






 本文探讨了统计显著性在评估变量效果时的误区,指出仅凭显著性判断两组差异可能误导分析。通过实例解释了在统计上显著和不显著的两组差异可能并不显著,并提出运用置信区间和效应量作为补充工具,以避免错误解读统计结果。文章介绍了如何正确理解 值,并提供了Stata实现效应量的案例,强调了效应量在统计分析中的重要性。
本文探讨了统计显著性在评估变量效果时的误区,指出仅凭显著性判断两组差异可能误导分析。通过实例解释了在统计上显著和不显著的两组差异可能并不显著,并提出运用置信区间和效应量作为补充工具,以避免错误解读统计结果。文章介绍了如何正确理解 值,并提供了Stata实现效应量的案例,强调了效应量在统计分析中的重要性。
NEW!连享会·推文专辑:
Stata资源 | 数据处理 | Stata绘图 | Stata程序
结果输出 | 回归分析 | 时间序列 | 面板数据 | 离散数据
交乘调节 | DID | RDD | 因果推断 | SFA-TFP-DEA
文本分析+爬虫 | 空间计量 | 学术论文 | 软件工具
连享会学习群-常见问题解答汇总:
? WD 主页:https://gitee.com/arlionn/WD
作者: 陈滨志 (英国伯明翰大学)邮箱: Rickchen0910@163.com
? 连享会主页:lianxh.cn

Stata 暑期班:9天直播
? 时间:2020.7.28-8.7
? 嘉宾:连玉君 (中山大学) | 江艇 (中国人民大学)
? 主页:https://gitee.com/arlionn/PX | ? 微信版「基础不牢,地动山摇……」

