牛顿法进行优化,来逼近损失函数的最小值,也就是使得损失函数为0。
那为什么可以这么逼近呢?这就涉及到泰勒展开:
梯度下降法就是用一阶泰勒展开来近似函数:
而牛顿法则是用二阶泰勒展开来近似函数:
之后具体的迭代收敛原理请看最优化方法。
2. 正则项
正则项是为了防止模型过拟合。于是,一般的损失函数
对叶子节点个数进行惩罚,相当于在训练过程中做了剪枝。
将xgboost的目标函数进行化简,并把
令 其导数为0,解得每个叶节点的最优预测分数为:
代入目标函数,得到最小损失为:
3. 树节点分裂方法
精确算法:遍历所有特征的所有可能分割点,来寻找使目标函数最小的分割点。
近似算法:对于每个特征,只考察分位点,减少计算复杂度。
而XGBoost不是简单地按照样本个数进行分位,而是以二阶导数值作为权重(Weighted Quantile Sketch),比如:
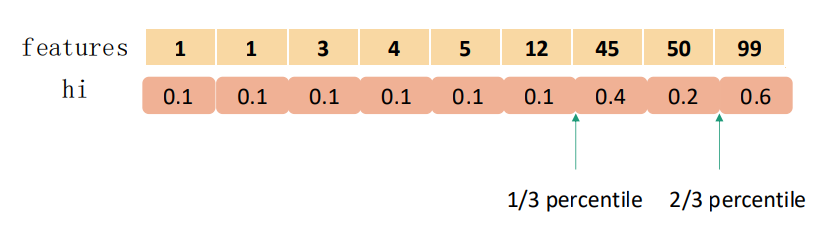
4. 其他特征
- shrinkage(收缩)方法:相当于学习系数eta。对每颗子树都要乘上该系数,防止过拟合。
- 列采样:对特征进行降采样,灵感来源于随机森林,除了能降低计算量外,还能防止过拟合。
- 行采样:
- 缺失值处理:通过枚举所有缺失值在当前节点是进入左子树,还是进入右子树更优来决定一个处理缺失值默认的方向。
- xgboost工具支持并行。一般决策树中,我们需要每次都对特征的值进行排序,来寻找分割点,极其费时。xgboost中,我们先对每个特征进行分块(block)并排序,使得在寻找最佳分裂点的时候能够并行化计算。这个结构加速了split finding的过程,只需要在建树前排序一次,后面节点分裂时直接根据索引得到梯度信息。这是xgboost比一般GBDT更快的一个重要原因。
- out-of-core, cache-aware优化内存等方法来加速计算。
参考资料:
知乎上有关问题的回答 https://www.zhihu.com/question/41354392
一个很详细的PPT http://wepon.me/files/gbdt.pdf
陈天奇原版论文 https://arxiv.org/pdf/1603.02754.pdf

















 4879
4879

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









