









1.现在对针对bert的改进有哪些?
一方面,针对我们自己进行训练的模型,模型改进更多出现在微调网络的选择上。对于BERT的效果提升更多依赖于对数据的调整。另一方面,从整个NLP发展的角度,新型模型如ALBERT,XLNET都对BERT做了一系列的改进,如:为了降低参数量,动态mask,对Embedding矩阵进行因式分解,不同的encoder层进行参数共享;预训练数据去除主题影响,句子对使用相同主题来源,最后发现模型在100w步后仍然没有过拟合,移除dropout层。
2.fasttext和word2vec的区别?
首先,要明确它在说的fasttext是什么?我们学的fasttext工具有两个作用,也就是两个主要接口,文本分类和训练词向量,而我们学习的word2vec是什么,是如何进行词向量训练的理论。但大家要知道,word2vec是有这个工具的,同样实现word2vec还有gensim这样的工具包。所以更进一步,问的是原生的word2vec和fasttext在实现时的差异,到底加了哪些工程技巧呢?为了避免出现OoV(out of vocab)现象,设计了允许加入子词(subword)特征,同时对subword可以进行n-gram,以拓展词表。当然,我们知道,word2vec提供两种模式训练cbow和skipgram,他们的结构都是输出层,隐层和输出层,这些都属于全连接层,输出层就是全连接层+softmax,全连接层+softmax如果计算非常大,那可以怎么办呢?就是允许使用层次softmax。
3.分词方法有哪些,不用工具?
正向最大匹配,逆向最大匹配,双向最大匹配。
4. 为什么有时候会梯度不下降?都有什么情况可以导致这种情况?
首先应该想到,梯度消失;其次就是“鞍点”问题;模型工具构建的bug。
5. 一句话里面的关键字有错误的,怎么提取出来关键字,简单的复杂的层面都可以说说
query纠错即文本纠错是一项常见的NLP任务,一般可以分为两个步骤,错词定位和错词替换;基于规则的方法是比较常用的,我们需要统计该领域出现错别的基本情况,然后制定一些对应的规则词库,通过词库进行匹配。复杂一点的方法就是建模,错别字建模类似于NER,只不过标注一般是一个比较困难的阶段。
6.手写交叉熵损失函数推导
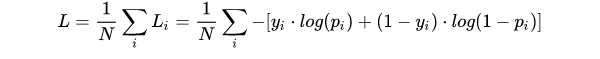
https://blog.youkuaiyun.com/weixin_39574469/article/details/119738371
7.卷积神经网络
https://blog.youkuaiyun.com/weixin_39574469/article/details/119785927
8.分类中解决类别不平衡问题
过采样
对训练集⾥的少数类进⾏“过采样”(oversampling),即增加⼀些少数类样本使得正、反例数⽬接近,然后再进⾏学习。
- 随机过采样:对少数类样本进⾏复制来扩⼤数据集
- SMOTE(Synthetic Minority Oversampling即合成少数类过采样技术):合成样本数据。
原理和思想:合成的策略是对每个少数类样本a,从它的最近邻中随机选一个样本b,然后在a,b之间的连线上随机选一点作为新合成的少数类样本。
欠采样
直接对训练集中多数类样本进⾏“⽋采样”(undersampling),即去除⼀些多数类中的样本使得正例、反例数⽬接近,然后再进⾏学习。
- 随机欠采样:去除⼀些多数类中的样本
9.缺失值处理
- 用中位数或平均值填充
- 删除缺失数据
10.python 中的yield和return的区别
-
yield返回的是一个生成器对象,该对象可以迭代遍历和通过next()方法取出对象中的值。
-
return结束该函数的运行,return后面的代码块不会执行,返回该函数的执行结果。
11.L1和L2正则化有什么区别
-
L1是模型各个参数的绝对值之和。
L2是模型各个参数的平方和的开方值。 -
L1会趋向于产生少量的特征,而其他的特征都是0.
