






python基础19(一)_初识scrapy以及管道_2025.3.29~31
摘要:scrapy项目的创建和基础运用
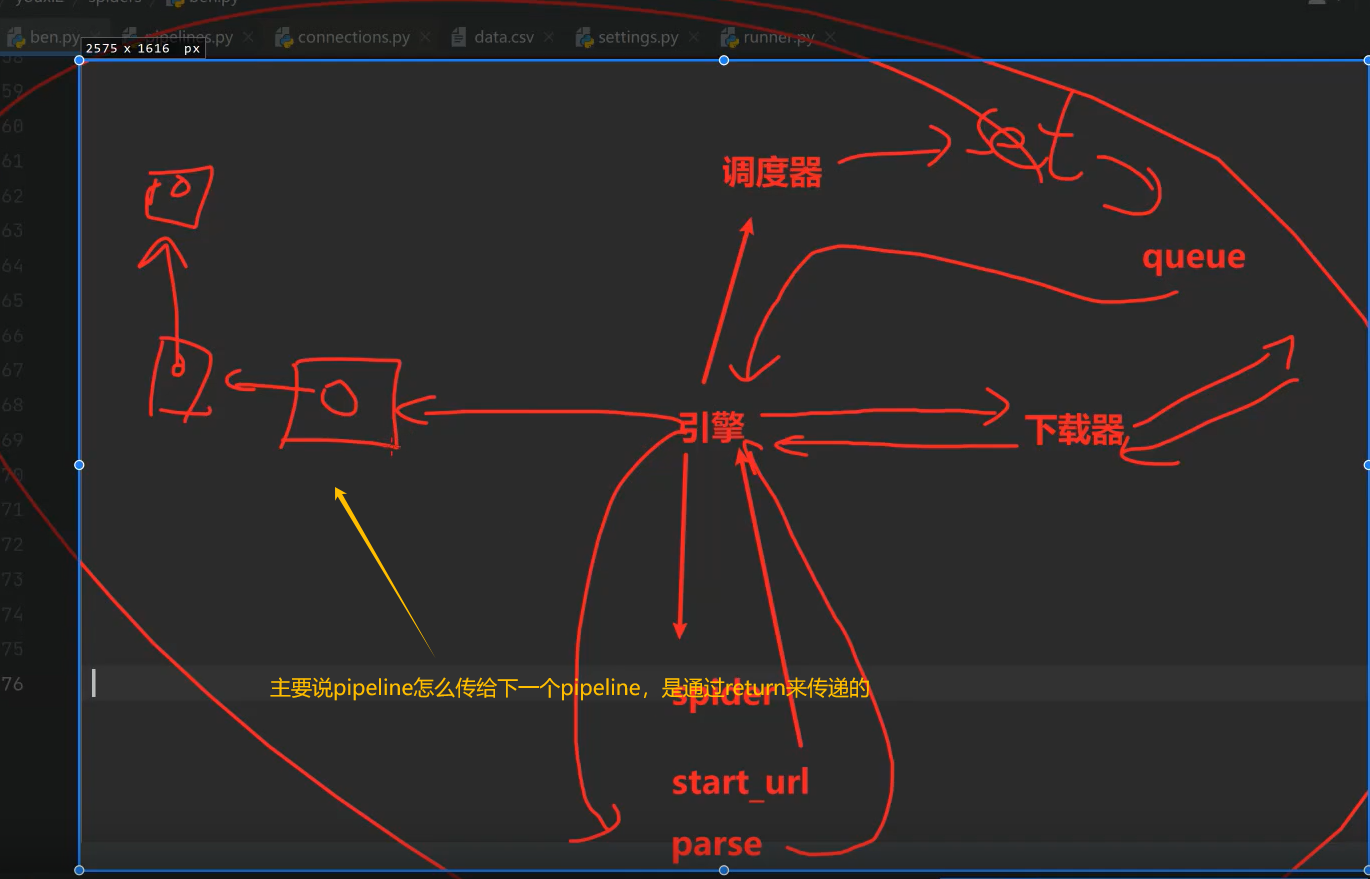
一、scrapy概念:
(一)对比之前代码
发送请求,解析数据,保存数据这几个模块。scrapy已经帮我们划分好了。
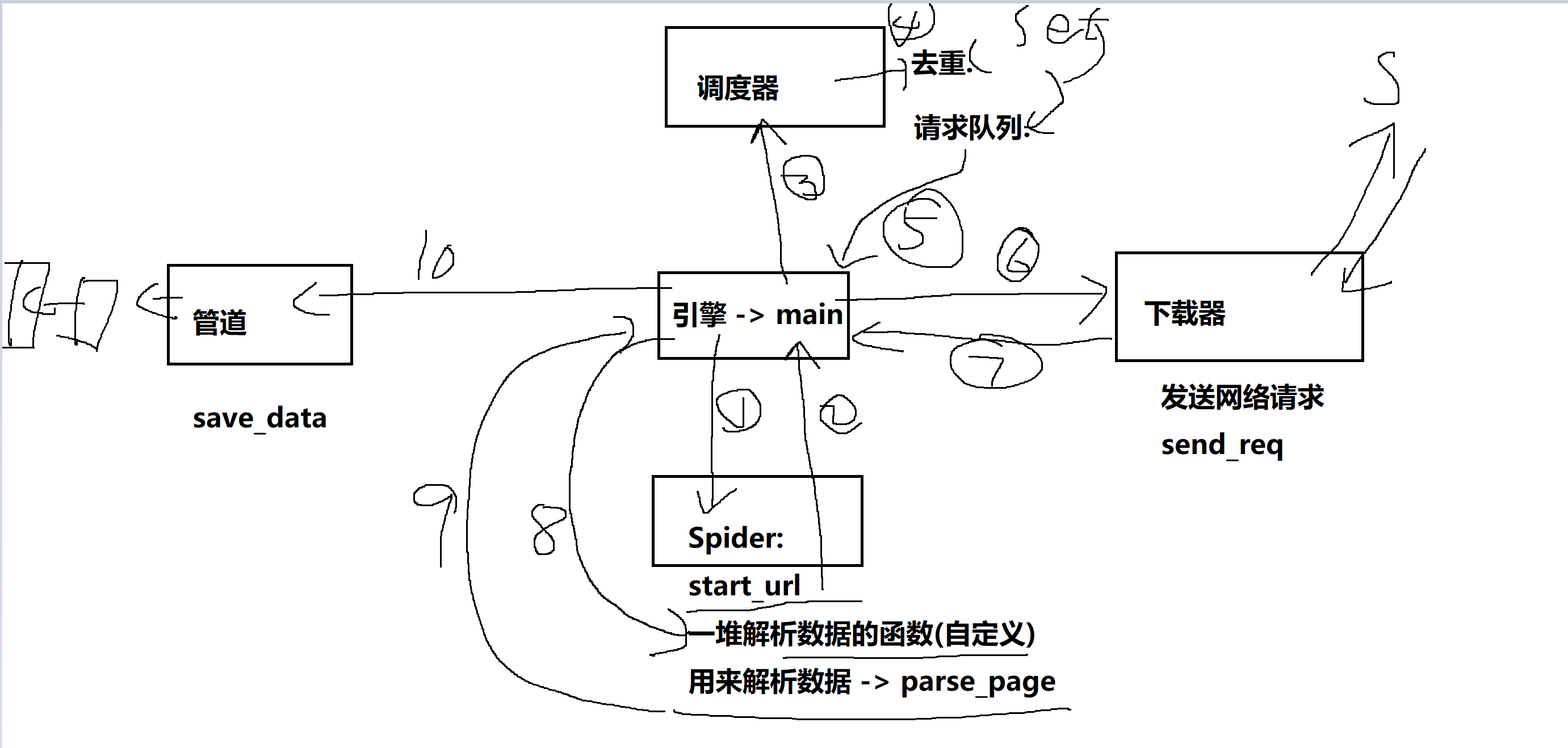
(二)图片:说明scrapy流程
(三)、安装
方式一:命令
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scrapy==2.11.2
pip install scrapy==2.11.2
