







 本文深入探讨Transformer模型,它基于encoder-decoder架构,使用self-attention机制,避免了RNN的序列依赖问题。每个编码器层包含多头自注意力和前馈网络,解码器则在注意力机制中加入掩码以防止未来信息泄露。scaled dot-product attention是实现注意力的关键步骤,通过query、key和value的加权求和完成信息检索。
本文深入探讨Transformer模型,它基于encoder-decoder架构,使用self-attention机制,避免了RNN的序列依赖问题。每个编码器层包含多头自注意力和前馈网络,解码器则在注意力机制中加入掩码以防止未来信息泄露。scaled dot-product attention是实现注意力的关键步骤,通过query、key和value的加权求和完成信息检索。
文章目录
1 Abstract、Introduction、Background
主要提了一下目前主流的技术和优缺点包括RNN、LSTM、GRU、encoder、decoder等,这里就不过多赘述了。
2 Model Architecture
首先看一下模型的整体结构,Transformer总体上遵循了encoder-decoder架构,编码器和解码器都使用了self-attention层、point-wise和全连接层,分别如下图的左右两部分所示。

接下来详细介绍一个各个模块。
2.1 Encoder
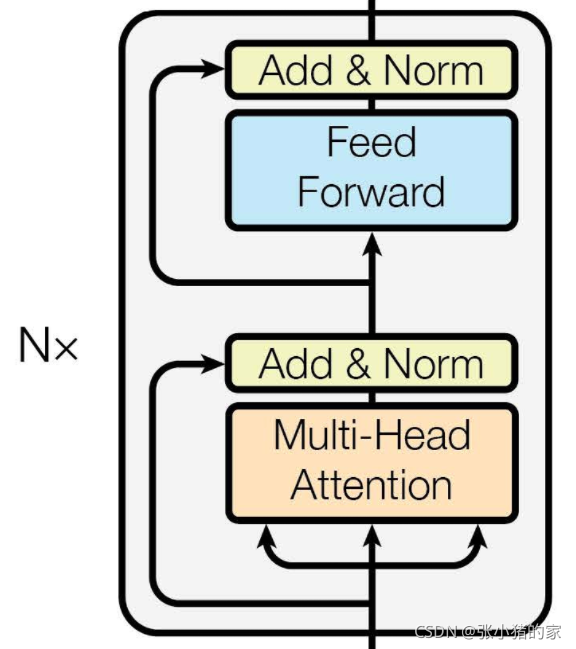
编码器是由6个相同的编码器层组成的。每个编码器层有两个子层。
- 第一个子层是multi-head self-attention(多头自注意力层)
- 第二个子层是feed-forward(前馈连接层)
同时在每个子层都加入了residual connection(残差网络)和 layer normalization层。因此每个子层的输出都是 L a y e r N o r m ( x + S u b l a y e r ( x ) ) LayerNorm(x+ Sublayer(x)) LayerNorm(x+Sublayer(x)),其中 S u b l a y e r ( x ) Sublayer(x) Sublayer(x)表示子层对输入 x x x做的映射。
为了方便残差连接,所有的模型中所有子层和embedding(词嵌入层)的维度都是512.
2.2 Decoder
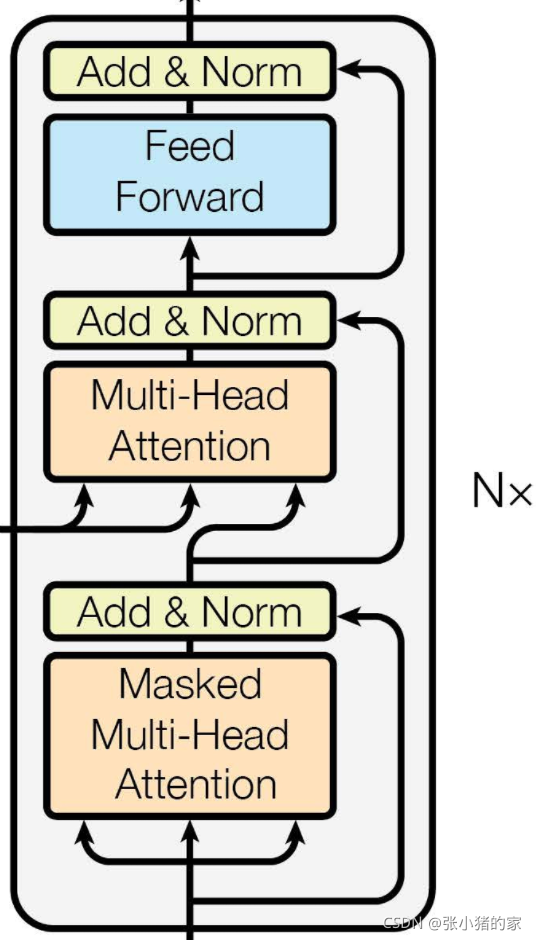
解码器与编码器类似,也是由6个相同的解码器层组成的,但是要注意每个编码器层的子层和编码器会有区别。每个解码器层有三个子层。
- 第一个子层在编码器层multi-head self-attention(多头自注意力层)上加入了mask(掩码张量),防止编码器看到未来的信息。
- 第二个子层是multi-head self-attention(多头自注意力层),但是要注意这一层的输入一部分来自编码器,另一部分来自于上一个解码器层。
- 第三个个子层是feed-forward(前馈连接层),和编码器类似。
其他没有提到的都和编码器类似。
2.3 Attention
attention计算可以描述为将一个query和一组key-value映射到output。
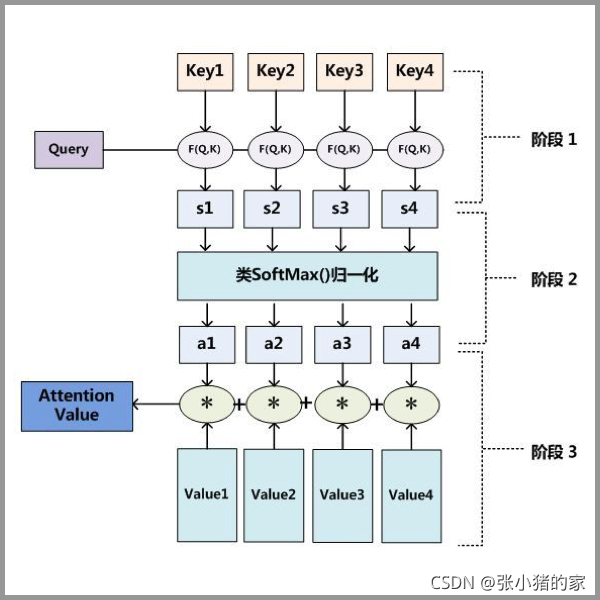
attention原理3步分解:
第一步: query 和 key 进行相似度计算,得到权值
第二步:将权值进行归一化,得到直接可用的权重
第三步:将权重和 value 进行加权求和
总体概况就是:带权求和
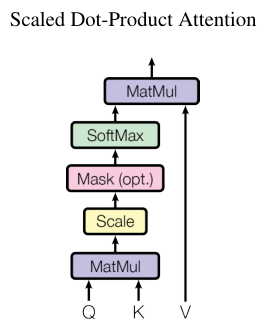
2.3.1 Scaled Dot-Product Attention
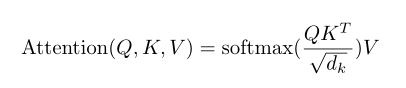

















 2105
2105

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