因为最优的参数值很大概率出现在坐标轴上,这样就会导致某一维的权重为0 ,产生稀疏权重矩阵
L2会选择更多的特征,这些特征都会接近于0。
最优的参数值很小概率出现在坐标轴上,因此每一维的参数都不会是0。当最小化||w||时,就会使每一项趋近于0
12.100!后面几个0
结果中末尾0由以下三种情况生成:
(1)乘以100,得到2个0。
(2)乘以10、20、30、40、60、70、80或90得到1个0,共8个0。
(3)一个偶数乘以5得到1个0,共有5、15、35、45、55、65、85、95,共8个0。
(4)偶数乘以50会得到2个0。
(5)4乘以25或75各会得到2个0,共4个0。
故100!末尾共有24个0。
13.排序

14.快速排序
def Partition(nums, low, high):
pivot = nums[low]
while low < high:
while low < high and nums[high] >= pivot:
high -= 1
nums[low] = nums[high]
while low < high and nums[low] <= pivot:
low += 1
nums[high] = nums[low]
nums[low] = pivot
return low
def QuickSort(nums, low, high):
if low < high:
pivotpos = Partition(nums, low, high)
QuickSort(nums, low, pivotpos - 1)
QuickSort(nums, pivotpos + 1, high)
15.transformer变种
-
Universal Transformer(通用性优化)
- 在Transformer中,输入经过Attention后,会进入全连接层进行运算,而Universal Transformer模型则会进入一个共享权重的transition function继续循环计算
- 引入了TimeStep embedding,对position和time进行编码
-
Transformer-XL(编码长度优化)
- Transformer-XL将前一个segment的隐层缓存下来,后一个segment的self-attention计算,会使用到前一个segment的隐层。
- Transformer-XL将绝对位置编码改为了q和k之间的相对位置编码,代表了两个token之间的相对位置。
-
Reformer(计算效率优化)
- 先将相近的向量归为一类,然后只计算同类之间的点乘
- RevNet,减少内存使用
https://xieyangyi.blog.youkuaiyun.com/article/details/105980363
https://zhuanlan.zhihu.com/p/150801872
17.position embedding怎么实现的
- transformer:三角函数
- bert:通过学习得到
18.梯度爆炸梯度消失怎么解决
-
用ReLU等替代sigmoid函数
-
Batch Normalization
19.label_smoothing
在分类问题中,最后一层一般是全连接层,然后对应标签的one-hot编码,即把对应类别的值编码为1,其他为0。这种方式会鼓励模型对不同类别的输出分数差异非常大,或者说,模型过分相信它的判断。
标签平滑(Label-smoothing regularization,LSR)的具体思想是降低我们对于标签的信任。
20.其他attention
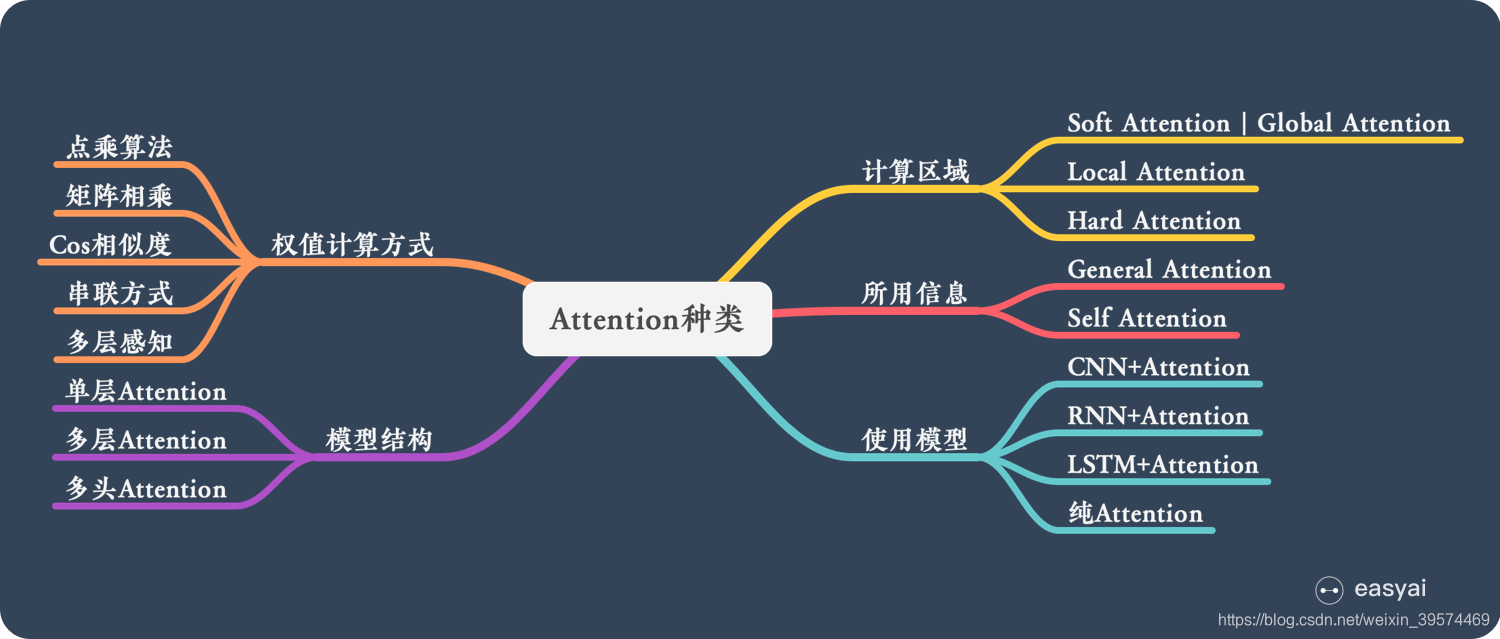
计算区域
1)Soft Attention,这是比较常见的Attention方式,对所有key求权重概率,每个key都有一个对应的权重,是一种全局的计算方式(也可以叫Global Attention)。这种方式比较理性,参考了所有key的内容,再进行加权。但是计算量可能会比较大一些。
2)Hard Attention,这种方式是直接精准定位到某个key,其余key就都不管了,相当于这个key的概率是1,其余key的概率全部是0。因此这种对齐方式要求很高,要求一步到位,如果没有正确对齐,会带来很大的影响。另一方面,因为不可导,一般需要用强化学习的方法进行训练。(或者使用gumbel softmax之类的)
3)Local Attention,这种方式其实是以上两种方式的一个折中,对一个窗口区域进行计算。先用Hard方式定位到某个地方,以这个点为中心可以得到一个窗口区域,在这个小区域内用Soft方式来算Attention。
所用信息
假设我们要对一段原文计算Attention,这里原文指的是我们要做attention的文本,那么所用信息包括内部信息和外部信息,内部信息指的是原文本身的信息,而外部信息指的是除原文以外的额外信息。
1)General Attention,这种方式利用到了外部信息,常用于需要构建两段文本关系的任务,query一般包含了额外信息,根据外部query对原文进行对齐。