方式二:setting中安装
二、创建scrapy项目:
命令一:scrapy startproject 项目名称
命令二:srapy genspider example example.com
这里项目名称取名“youxi,先进入文件youxi的目录(命令二,是创建spider的!上面是创建项目的,不要搞混!)
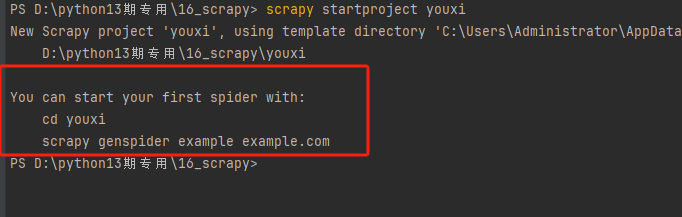
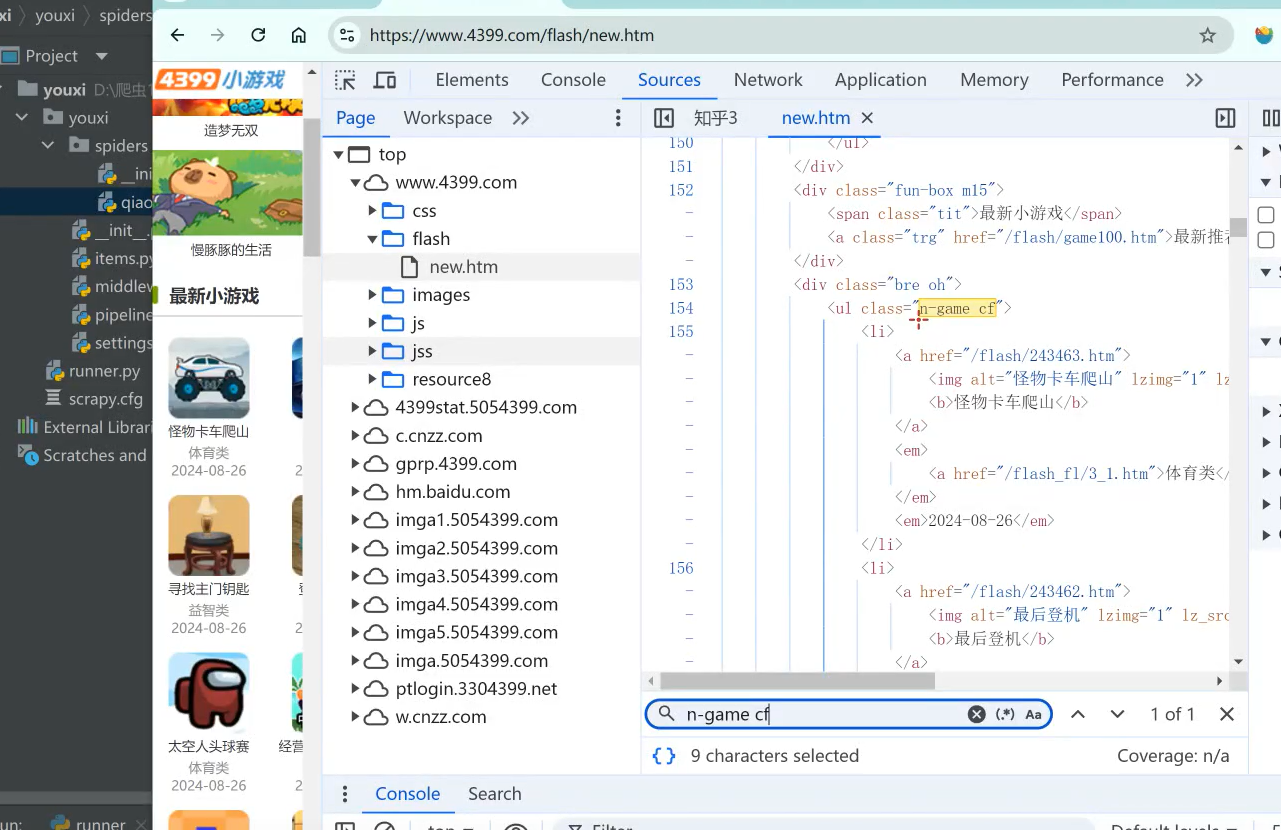
注意点:创建完之后,有如上提示,其中,example文件名称的要给自定义的,我给qiaofu_youxi 。example.com也就是域名,我给4399.com。如下图注意域名截图!
