



 本文介绍一种单目视频无监督学习方法,解决移动物体干扰和尺度一致性问题,提出几何一致性损失函数及自发现掩膜技术。
本文介绍一种单目视频无监督学习方法,解决移动物体干扰和尺度一致性问题,提出几何一致性损失函数及自发现掩膜技术。
Unsupervised Scale-consistent Depth and Ego-motion Learning from Monocular Video
一、介绍
现在已经有基于深度学习的使用单目单帧序列进行无监督的深度和自运动预测的方法。但是存在以下两个问题:
- 真实场景下往往都会出现移动物体,这与潜在的三维重建场景下的静态假设相违背,会影响重建结果。
- 缺乏一致性约束,长序列下的重建和位姿估算结果可能会出现尺度不一致。
为了解决以上问题,本文设计实现了一种几何一致性损失函数,并基于此生成自发现的针对移动物体的掩膜,具体可达成以下目标:
- 论文提出几何一致性约束迫使深度、位姿估计网络在长视频序列预测中同时保证尺度一致性,最终得到的位姿估计模块可保证全局尺度一致;
- 由1)中提出的几何一致性约束可生成自发现的针对移动物体的掩膜,这一点具体原理之后阐述。通过在学习中为掩膜部份的像素分配极小权重,可以将这些部分的光学损失值降档最小从而减轻移动物体对网络训练的影响。这样的方法比直接引入光流、语义分割网络的代价小很多,同时保证高效、轻量;
- 最终的深度估计模块在KITTI数据集实现了SOTA的结果,位姿估计模块与其他SOTA的基于双目的模型相比,也很有竞争力;
二、设计实现
这里略过光学损失和光滑度损失的介绍,主要介绍论文提出的两个主要模块。
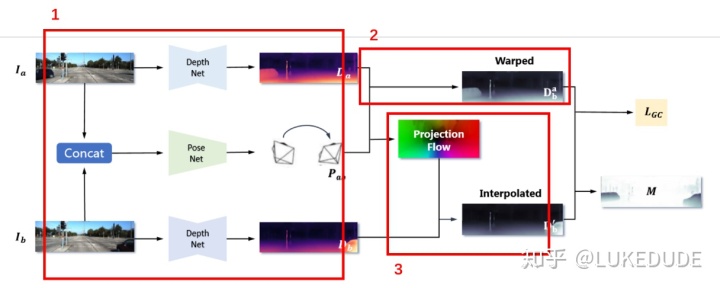
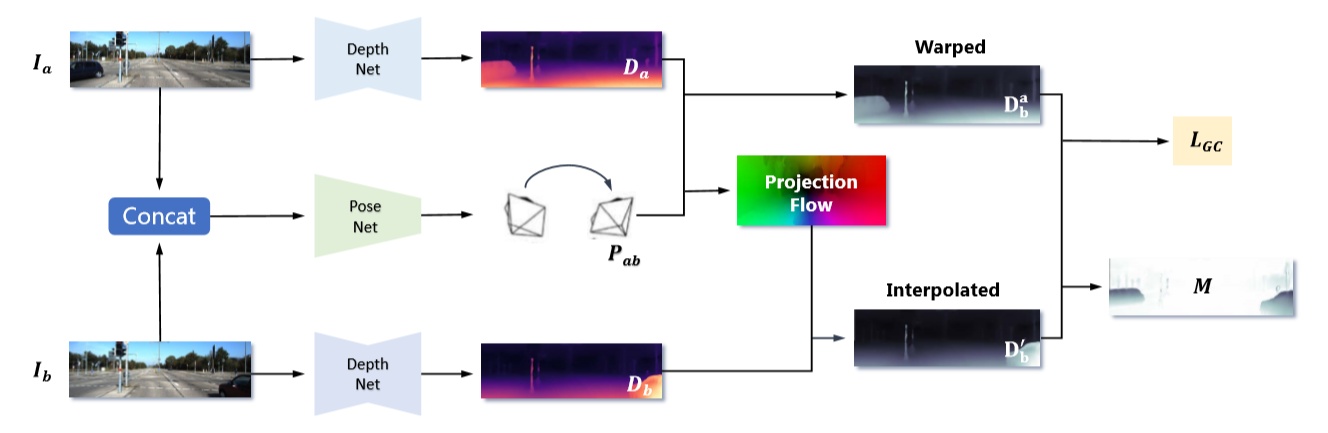
红框1:实验使用了DispNet和DispRes-Net作为深度估测部份的网络,输入单张RGB图像输出深度估计结果图。位姿估计部分使用的是PoseNet模型,有前后两个时刻的RGB图像估计相对位姿变换(6D)。在实验中,分别进行三项预测,如红框内所示;
红框2:通过对基于前帧的深度估计图和位姿变换预测,对深度图进行变形,投射到后帧的位姿下,生成
红框3:不能直接使用后帧的深度估计结果,因为真实场景变换流不是发生在像素点上的,使用插值对原生成深度图进行转换,生成可与
1. Geometry consistency loss
比较上述提到的,由前帧深度图进行位姿变换后的结果
最终几何一致性约束损失函数
其中
关键问题1:几何一致性约束是如何保证尺度一致性的?