2)self Attention,这种方式只使用内部信息,key和value以及query只和输入原文有关,在self attention中,key=value=query。既然没有外部信息,那么在原文中的每个词可以跟该句子中的所有词进行Attention计算,相当于寻找原文内部的关系。
结构层次
1)单层Attention,这是比较普遍的做法,用一个query对一段原文进行一次attention。
2)多层Attention,一般用于文本具有层次关系的模型,假设我们把一个document划分成多个句子,在第一层,我们分别对每个句子使用attention计算出一个句向量(也就是单层attention);在第二层,我们对所有句向量再做attention计算出一个文档向量(也是一个单层attention),最后再用这个文档向量去做任务。
3)多头Attention,这是Attention is All You Need中提到的multi-head attention,用到了多个query对一段原文进行了多次attention,每个query都关注到原文的不同部分,相当于重复做多次单层attention,最后再把这些结果拼接起来。
https://easyai.tech/ai-definition/attention/
21.bert输出
cls和每个token对应的输出向量
22.mutil-head self-attention 每个头初始化
随机初始化
23.warmup
由于刚开始训练时模型的权重(weights)是随机初始化的,此时选择一个较大的学习率,可能会带来模型的不稳定。学习率预热就是在刚开始训练的时候先使用一个较小的学习率,训练一些epoches或iterations,等模型稳定时再修改为预先设置的学习率进行训练。
24.FCM优缺点
相比起k-means的”硬聚类“,FCM方法会计算每个样本对所有类的隶属度,这给了我们一个参考该样本分类结果可靠性的计算方法,我们可以这样想,若某样本对某类的隶属度在所有类的隶属度中具有绝对优势,则该样本分到这个类是一个十分保险的做法,反之若该样本在所有类的隶属度相对平均,则我们需要其他辅助手段来进行分类。
算法在分类时有个主要的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。 该算法只计算“最近的”邻居样本,某一类的样本数量很大,那么或者这类样本并不接近目标样本,或者这类样本很靠近目标样本。无论怎样,数量并不能影响运行结果。
该方法的另一个不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。
25.最近读的论文
26.Adam和AdamW
- SDG
当用SGD落入局部最小点,梯度如果为0,会停下来。 - SDGM
加入类似惯性向量v,在落入局部最小值点时可以走出去。 - AdaGrad
SGD以及动量以同样的学习率更新每个参数。神经网络模型往往包含大量的参数,但是这些参数并不会总是用得到,更新频率也不一样。对于经常更新的参数,希望学习速率慢一些;对于偶尔更新的参数,即学习速率大一些。于是使用二阶动量:至今为止所有梯度值的平方和 - RMSProp(root mean square prop)
由于AdaGrad单调递减的学习率变化过于激进,考虑一个改变二阶动量计算方法的策略:不累加全部历史梯度,而只关注过去一段时间窗口的下降梯度 - Adam
SGDM在SGD的基础上增加了一阶动量,AdaGrad在SGD的基础上增加了二阶动量。Adam实际上就是将SGDM和RMSprop集合在一起,把一阶动量和二阶动量都使用起来了 - AdamW
在Adam中引入weight decay
https://www.haomeiwen.com/subject/qrnrmhtx.html
https://blog.youkuaiyun.com/yinyu19950811/article/details/90476956
https://zhuanlan.zhihu.com/p/129702058
27.transformer里encoder和decoder区别
- Decoder Block中的多头self-attention层
Decoder中的多头self-attention层与Encoder模块一致, 但需要注意的是Decoder模块的多头self-attention需要做look-ahead-mask, 因为在预测的时候"不能看见未来的信息", 所以要将当前的token和之后的token全部mask. - Decoder Block中的Encoder-Decoder attention层
这一层区别于自注意力机制的Q = K = V, 此处矩阵Q来源于Decoder端经过上一个Decoder Block的输出, 而矩阵K, V则来源于Encoder端的输出, 造成了Q != K = V的情况.
这样设计是为了让Decoder端的token能够给予Encoder端对应的token更多的关注.
