







Ex.1: Merge Intervals
Given a collection of intervals, merge all overlapping intervals.
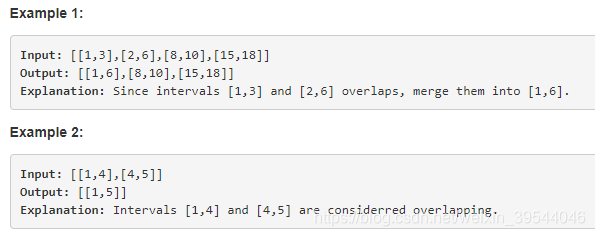
Solution:
分三种情况讨论
- 两不相交,这个情况选择跳过。比如[1,2],[3,4]
- 相交,通过前一个的end和后一个的start比较,符合条件则合并。如,[1,3],[2,4] -> [1,4]
- 包含,先判断2的情况,如果符合2,则判断前一个的end和下一个end的比较。若属于包含关系,则只添加大的那个区间.
def merge(intervals):
# 传入的intervals为二维列表,第二维的大小为2,如[[1,2],[3,4]]
# 确保区间之间的有序,根据每个区间的start排序
intervals.sort(key = lambda x:x[0])
# 定义合并后的区间
merged = []
for interval in intervals:
# merge为空或没有重合的情况,直接添加
if not merged or merged[-1][1] < interval[0]:
merged.append(interval)
# 否则合并,即判断当前merge最后一个的右区间和interval的右区间大小
else:
merged[-1][1] = max(merged[-1][1], interval[1])
return merged
intervals = [[2,4],[1,3],[5,6]]
merge(intervals)优化:in_place
只使用内部空间
def merge_in_place(intervals):
# 传入的intervals为二维列表,第二维的大小为2,如[[1,2],[3,4]]
# 确保区间之间的有序,根据每个区间的start排序
intervals.sort(key = lambda x:x[0])
flag = 0 # 0表示前后不重合,1表示重合
for i in range(0, len(intervals) - 1):
# 由于在intervals内部操作,intervals会一直变小,因此需要判断是否已经遍历完intervals
if len(intervals) - 1 - i <= 0:
break
# 两不相交
if intervals[i][1] < intervals[i+1][0]:
continue
# 需要合并的情况
else:
# 相交不包含
if intervals[i][1] < intervals[i+1][1]:
intervals[i][1] = intervals[i+1][1]
# 不管包含与否都要删除后面那个区间
intervals.remove(intervals[i+1])
# i一定要回退一位,因为remove掉后面的区间后i再+1的话会跳到原来的下下个区间,
# 比如[[1,3],[2,4],[5,7],[6,8]], i在[1,3]的时候发现要remove[2,4],remove后变成[[1,4],[5,7],[6,8]],而此时i指在[1,4]上面
# 到下一轮循环的时候,i会指到[5,7],而我们是希望i指在[1,4]然后去判断[1,4]和[5,7]的关系,因此i一定要回退
i = i - 1
return intervals
intervals = [[2,4],[1,3],[5,7],[6,8]]
merge_in_place(intervals) 
















 416
416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