[Source]:Gelman A, Stern H. The difference between “significant” and “not significant” is not itself statistically significant[J]. The American Statistician, 2006, 60(4): 328-331. -Link- -Link-
目录
1. 引言
2. 统计显著性误用的理论
3. 统计显著性误用的案例
4. 解决办法
4.1 到底什么是 值?
4.2 正确认识 值
4.3 运用置信区间与效应量
5. 效应量的 Stata 实现
6. 参考文献
编者按:本文主要翻译自如下论文,特此致谢
Gelman, A. and Stern, H., 2006. The Difference Between “Significant” and “Not Significant” is not Itself Statistically Significant. The American Statistician, 60(4), pp.328-331. -Link-, -Link2-
温馨提示: 文中链接在微信中无法生效。请点击底部
1. 引言
在统计分析中,我们会对变量进行「统计显著 / 非显著 (Statistical Significance / Insignificance )」的检验,并在显著性结果与非显著性结果之间进行明显区分。但是这种方法其实有很多弊端:
- 统计上的显著并不代表具有实际意义的显著 (Practical Significance)。比如,在评价某种药物对降低血压的效果时,让其他条件不变,我们使用某种药物可以降低 0.1 的血压,并且标准误为 0.03,这在统计上是显著的。但是,从实际角度来看,正常血压一般在 100 左右,0.1 这个值影响可能是不显著的。相反,在其他条件不变的情况下,我们使用某种药物可以降低 10 的血压,并且标准误为 10,这在统计上是不显著的。但是,从实际角度来看,10 可能是显著的。
- 在结果上采用二分法 (dichotomization) 来区分显著和不显著,会更加趋向于消除客观差异,从而不拒绝原假设。我们还是以评价某种药物对降低血压的效果为例,在其他条件不变的情况下,使用某种药物可以降低 10 的血压,并且标准误为 10,这在统计上是不显著的。因此,我们不拒绝原假设,即这种药物对降低血压毫无效果,但事实上这种情况可能是由「样本的特征或样本量过小」导致的。
- 除了这些比较常见的对统计显著性的批判外,Gelman and Stern (2006) 还提出了另一个问题,即「一组显著,一组不显著,两组差异检验的结果可能是不显著」。
接下来,本文将根据 Gelman and Stern (2006) 的内容来说明「为什么仅用 值来判断实证结果不是一个合格的分析」,并给出正确认识 值的原则和误用的解决办法。
2. 统计显著性误用的理论
现有两个改善癌症患者健康的药物实验:
药物 A:
- 效果估计系数值:25
- 标准误:10
药物 B:
- 效果估计系数值:10
- 标准误:10
从统计角度看,药物 A 是在 1% 统计水平上显著,而药物 B 不显著。所以,我们会认为这两个实验在效果上具有很大的差别。但是,这种差异是否会在统计上显著?
实际上,二者的观测差异为 15,标准误为 ,是不显著的,即不能拒绝原假设 (fail to reject null hypothesis):
药物药物现在考虑新的药物C:
- 药物 C:
- 效果估计系数值:2.5
- 标准误:1.0
可以看出,药物 C 与药物 A 都在 1% 统计水平上显著,并且二者差异的统计性检验也是显著,即两种药物对癌症患者都有正向效果,但程度不同。
药物 C 算是对药物 A 的复现吗?单从显著性的角度来看,由于二者都显著,故 C 是对药物 A 的复现。但是,从系数来看,药物 C 的效应和药物 B 更为接近。
从决策角度看,如果只看药物的显著性,在治疗癌症时,我们应该用药物 A 而非药物 B。但是,考虑到二者在统计上并没有显著差异,故上述结论是片面的。
因此,在评价两组效果时,简单比较「变量是否显著」并不是一个好的方法,我们应该「对二者差异进行显著性检验」。
3. 统计显著性误用的案例