创建spider总结:
cd 文件夹 # 进入项目所在文件夹
scrapy genspider 爬虫文件名称 允许抓取的域名范围
三、认识创建的项目文件
(一)、cfg 和setting 配置文件
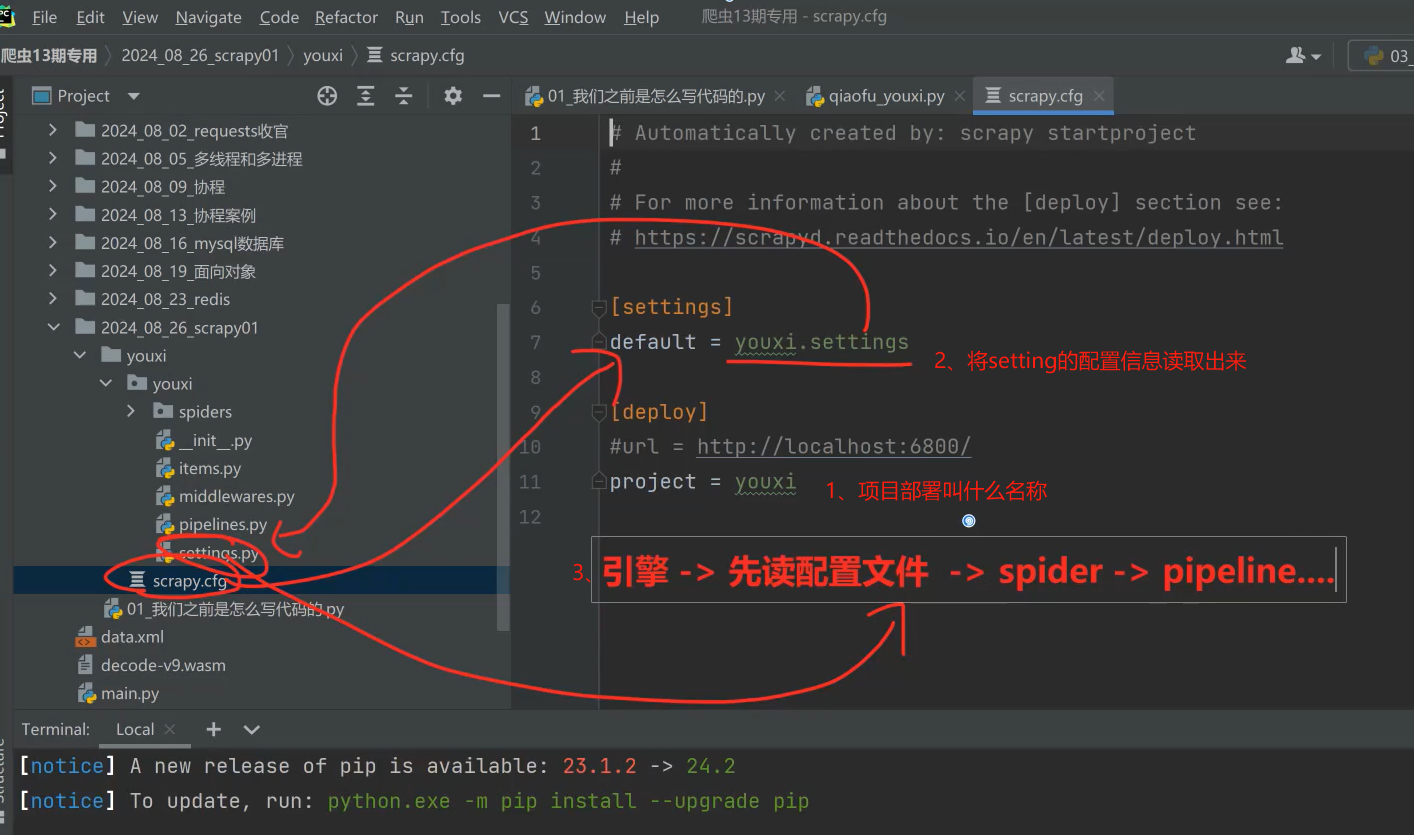