28.transformer里的mask
sequence mask 是为了使得 decoder 不能看见未来的信息。也就是对于一个序列,在 time_step 为 t 的时刻,我们的解码输出应该只能依赖于 t 时刻之前的输出,而不能依赖 t 之后的输出。
https://blog.youkuaiyun.com/u012526436/article/details/86295971
29.position embedding绝对位置or相对位置
原始transformer是绝对位置,之后改进的transformer,比如transformer-XL使用的是相对位置
30.现在的研究方向、论文
31.bert相比于textCNN和textRNN的优势
32.roberta的改进
-
动态Masking
RoBERTa一开始把预训练的数据复制10份,每一份都随机选择15%的Tokens进行Masking,也就是说,同样的一句话有10种不同的mask方式。然后每份数据都训练N/10个epoch。这就相当于在这N个epoch的训练中,每个序列的被mask的tokens是会变化的。这就叫做动态Masking。 -
without NSP
- 两个语句拼接起来降低了单个语句长度(可能被截断),而长语句有利于模型学到更多信息,有利于预测mask
- NSP中的负样本,与当前语句关联度不大,不利于预测当前语句的mask。也就是NSP使得MLM任务引入了噪声
-
更大的mini-batch
-
更多的数据,更长时间的训练
https://www.jianshu.com/p/eddf04ba8545
33.self-attention计算公式
缩放系数是k的维度开根号,一般是8
34.矩阵旋转90度,180度
35.BN和LN
https://blog.youkuaiyun.com/weixin_39574469/article/details/120091192
35.1 batchnorm过程,公式描述,有什么作用训练和预测阶段有什么不同
https://blog.youkuaiyun.com/weixin_41888257/article/details/107431268
35.2 BN和dropout同时使用时要注意什么
https://blog.youkuaiyun.com/weixin_37947156/article/details/98763993
35.3 BN为什么能加快收敛:BN就是通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布,其实就是把越来越偏的分布强制拉回比较标准的分布,这样使得激活输入值落在非线性函数对输入比较敏感的区域,这样输入的小变化就会导致损失函数较大的变化,意思是这样让梯度变大,避免梯度消失问题产生,而且梯度变大意味着学习收敛速度快,能大大加快训练速度。经过BN后,大部分Activation的值落入非线性函数的线性区内,其对应的导数远离导数饱和区,这样来加速训练收敛过程。
37.交叉熵的优缺点(为什么要用交叉熵作为损失函数)
1.在用梯度下降法做参数更新的时候,模型学习的速度取决于两个值:一、学习率;二、偏导值。其中,学习率是我们需要设置的超参数,所以我们重点关注偏导值。使用逻辑函数得到概率,并结合交叉熵当损失函数时,当模型效果差的时,也会使得偏导值越大,学习速度越快,模型效果好时,学习速度会变慢。(sigmoid 型函数的导数形式易发生饱和(saturate,梯度更新的较慢)的缺陷。梯度更新较慢可以理解为sigmoid的斜率较小。)
2.采用了类间竞争机制,比较擅长于学习类间的信息,但是只关心对于正确标签预测概率的准确性,而忽略了其他非正确标签的差异,从而导致学习到的特征比较散。
https://zhuanlan.zhihu.com/p/35709485
https://blog.youkuaiyun.com/weixin_39788572/article/details/111499275
39.xgboost、lightgbm、GBDT
xgboost原理,xgboost特征选择,如何评估特征重要性,xgboost相比去gbdt的改进
https://github.com/NLP-LOVE/ML-NLP/blob/master/Machine%20Learning/3.3%20XGBoost/3.3%20XGBoost.md
40.Self-attention中dot-product操作为什么要被缩放
当输入较大时,softmax函数可能具有极小的梯度,难以有效学习
41.手写带mask矩阵的self-attention
def attention(query, key, value, mask=None, dropout=None):
"""注意力机制的实现, 输入分别是query, key, value, mask: 掩码张量,
dropout是nn.Dropout层的实例化对象, 默认为None"""
# 在函数中, 首先取query的最后一维的大小, 一般情况下就等同于我们的词嵌入维度, 命名为d_k
d_k = query.size(-1)
# 按照注意力公式, 将query与key的转置相乘, 这里面key是将最后两个维度进行转置, 再除以缩放系数根号下d_k, 这种计算方法也称为缩放点积注意力计算.
# 得到注意力得分张量scores
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
# 接着判断是否使用掩码张量
if mask is not None:
# 使用tensor的masked_fill方法, 将掩码张量和scores张量每个位置一一比较, 如果掩码张量处为0
# 则对应的scores张量用-1e9这个值来替换, 如下演示
scores = scores.masked_fill(mask == 0, -1e9)