上述的理论阐述只是针对两组对比,在实际的分析中,我们往往会涉及多组对比,所以判断是否显著的问题也就显得更加重要。以公众健康方面的应用为例,由于学者们越来越关注低频电磁场对于人体健康的影响,Blackman et al. (1988) 展开了一系列关于衡量不同频率的电磁场对雏鸡脑部功能的实验。
首先,Blackman et al. (1988) 将雏鸡随机分为控制组和实验组,其中控制组为没有受磁场影响雏鸡,实验组为暴露在不同赫兹频率下 (1 Hz, 15 Hz, 30 Hz, . . . , 510 Hz) 的雏鸡。然后,在不同频率下估计的效应值 (实验组与控制组的平均效果差值) 和标准误。
Blackman et al. (1988) 总结了在不同频率下所观测到的显著性情况。在下图中 轴代表赫兹值, 轴代表不同频率下估计的雏鸡脑部钙流失情况,比如 0.1 的效果值表示,相对于控制组,实验组的雏鸡脑部钙流失增加 10%。阴影部分代表在该频率下实验是统计性显著的。可以看出,255, 285 和 315 Hz 对雏鸡脑部的影响高度显著,而 135 和225 Hz 对雏鸡脑部的影响中度显著。
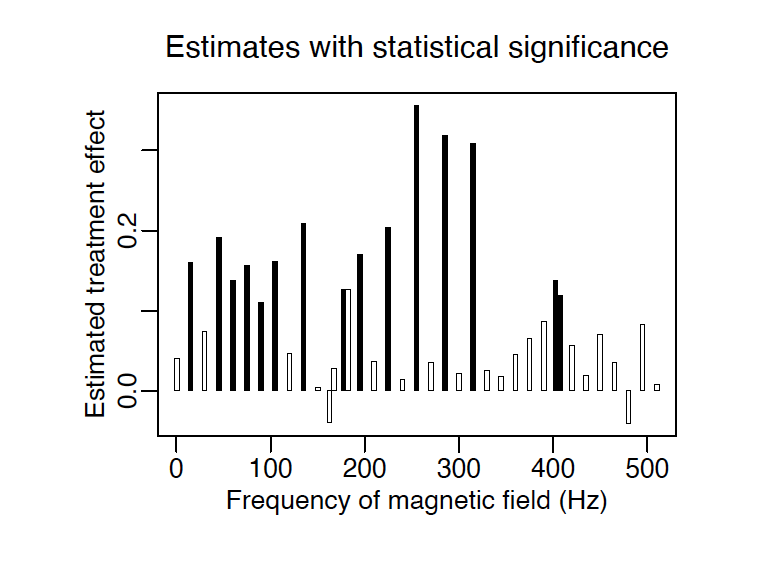
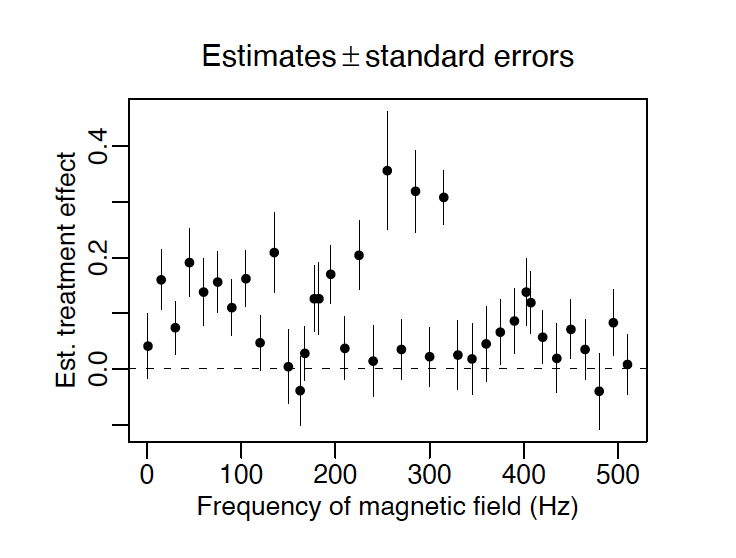
Blackman et al. (1988) 对雏鸡脑部的实验是对统计性显著误用的典型案例。该实验只表明了各组频率下是否统计性显著,并没有对比组与组之间的差异是否统计性显著。Gelman and Stern (2006) 使用估计值加减一个单位标准误的置信区间来描述不同赫兹下的实验结果,如下图。可以看出,尽管效应值之间有区别,但大多还是集中在 0.1 附近。
4. 解决办法
4.1 到底什么是 值?
从定义上来说, 值表示在原假设下观测到某 (极端) 事件的条件概率。假设 为极端事件, 为原假设,那么:
人们往往把 值的定义混淆为某 (极端) 事件发生的前提下原假设成立的条件概率,即:
Carver (1978) 对于二者的区别举了一个很有趣的例子:
定义两个事件:人死了,记为事件 ;人上吊,记为事件 。那么, 表示人因为上吊而死的概率,这个概率可能是很高的,比如 0.97。接着,我们把 和 的位置调换一下,即 ,则问题变成了在人死了的前提下,他是因为上吊而死的条件概率。由于人的死法有很多种,比如上吊、跳楼、服毒、割腕…… 因此,我们不会将 的取值等价于 ,即 0.97。
Note:本部分内容参考了「在追逐 p-value 的道路上狂奔,却在科学的道路上渐行渐远」
温馨提示: 文中链接在微信中无法生效。请点击底部
4.2 正确认识 值
鉴于在运用假设检验和 值的过程中的不足,McShane and Gal (2017) 总结了正确认识 值的六点原则:
- 值可以指示数据与指定的统计模型不兼容的程度。
- 值不是衡量所研究假设为真的概率,也不是衡量数据仅由随机机会产生的概率。事实上从 值的概念出发, 不是说原假设有 1% 的概率为真,而是说数据并不是很接近统计模型和假设的预测。
- 科学结论和政策决策不应仅基于 值是否超过特定阈值,如 0.05。
- 合理的统计推断需要完整的报告和透明度。
- 值或统计显着性不能衡量效应量大小或结果的重要性。
- 由于 值自身的问题,它本身并不能为模型和假设提供很好地衡量证明。
4.3 运用置信区间与效应量
置信区间 (CI) 为在给定的概率下,计算出包含总体值或 “真实” 值的范围。比如,估计值为 29 的系数在 95% 的置信区间 (-1,59) 下是不显著的,因为该区间包含了0;估计值为 29 的系数在 95% 的置信区间 (4,59) 下是显著的,因为该区间不包含 0 且系数估计值在置信区间内。
由于置信区间使用区间估计的方式,因此置信区间通常会比使用二分法的 值得到更多的信息。Gelman and Stern (2006) 也是使用置信区间的方法来完善 Blackman et al. (1988) 的实证分析。
在实证分析中,随着使用 值作为唯一判定结果的质疑逐渐增加,很多期刊在审稿时都会要求文章作者提供效应量的数值作为实证结果的补充。
效应 (effect) 可以是各组之间 (例如,治疗组和未治疗组) 的对比结果,或者可以描述两个相关变量 (例如,治疗剂量和健康状况) 之间的关联程度。效应量是指这种效应在结果中所展现的幅度。
常见的效应量包括未标准化的效应量,比如我们常见的回归系数值;也包括标准化的效应量,如下图所示:


图片来源: Ellis, P., 2017. The Essential Guide To Effect Sizes. Cambridge: Cambridge University Press.
5. 效应量的 Stata 实现
考虑一项研究,其中 30 名学生被随机分配到网络教学的教室 (实验组) 和标准教室 (控制组)。在学期末,对学生进行阅读和数学技能测试,其中阅读测试的得分为 0-15 分,数学测试的得分为 0-100 分。
在这里我们使用 Stata 官网的数据进行效应量的检测,详细的数据描述如下:
use http://www.stata.com/videos13/data/webclass.dta, replace
(Fictitious web-based learning experiment data)
des
Contains data from http://www.stata.com/videos13/data/webclass.dta
obs: 30 Fictitious web-based learning experiment data
vars: 5 5 Sep 2013 11:28
size: 330 (_dta has notes)
---------------------------------------------------------------------
storage display value
variable name type format label variable label
---------------------------------------------------------------------
id byte %9.0g ID Number
treated byte %9.0g treated Treatment Group
agegroup byte %9.0g agegroup Age Group
reading float %9.0g Reading Score
math float %9.0g Math Score
---------------------------------------------------------------------
Sorted by: id
ttest 命令可以对变量进行 检验。在这里,我们对原假设 (实验组与控制组的平均数学成绩差异为0) 进行检验:
ttest math, by(treated)
Two-sample t test with equal variances
--------------------------------------------------------------------------
Group | Obs Mean Std. Err. Std. Dev. [95% Conf. Interval]
---------+----------------------------------------------------------------
Control | 15 69.98866 3.232864 12.52083 63.05485 76.92246
Treated | 15 79.54943 1.812756 7.020772 75.66146 83.4374
---------+----------------------------------------------------------------
combined | 30 74.76904 2.025821 11.09588 70.62577 78.91231
---------+----------------------------------------------------------------
diff | -9.560774 3.706412 -17.15301 -1.968533
--------------------------------------------------------------------------
diff = mean(Control) - mean(Treated) t = -2.5795
Ho: diff = 0 degrees of freedom = 28
Ha: diff 0
Pr(T |t|) = 0.0154 Pr(T > t) = 0.9923
可以看出,实验组学生的数学成绩均值较大,但由于 ttest 计算的方法是控制组减去实验组,因此差异均值为负数。在这种情况下,负差异表示实验组 > 控制组。 统计量等于 ,其双尾 值为 ,表明两组数学得分之间的差异统计显著。
接下来我们应用 esize 计算 族效应量:
esize twosample math, by(treated) cohensd hedgesg glassdelta
Effect size based on mean comparison
Obs per group:
Control = 15
Treated = 15
---------------------------------------------------------
Effect Size | Estimate [95% Conf. Interval]
--------------------+------------------------------------
Cohen's d | -.9419085 -1.691029 -.1777553
Hedges's g | -.916413 -1.645256 -.1729438
Glass's Delta 1 | -.7635896 -1.52044 .0167094
Glass's Delta 2 | -1.361784 -2.218342 -.4727376
---------------------------------------------------------
Cohen’s d 和 Hedges’s g 表示数学平均成绩相差约 个标准差,且 95% 置信区间分别为 和 。
我们对 Glass’s Delta 1 感兴趣,因为它是使用控制组标准偏差计算得出的。数学平均成绩相差 ,置信区间为 。
Cohen’s d 和 Hedges’s g 的置信区间不包括零值,而 Glass’s Delta 1 的置信区间包括零值。因此,我们不能完全排除实验组对数学成绩没有影响的可能性。
接下来,我们可以使用方差分析来加入儿童的年龄组分析,以检验所有组数学平均成绩均相等的零假设:
anova math treated##agegroup