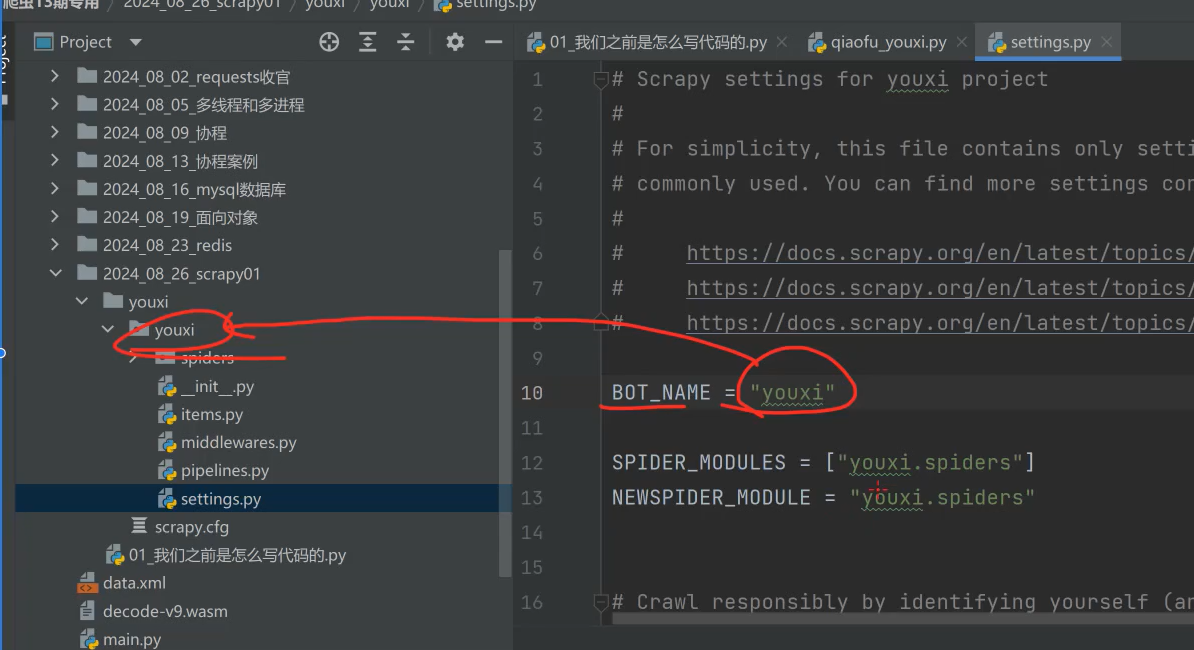
1、BOT_NAME 项目名
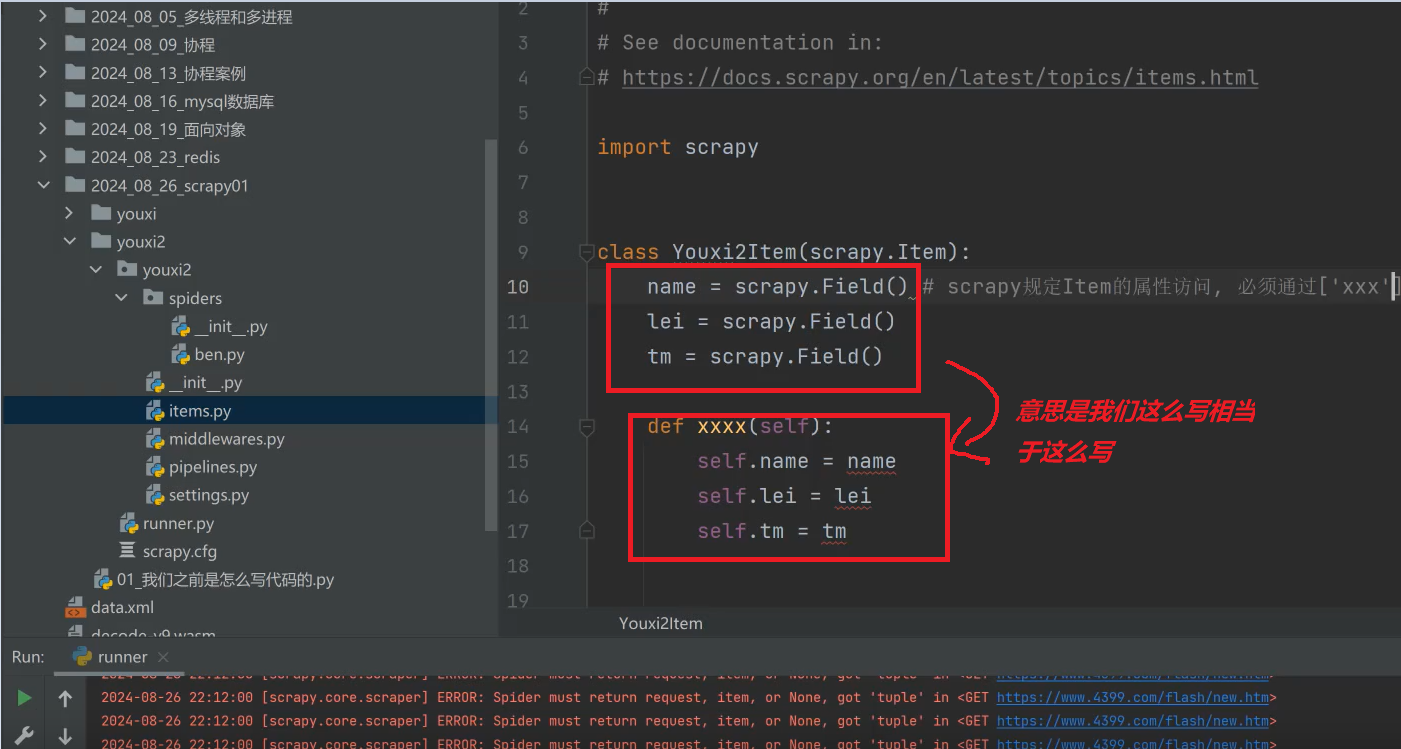
(二)item是定义数据的格式的:
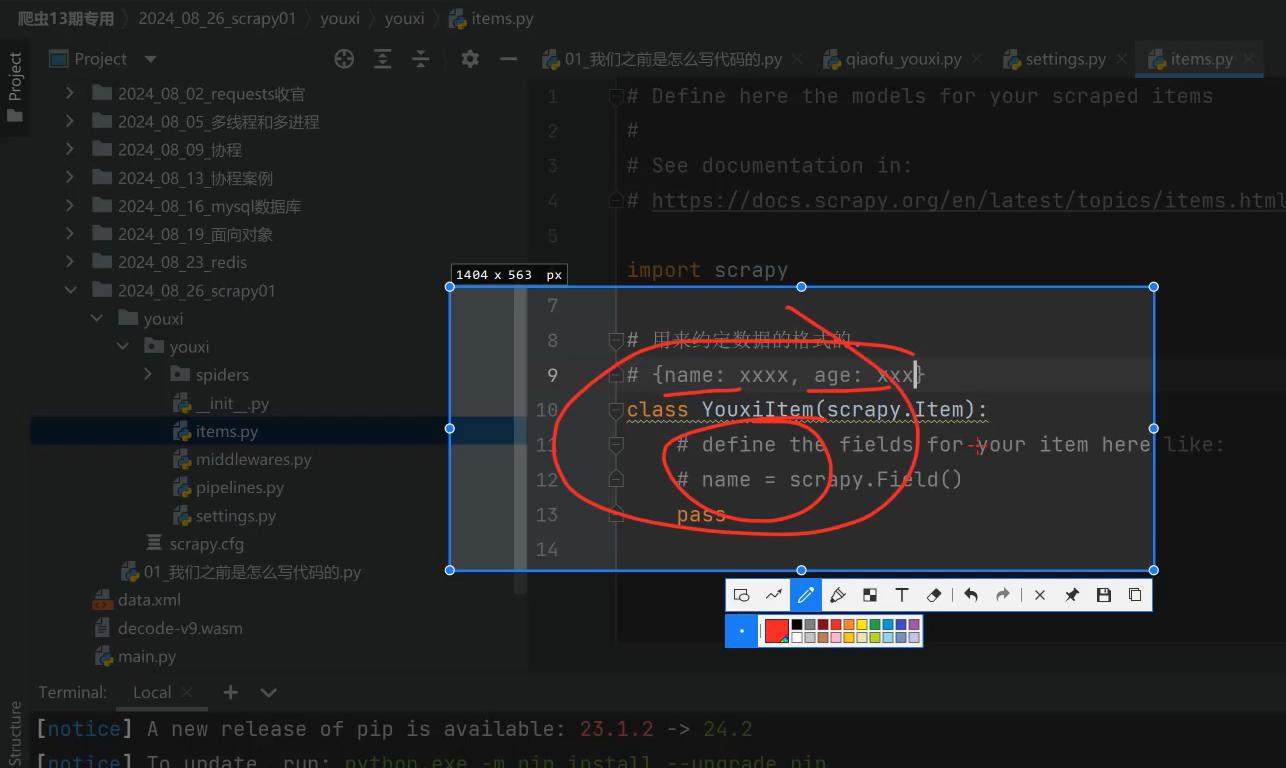