# 对scores的最后一维进行softmax操作, 使用F.softmax方法, 第一个参数是softmax对象, 第二个是目标维度.
# 这样获得最终的注意力张量
p_attn = F.softmax(scores, dim = -1)
# 之后判断是否使用dropout进行随机置0
if dropout is not None:
# 将p_attn传入dropout对象中进行'丢弃'处理
p_attn = dropout(p_attn)
# 最后, 根据公式将p_attn与value张量相乘获得最终的query注意力表示, 同时返回注意力张量
return torch.matmul(p_attn, value), p_attn
42.常见的激活函数及优缺点
神经网络为什么需要激活函数:首先数据的分布绝大多数是非线性的,而一般神经网络的计算是线性的,引入激活函数,是在神经网络中引入非线性,强化网络的学习能力。所以激活函数的最大特点就是非线性。
https://zhuanlan.zhihu.com/p/92412922
https://zhuanlan.zhihu.com/p/73214810
42.1 relu解决的问题(优缺点)
42.2 LSTM三个门都没用ReLU
Relu这种无上限的函数容易造成梯度爆炸。
42.3 softmax与sigmoid
sigmoid
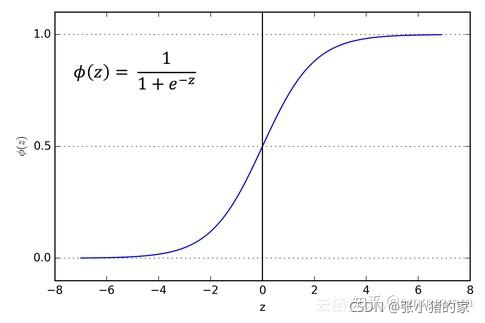
作用:从图片上可以看到,sigmoid是非线性的,所可以用在神经网络中间层中作为激活函数,也可以用在最后一层将结果映射到(0, 1)之间。
优点:
-
可以看到sigmoid函数处处连续,便于求导;
-
可以将函数值的范围压缩到[0,1],可以压缩数据,且幅度不变。
-
可以做二分类问题;
缺点: -
在输入很大的情况下,函数进入饱和区,函数值变化很小,使x对y的区分度不高,同时也容易梯度消失,不利于深层神经网络的反馈传输,反向传输时计算量大。
-
函数均值不为0,当输出大于0时,则梯度方向将大于0,也就是说接下来的反向运算中将会持续正向更新;同理,当输出小于0时,接下来的方向运算将持续负向更新。
softmax
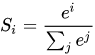
上面是softmax的表达式,softmax用于多分类问题,在多分类神经网络种,常常作为最后一层的激活函数,前一层的数值映射为(0,1)的概率分布,且各个类别的概率归一,从表达式中很容易看出来。与sigmoid不同的是,softmax没有函数图像,它不是通过固定的 [公式] 的映射将固定的值映射为固定的值,softmax是计算各个类别占全部的比例,可以理解为输入一个向量,然后出一个向量,输出的向量的个位置的元素表示原向量对应位置的元素所占整个向量全部元素的比例。
原始向量经过softmax之后,原始向量中较大的元素,在输出的向量中,对应位置上还是较大,反之,原始向量中较小的元素还是会很小,保留了原始向量元素之间的大小关系。在做多分类问题时,输出向量的第几维最大,就表示属于第几个class的概率最大,由此分类。
https://zhuanlan.zhihu.com/p/197343412
44.attention流程
高度概括:带权求和
Attention 原理的3步分解:
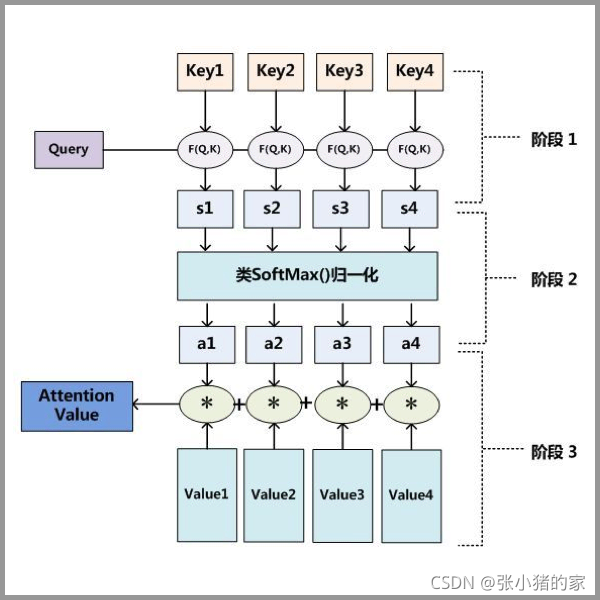
attention原理3步分解
第一步: query 和 key 进行相似度计算,得到权值
第二步:将权值进行归一化,得到直接可用的权重
第三步:将权重和 value 进行加权求和
45.内积和余弦相似度的区别,余弦相似度的缺点
余弦相似性其实是内积的归一化。
余弦距离只考虑了角度差,内积综合考虑了角度差和长度差。
余弦相似度更多的是从方向上区分差异,而对绝对的数值不敏感。
46.self-attention机制(k,v怎么得来的)
q,v,k都是由input乘上三个(可学习的)矩阵得来的。q,v,k虽然具体的初始化数值不同,但是代表着的都是input句子的单词。
47.树模型是如何求特征重要性的
- 包外估计
- 基尼值
https://zhuanlan.zhihu.com/p/77480254
48.进程线程区别
做个简单的比喻:进程=火车,线程=车厢
- 线程在进程下行进(单纯的车厢无法运行)
- 一个进程可以包含多个线程(一辆火车可以有多个车厢)
- 不同进程间数据很难共享(一辆火车上的乘客很难换到另外一辆火车,比如站点换乘)
- 同一进程下不同线程间数据很易共享(A车厢换到B车厢很容易)
- 进程要比线程消耗更多的计算机资源(采用多列火车相比多个车厢更耗资源)
- 进程间不会相互影响,一个线程挂掉将导致整个进程挂掉(一列火车不会影响到另外一列火车,但是如果一列火车上中间的一节车厢着火了,将影响到所有车厢)
- 进程可以拓展到多机,进程最多适合多核(不同火车可以开在多个轨道上,同一火车的车厢不能在行进的不同的轨道上)