Number of obs = 30 R-squared = 0.2671
Root MSE = 10.4418 Adj R-squared = 0.1144
Source | Partial SS df MS F Prob>F
-----------------+-------------------------------------------------
Model | 953.69755 5 190.73951 1.75 0.1617
|
treated | 685.56296 1 685.56296 6.29 0.0193
agegroup | 47.705927 2 23.852963 0.22 0.8051
treated#agegroup | 220.42867 2 110.21433 1.01 0.3789
|
Residual | 2616.7383 24 109.03076
-----------------+-------------------------------------------------
Total | 3570.4358 29 123.11848
模型的 统计量在统计上不显著 (,,,),但实验组的 统计量在统计上显著 (,,,)。
在 anova 命令之后,我们可以使用 estat esize 命令来计算该模型的 Eta 平方 () 和净 Eta 平方 () 估计值:
estat esize
Effect sizes for linear models
---------------------------------------------------------------
Source | Eta-Squared df [95% Conf. Interval]
------------------+--------------------------------------------
Model | .2671096 5 . .4067062
|
treated | .2076016 1 .0039512 .4451877
agegroup | .0179046 2 . .1458161
treated#agegroup | .0776932 2 . .271507
---------------------------------------------------------------
Note: Eta-Squared values for individual model terms are partial.
可以看出,,表示在 95% 置信区间 (包括零值) 下,模型方差变异在数学分数中占比 ;净 平方 ,表示剔出其他自变量的效应后,在 置信区间 (不包括零值) 下,实验组变异在数学分数中占比 。
我们也可以计算 族的 统计量:
estat esize, omega
Effect sizes for linear models
---------------------------------------------
Source | Omega-Squared df
----------------------+----------------------
Model | .1110334 5
|
treated | .169005 1
agegroup | -.0614232 2
treated#agegroup | .0008035 2
---------------------------------------------
Note: Omega-Squared values for individual model terms are partial.
其中,统计量参数有疑问的地方是,模型方差变异在数学分数中占 11.4%,但是模型中的实验组变异在数学分数中却占比 17.5%,这是由于统计量计算方式产生的误解,详细的说明可以参考 Pierce et al. (2004)。
由上述分析可知,除了 统计量置信区间包括 0,其余的统计量置信区间都不包括 0,因此我们不能排除不起作用的可能性。
最后,结果是否有意义还取决于研究的背景和观点。在某些情况下,占结果变异性的 5% 就是统计显著量,而在另外一些情况下,占比 30% 可能还不是统计显著的。
如果想要更深入的检验分组回归后的组间系数差异,我们可以使用 suest 和 bdiff 等命令,详见「连享会-Stata: 如何检验分组回归后的组间系数差异?」。
温馨提示: 文中链接在微信中无法生效。请点击底部
6. 参考文献
温馨提示: 文中链接在微信中无法生效。请点击底部
- Gelman A, Stern H. The difference between “significant” and “not significant” is not itself statistically significant[J]. The American Statistician, 2006, 60(4): 328-331. -Link- -Link-
- Berben L, Sereika S M, Engberg S. Effect size estimation: methods and examples[J]. International journal of nursing studies, 2012, 49(8): 1039-1047. -Link-
- Carver R. The case against statistical significance testing[J]. Harvard Educational Review, 1978, 48(3): 378-399. -Link-
- McShane B B, Gal D. Statistical significance and the dichotomization of evidence[J]. Journal of the American Statistical Association, 2017, 112(519): 885-895. -Link-
- Pierce C A, Block R A, Aguinis H. Cautionary note on reporting eta-squared values from multifactor ANOVA designs[J]. Educational and psychological measurement, 2004, 64(6): 916-924. -Link-
- 在追逐 p-value 的道路上狂奔,却在科学的道路上渐行渐远 -Link-
- 连享会-Stata: 如何检验分组回归后的组间系数差异? -Link-