(三)、middlewares中间件
本章先不聊,大概是为了以后,应付反爬虫(比如js逆向),对应的方案设计的。下图是为了说明如果逆向cookies是根据一秒钟变化的,我们要怎么逆向解决的流程。
为什么需要?因为下载器的代码是动不了的!!!
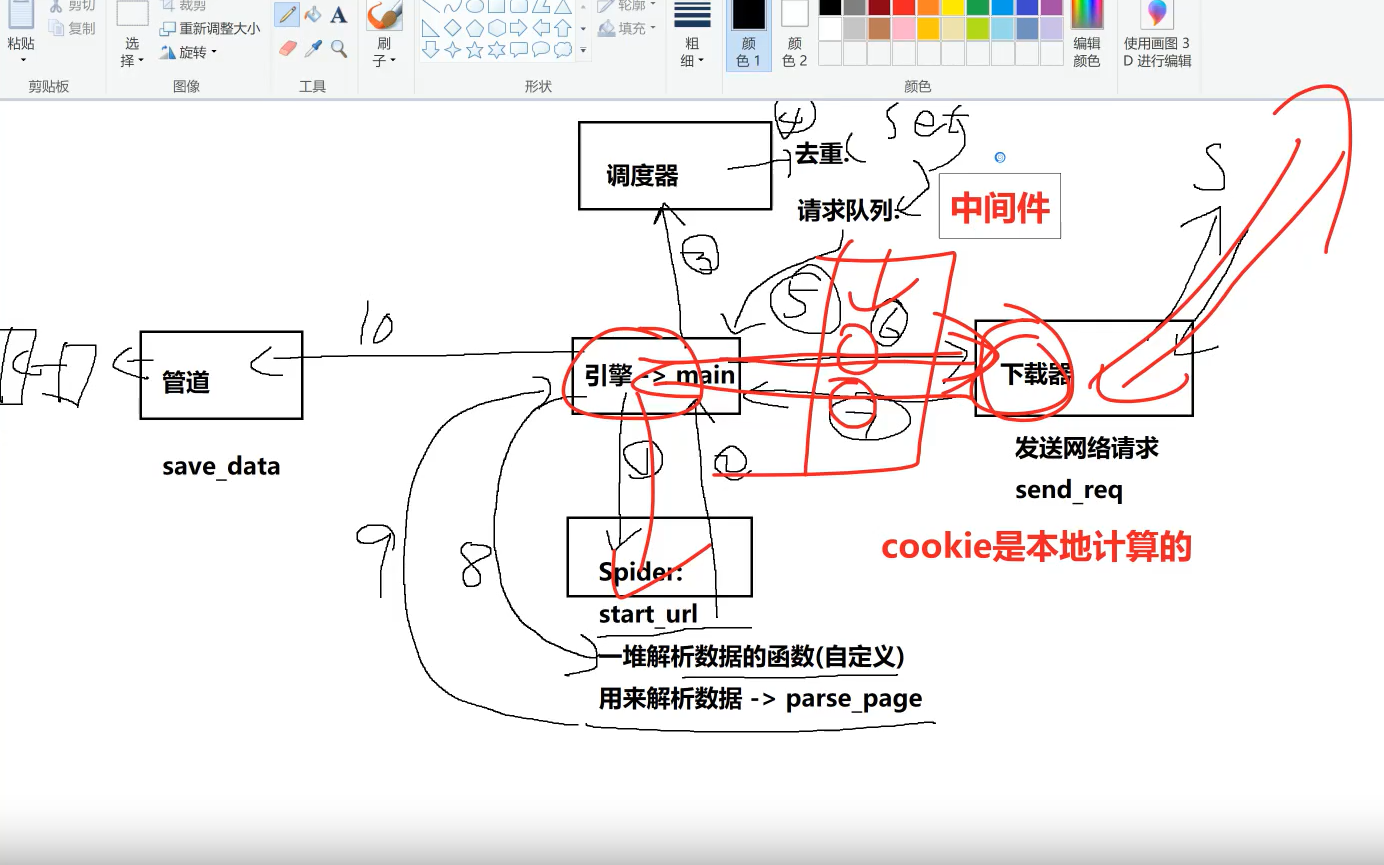
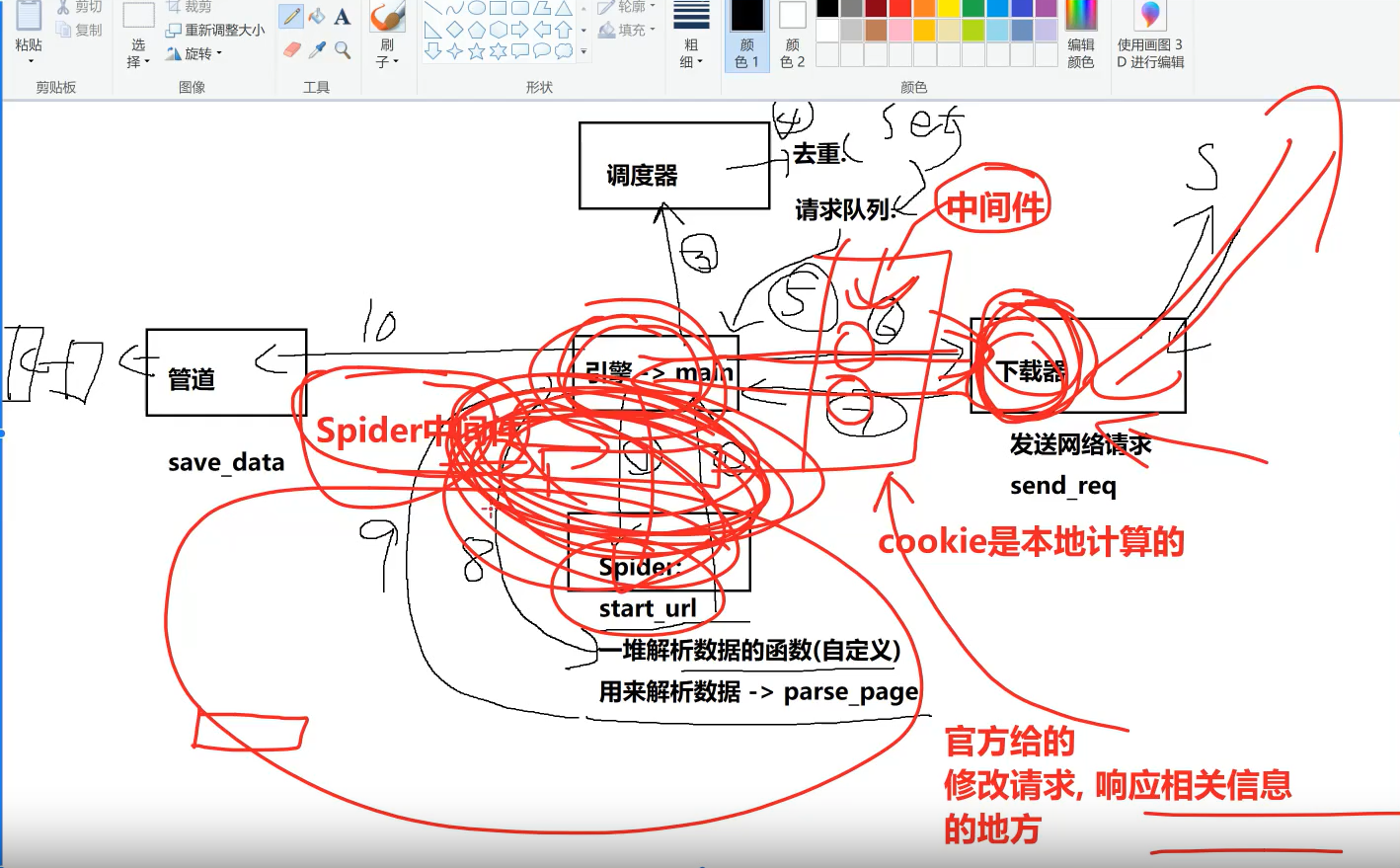
当然还有spider中间件,主要是解析数据会发生异常,所以我们要应付到时候解析数据的遗留的问题
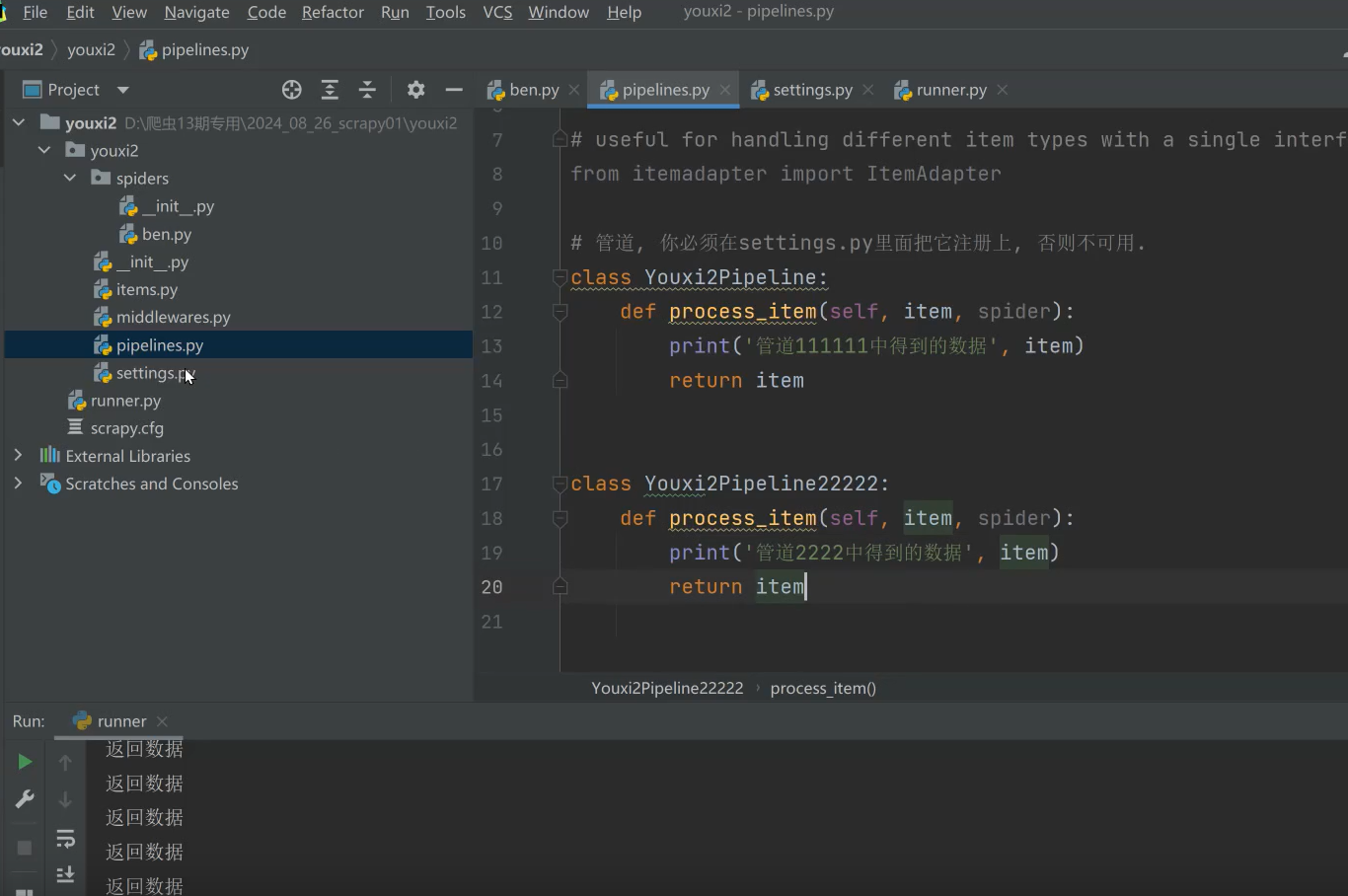