- 进程使用的内存地址可以上锁,即一个线程使用某些共享内存时,其他线程必须等它结束,才能使用这一块内存。(比如火车上的洗手间)-“互斥锁”
- 进程使用的内存地址可以限定使用量(比如火车上的餐厅,最多只允许多少人进入,如果满了需要在门口等,等有人出来了才能进去)-“信号量”
49.dropout原理
在神经网络的训练过程中,对于一次迭代中的某一层神经网络,先随机选择中的一些神经元并将其临时隐藏(丢弃),然后再进行本次训练和优化。在下一次迭代中,继续随机隐藏一些神经元,如此直至训练结束。由于是随机丢弃,故而每一个mini-batch都在训练不同的网络。
- 在训练模型阶段
某个神经元以概率p停止工作,其实就是让它的激活函数值以概率p变为0。比如我们某一层网络神经元的个数为1000个,其激活函数输出值为y1、y2、y3、…、y1000,我们dropout比率选择0.4,那么这一层神经元经过dropout后,1000个神经元中会有大约400个的值被置为0。 - 在测试模型阶段
预测模型的时候,每一个神经单元的权重参数要乘以概率p。
50.浅拷贝和深拷贝的区别
浅拷贝(copy):拷贝父对象,不会拷贝对象的内部的子对象。
深拷贝(deepcopy): copy 模块的 deepcopy 方法,完全拷贝了父对象及其子对象。
https://www.cnblogs.com/xueli/p/4952063.html
51.最大后验和最大似然的区别
最大似然估计和最大后验估计的相同点是:都是通过调整模型的参数θ,使得观测样本出现的概率最大。不同点在于,最大后验估计认为,模型的参数θ服从某个分布,不是固定的。而最大似然估计则认为模型的参数θ是固定的。
52.常见的损失函数
https://zhuanlan.zhihu.com/p/58883095
53.正则化的原理
在学习的时候,数据提供的特征有些影响模型复杂度或者这个特征的数据点异常较多,所以算法在学习的时候尽量减少这个特征的影响(甚⾄删除某个特征的影响),这就是正则化
54.lstm原理三个门作用和sigmoid函数tanh使用,梯度消失问题如何解决,rnn为什么不能,缺点如何造成的。lstm如何解决长期记忆问题
LSTM实现长期记忆不仅仅是依靠门控,还有cell状态。
在前向传播中,如果将输入的一串序列当做一部戏剧,那么LSTM的cell就是记录下的主线,而遗忘门,输入门都用于给主线增加一些元素(比如新的角色,关键性的转机)。通过训练,遗忘门能够针对性地对主线进行修改,选择“保留”或是“遗忘”过去主线中出现的内容,输入门用于判断是否要输入新的内容,并且输入内容。输出门则用于整合cell状态,判断需要把什么内容提取出来传递给下一层神经元。而RNN只是每一层接受上一幕的情景以及对以前情景越来越模糊的记忆,进行下一步传递,虽然运算很快,写法简单,但是无法处理长时间依赖的数据
LSTM和RNN一样都会有梯度爆炸(千万记住),都需要进行梯度裁剪,防止Inf和NaN的出现。之所以LSTM能比RNN更好地应对梯度消失,原因要从反向传播的过程中去找。
一般情况下我们用RNN的时候,使用的激励函数是tanh,tanh的导数范围在[0,1]之间,且在自变量为0的时候导数为1,这就直接导致了在不断往反向传播的过程中,反复乘以小于1的数,不需要经过几个time step,梯度就会变得非常非常小,出现梯度消失。
而LSTM的神经元中与输入数据有关的有三个sigmoid和一个tanh。sigmoid的导数范围在[0,0.25]之间,且在自变量为0的时候导数取最大值0.25。那么在不考虑权重等等影响条件下,三个sigmoid和一个tanh控制的门在反向传播中都要接受上一层的梯度,并且在这一层进行整合,在最好的情况下,几乎等同于乘以3*0.25+1,显然是大于1的(所以如果参数设置不太好的话,每次都乘大于1的数,会梯度爆炸),不过介于每一个time step不一定都是这种情况,所以要乘以的数值的分布基本上很均匀,有小于1和大于1的,一定程度上可以缓解梯度消失。
55.lr特征为什么要离散化
- 计算简单:稀疏向量内积乘法运算速度非常快,计算结果方便存储,容易scalable(扩展)。
- 增强模型的泛化能力,不易受噪声的影响:离散化后的特征对异常数据有很强的鲁棒性: 比如一个特征是年龄>30是1,否则是0。如果特征没有离散化,一个异常数据"年龄300岁"会给模型造成很大的干扰。
56.auc的含义
随机给定一个正样本和一个负样本,用一个分类器进行分类和预测,该正样本预测为正的概率比该负样本的预测为正的概率要大的概率。
57.数据不平衡对auc有影响吗,还有什么指标可以针对不平衡数据
没有影响
它是比较“正样本预测分 & 负样本预测分”数值相对大小关系。如若数据比例不同,模型预测分预测值绝对大小会因此而改变,但是相同分类器对于正负样本的区分能力是一定的。
https://www.jianshu.com/p/2ea03ccdb026
https://blog.youkuaiyun.com/Queen0911/article/details/109693384
58.深度网络loss除以10和学习率除以10是不是等价的?
