






 本文介绍了如何使用Stata的一键显著命令解决回归结果不显著的问题。通过该命令,可以对备选控制变量进行排列组合,筛选出符合显著性和符号条件的模型。适用于经济管理、社科领域的学生和研究人员,旨在帮助完善论文逻辑和模型选择,但强调模型应基于研究内容确定,不应过度依赖工具。
本文介绍了如何使用Stata的一键显著命令解决回归结果不显著的问题。通过该命令,可以对备选控制变量进行排列组合,筛选出符合显著性和符号条件的模型。适用于经济管理、社科领域的学生和研究人员,旨在帮助完善论文逻辑和模型选择,但强调模型应基于研究内容确定,不应过度依赖工具。
众所周知,Stata是在实证研究中常用统计软件。但是,在确定了论文逻辑甚至花高价找到需要的数据、参考了文献确定模型后,却在实证中没有得到显著的结果,后续论文的推进更是难上加难!
导师总说这个不显著,自己又不懂怎么才能将最后结果变成显著,最佳模型也不会选择。
不懂计量、不会操作、不知道什么模型最适合?
在寻找合适的模型中不断尝试新的模型
确定模型但是变量回归结果一直没办法在显著区间内
又要不断的筛选变量,多次重复过程寻找最佳结果。
不断尝试的痛苦还没有成效,怎么办?
为此,我们 宝气老师制作了一套Stata命令,压榨所有手头上的数据来筛选符合研究者要求的结果,让大家在论文开始之前对手头的数据和前期的逻辑有一个清楚的认识,避免后期陷入结果不显著的尴尬境地。
1
大杀器:一键显著命令
1、原理
我们对备选控制变量进行排列组合,将每个组合都代入模型进行回归,然后根据前期设置的要求,来筛选出符号显著性水平和正负号条件(可选选项)的模型。示例如下:
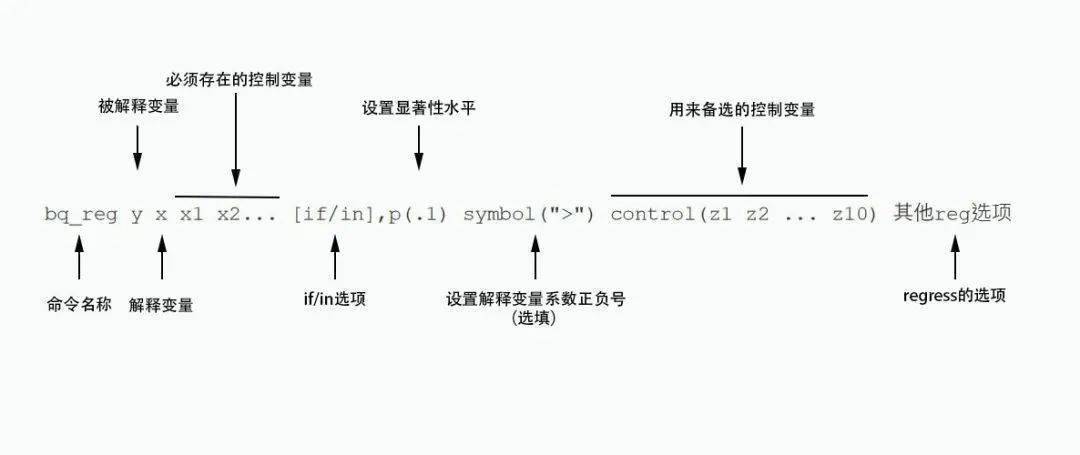
上图演示bq_reg的命令,意味着
(1)将z1-z10共十个备选控制变量进行排列组合(共1023组
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2079
2079

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