? ? ? ?
连享会主页:? www.lianxh.cn
直播视频:lianxh.duanshu.com

免费公开课:
- 直击面板数据模型:https://gitee.com/arlionn/PanelData - 连玉君,时长:1小时40分钟
- Stata 33 讲:https://gitee.com/arlionn/stata101 - 连玉君, 每讲 15 分钟.
- 部分直播课课程资料下载 ? https://gitee.com/arlionn/Live (PPT,dofiles等)
温馨提示: 文中链接在微信中无法生效。请点击底部

关于我们
- ? 连享会 ( 主页:lianxh.cn ) 由中山大学连玉君老师团队创办,定期分享实证分析经验。
- ? 直达连享会:【百度一下:连享会】即可直达连享会主页。亦可进一步添加 主页,知乎,面板数据,研究设计 等关键词细化搜索。
- ? 公众号推文分类: 历史推文分为多个专辑,主流方法介绍一目了然:DID, RDD, IV, GMM, FE, Probit 等。
连享会 · 推文专辑:
Stata资源 | 数据处理 | Stata绘图 | Stata程序
结果输出 | 回归分析 | 时序 | 面板 | 离散数据
交乘调节 | DID | RDD | 因果推断 | SFA-TFP-DEA
文本分析+爬虫 | 空间计量 | 学术论文 | 软件工具 - ❓ 公众号关键词搜索/回复 功能已经上线。大家可以在公众号左下角点击键盘图标,输入简要关键词,以便快速呈现历史推文,获取工具软件和数据下载。常见关键词:
课程, 直播, 视频, 客服, 模型设定, 研究设计, 暑期班stata, plus,Profile, 手册, SJ, 外部命令, profile, mata, 绘图, 编程, 数据, 可视化DID,RDD, PSM,IV,DID, DDD, 合成控制法,内生性, 事件研究交乘, 平方项, 缺失值, 离群值, 缩尾, R2, 乱码, 结果Probit, Logit, tobit, MLE, GMM, DEA, Bootstrap, bs, MC, TFP,面板, 直击面板数据, 动态面板, VAR, 生存分析, 分位数空间, 空间计量, 连老师, 直播, 爬虫, 文本, 正则, pythonMarkdown, Markdown幻灯片, marp, 工具, 软件, Sai2, gInk, Annotator, 手写批注,盈余管理, 特斯拉, 甲壳虫, 论文重现,易懂教程, 码云, 教程, 知乎
? 连享会小程序:扫一扫,看推文,看视频……

? 扫码加入连享会微信群,提问交流更方便

? 连享会学习群-常见问题解答汇总:
? https://gitee.com/arlionn/WD
Stata 暑期班:9天直播
? 时间:2020.7.28-8.7
? 嘉宾:连玉君 (中山大学) | 江艇 (中国人民大学)
? 主页:https://gitee.com/arlionn/PX | ? 微信版「基础不牢,地动山摇……」

















 8754
8754

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