https://www.zhihu.com/question/320377013
59.Bert的双向体现在什么地方
Bert可以看作Transformer的encoder部分。Bert模型舍弃了GPT的attention mask。双向主要体现在Bert的预训练任务一:遮蔽语言模型(MLM)。如:
小 明 喜 欢 [MASK] 度 学 习 。
这句话输入到模型中,[MASK]通过attention均结合了左右上下文的信息,这体现了双向。
attention是双向的,但GPT通过attention mask达到单向,即:让[MASK]看不到 度 学 习这三个字,只看到上文 小 明 喜 欢 。
https://zhuanlan.zhihu.com/p/69351731
60.bert 的三种embedding,具体实现细节
token embedding
输入文本在送入token embeddings 层之前要先进行tokenization处理。此外,两个特殊的token会被插入到tokenization的结果的开头 ([CLS])和结尾 ([SEP]) 。 tokenization使用的方法是WordPiece tokenization.
segment embedding
Bert在处理句子对的任务时,需要区分句子对中的上句/下句,因此用segment embedding来做识别。上句所有token的segment embedding均相同,下句所有token的segment embedding也相同;换句话说,如果是句子对,segment embedding只会有两种值。如果任务为单句的话,那segment embedding只有一个值。
position embedding
与transformer不同的是,Bert的position embedding是学习出来的。相同的是,position embedding仍然用的是相对位置编码。
60.1 Bert的position embedding是怎么学习出来的
https://www.jianshu.com/p/ff933b18d196
61.word2vec ,分层softmax和负采样什么时候用分层softmax,什么时候用负采样
-
分层softmax
根据单词出现频率构建好的huffman树,沿着路径从根节点到对应的叶子节点,一层一层的利用sigmoid函数做二分类,判断向左还是向右走,规定沿着左子树走,那么就是负类(霍夫曼树编码1),沿着右子树走,那么就是正类(霍夫曼树编码0)。一路上的概率连乘,最终得到某个单词的输出概率。 -
负采样
通过负采样,在更新隐层到输出层的权重时,只需更新负采样的单词,而不用更新词汇表所有单词,从而节省巨大计算量。
hierarchical softmax (对罕见词效果更好) vs negative sampling (对常见词效果更好,对低维度的词效果更好)
https://zhuanlan.zhihu.com/p/86680049
61.1 为什么要用负采样或者hierarchical softmax优化?
最大的问题在于从隐藏层到输出softmax层的计算量很大,因为要计算所有词的softmax概率,再去找概率最大的值作为当前输入的网络输出。并且在隐层到输出层的权重更新时,每一个样本迭代时,都会更新矩阵的所有元素。
可以看softmax的计算公式, f ( x ) = e x / s u m ( e i x ) f(x) = e^x / sum( e^x_i ) f(x)=ex/sum(eix) ,需要对所有的词e^x求和,复杂度O(V)。当V非常大的时候,计算量难以忍受。
62.过拟合
原因:
- 主要原因是训练数据中存在噪音或者训练数据太少,或训练集和测试集特征分布不一致
- 根本的原因则是特征维度(或参数)过多,导致模型完美拟合训练集,对新数据的预测结果较差
解决方法:
- simpler model structure:减小模型复杂度(缩小宽度和减小深度)
- data augmentation:随机drop和shuffle、同义词替换、回译、文档裁剪…
- regularization
- dropout
- early stopping
- 重新清洗数据,导致过拟合的⼀个原因也有可能是数据不纯导致的,如果出现了过拟合就需要我们重 新清洗数据。
- 增⼤数据的训练量,还有⼀个原因就是我们⽤于训练的数据量太⼩导致的,训练数据占总数据的⽐例 过⼩。
63.focal loss
Focal loss主要是为了解决one-stage目标检测中正负样本比例严重失衡的问题。该损失函数降低了大量简单负样本在训练中所占的权重,也可理解为一种困难样本挖掘。
One-stage:直接回归物体的类别概率和位置坐标值(无region proposal),但准确度低,速度相遇two-stage快。
Two-stage:先由算法生成一系列作为样本的候选框,再通过卷积神经网络进行样本分类。
65.长文本处理
- 截断法
文本截断只能保留510个token,如果是篇章级,文本长度好几千,如果直接使用截断法,必然会丢失大量信息。
如果采用头部加尾部截断的方法会导致上下文不连贯。
- Pooling法