论文中给出的解释很直觉,其实与本身几何一致性损失函数的原理没有关系,最重要的是该损失函数作为约束同时施加到了前后两帧的深度估计和帧间位姿变换估计两个模块上(如图1)。光学损失和光滑度损失都是单一模块设置的,而几何一致性约束迫使两个模块不得不达成统一,否则深度差值当然不会缩小。而这种一致性保证是可传递的,由当前两帧的预测比较可传递到接下来两帧的预测比较中。
2. Self-discovered mask
关键问题2:几何一致性约束是如何提供自发现掩膜的?
可以假设,相机在前后帧间的位姿变换是有限的,因此当前图像内的大部分目标的深度变化,在前后帧间应当也是十分有限的。因此(1)式中几何一致性约束对于前后两帧深度差值的定义
另外,由(1)式的差值设定,一般单个验证点的差值在0~1间移动,集体均值也当然如此。好处有如下:
- 所有点位不管具体的处于何种深度都将被平等对待进行优化,相较于拿真实深度差作为定义;
- 损失函数值相对均匀,分布在0~1之间,有利于训练阶段的数字稳定性;
- 自己理解的,将差值设定在0~1之间,我们就自然而然可以将其视作一个概率值,将
自然当作该点位是否存在正在移动的目标物体的概率值,这也是之后根据差值分配掩膜权重所用的;
如(2)式中,我们为光学损失分配掩膜权重,降低移动物体在深度估计中造成的影响,这一掩膜权重就是自几何一致性约束中包含的差值定义的。最终分配权重即为:
如c中的理解,也代表了判断当前点位是否包含移动目标的概率值。
三、实验结果
1) 深度估计模块评估
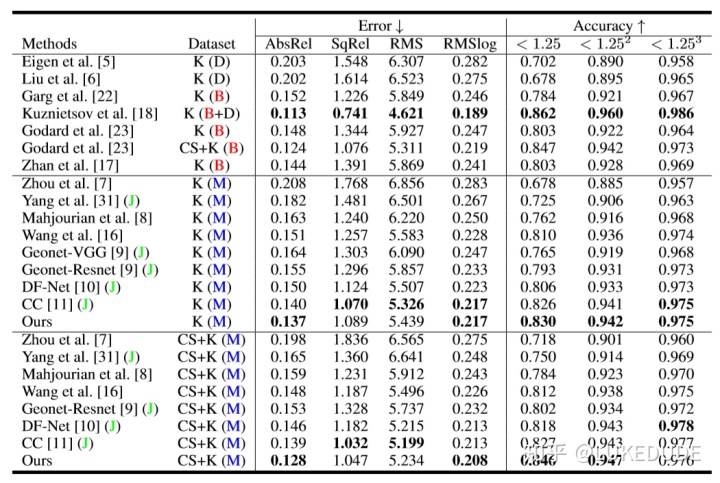
其中:K代表使用KITTI数据集进行训练测试,CS代表使用CityScape数据集进行预训练,(D)代表包含深度标注(有监督),(B)基于双目,(M)基于单目,(J)包含多任务。可以看出在基于单目的模型中,该论文提出的方法取得了SOTA的结果,与基于双目的方法相比,也很有竞争力。
2) 位姿估计模块评估
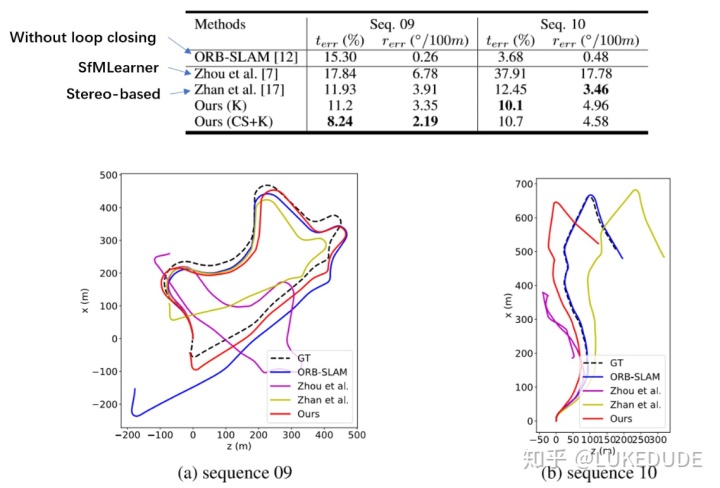
选取00~08几条通道进行位姿估计模块的训练,09~10两条通道作为测试。其中在通道09的测试中取得了很好的结果。
3) Ablation Study
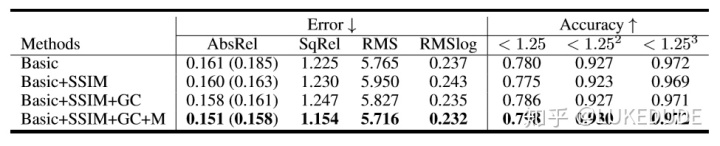
证实了几何一致性约束(GC)和自发现掩膜(M)的有效性。
公开源码:
SC-SfMLearner源码github.com
















 430
430

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