pipelines管道流
一、用来保存数据的
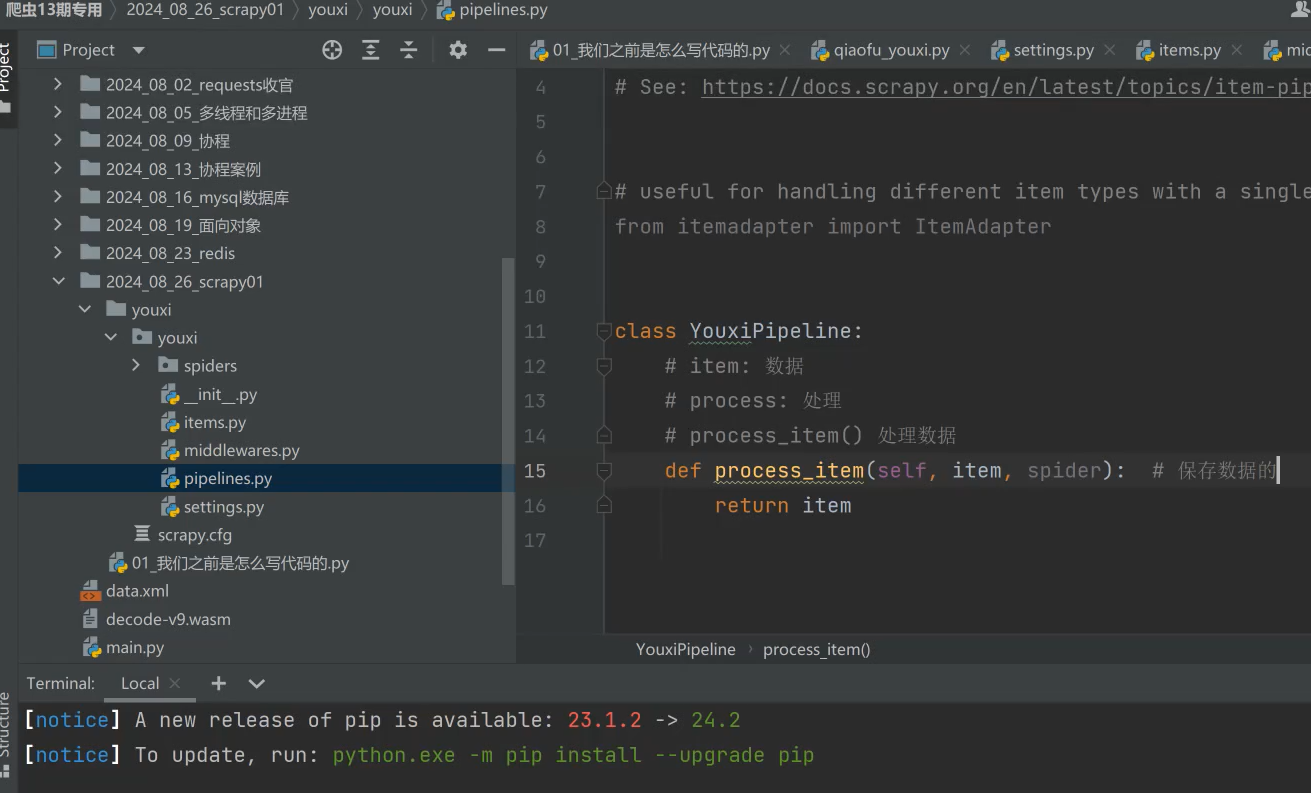
第一、我们可以多写几个类,YouxiPipeline比如我可以保存到csv,redis,mysql里面去
第二、但是每写一个,要记得去配置文件注册