将一个整段的文本拆分为多个segment,每一个segment的长度小于510。每一个segment都通过BERT,对得到的[CLS]进行Pooling。可以是用Max-Pooling、Mean-Pooling。亦或将 Max-Pooling、Mean-Pooling进行concat,然后再通过一个FC。如果考虑性能、只能使用一个Pooling的话,就使用Max-Pooling,因为捕获的特征很稀疏、Max-Pooling会保留突出的特征,Mean-Pooling会将特征打平。这一点和TextCNN后接Max-Pooing是一个道理。
优点:
- Pooling法将所有序列都放入模型之中。考虑到了全局的信息,对文本很长且截断敏感的任务有较好的效果
缺点:
- 性能较差,原来截断法需要encode一次,Pooling法需要encode多次,篇章越长,速度越慢。
- segment之间的联系丢失。
66.nlp样本不均衡(尤其是少样本)
增、删、换、替【随机增加、删除词、词序交换、同义词替换】
生成【回译、生成模型】
长文本一条截成两条
https://blog.youkuaiyun.com/Matt_sh/article/details/106003613
https://blog.youkuaiyun.com/xixiaoyaoww/article/details/104688002
67.截断后问题不连续怎么解决
transformer-XL
68.多分类用准确率有什么问题
https://www.cnblogs.com/zhouyc/p/12505294.html
69.rnn的过程
它的输入有两部分, 分别是h(t-1)以及x(t), 代表上一时间步的隐层输出, 以及此时间步的输入, 它们进入RNN结构体后, 会"融合"到一起, 这种融合我们根据结构解释可知, 是将二者进行拼接, 形成新的张量[x(t), h(t-1)], 之后这个新的张量将通过一个全连接层(线性层), 该层使用tanh作为激活函数, 最终得到该时间步的输出h(t), 它将作为下一个时间步的输入和x(t+1)一起进入结构体. 以此类推.
69.1 LSTM
遗忘门结构分析:
与传统RNN的内部结构计算非常相似, 首先将当前时间步输入x(t)与上一个时间步隐含状态h(t-1)拼接, 得到[x(t), h(t-1)], 然后通过一个全连接层做变换, 最后通过sigmoid函数进行激活得到f(t), 我们可以将f(t)看作是门值, 好比一扇门开合的大小程度, 门值都将作用在通过该扇门的张量, 遗忘门门值将作用的上一层的细胞状态上, 代表遗忘过去的多少信息, 又因为遗忘门门值是由x(t), h(t-1)计算得来的, 因此整个公式意味着根据当前时间步输入和上一个时间步隐含状态h(t-1)来决定遗忘多少上一层的细胞状态所携带的过往信息.
输入门结构分析:
我们看到输入门的计算公式有两个, 第一个就是产生输入门门值的公式, 它和遗忘门公式几乎相同, 区别只是在于它们之后要作用的目标上. 这个公式意味着输入信息有多少需要进行过滤. 输入门的第二个公式是与传统RNN的内部结构计算相同. 对于LSTM来讲, 它得到的是当前的细胞状态, 而不是像经典RNN一样得到的是隐含状态.
细胞状态更新分析:
细胞更新的结构与计算公式非常容易理解, 这里没有全连接层, 只是将刚刚得到的遗忘门门值与上一个时间步得到的C(t-1)相乘, 再加上输入门门值与当前时间步得到的未更新C(t)相乘的结果. 最终得到更新后的C(t)作为下一个时间步输入的一部分. 整个细胞状态更新过程就是对遗忘门和输入门的应用.
输出门结构分析:
输出门部分的公式也是两个, 第一个即是计算输出门的门值, 它和遗忘门,输入门计算方式相同. 第二个即是使用这个门值产生隐含状态h(t), 他将作用在更新后的细胞状态C(t)上, 并做tanh激活, 最终得到h(t)作为下一时间步输入的一部分. 整个输出门的过程, 就是为了产生隐含状态h(t).
69.2 GRU
和之前分析过的LSTM中的门控一样, 首先计算更新门和重置门的门值, 分别是z(t)和r(t), 计算方法就是使用X(t)与h(t-1)拼接进行线性变换, 再经过sigmoid激活. 之后重置门门值作用在了h(t-1)上, 代表控制上一时间步传来的信息有多少可以被利用. 接着就是使用这个重置后的h(t-1)进行基本的RNN计算, 即与x(t)拼接进行线性变化, 经过tanh激活, 得到新的h(t). 最后更新门的门值会作用在新的h(t),而1-门值会作用在h(t-1)上, 随后将两者的结果相加, 得到最终的隐含状态输出h(t), 这个过程意味着更新门有能力保留之前的结果, 当门值趋于1时, 输出就是新的h(t), 而当门值趋于0时, 输出就是上一时间步的h(t-1).
70.内接圆
假定一小球能够均匀地扔到一个正方形中,计算落入其中的点个数。通过计数其中落入内切圆的小球的个数。
该方法得到的要得到π的精度与投入点的个数有关,一般个数较大时精度比较高。
71.bn训练和测试的区别
72.bert分词方法
73.F1-macro
73.lstm防止梯度消失梯度爆炸
74.python字典实现原理
字典插入
75.哈希
76.pytorch model.train model.val
77.堆
78.kr散度


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