第三、管道可以有多个
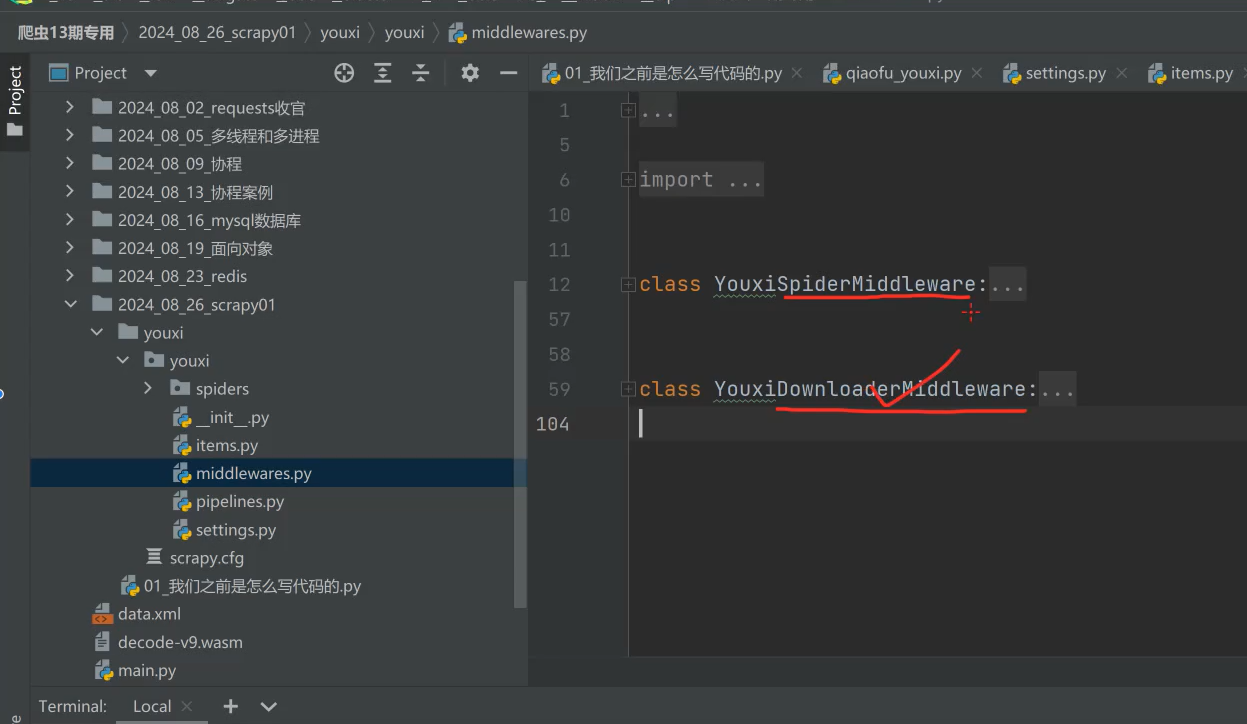
(三)、spider文件
主要用来过滤域名,解析数据
爬取的一个网站里面,可能有多个域名,图片为了举例子
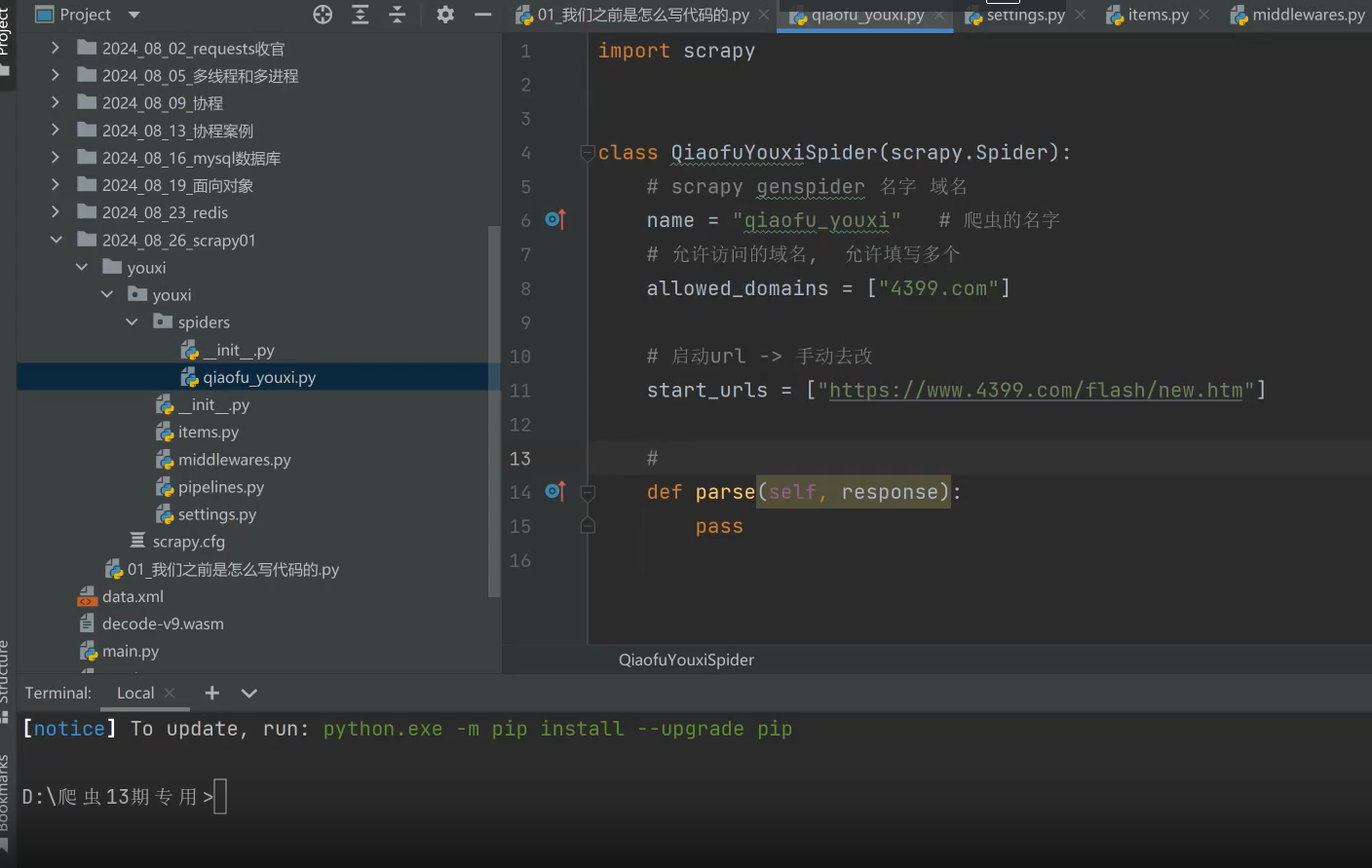
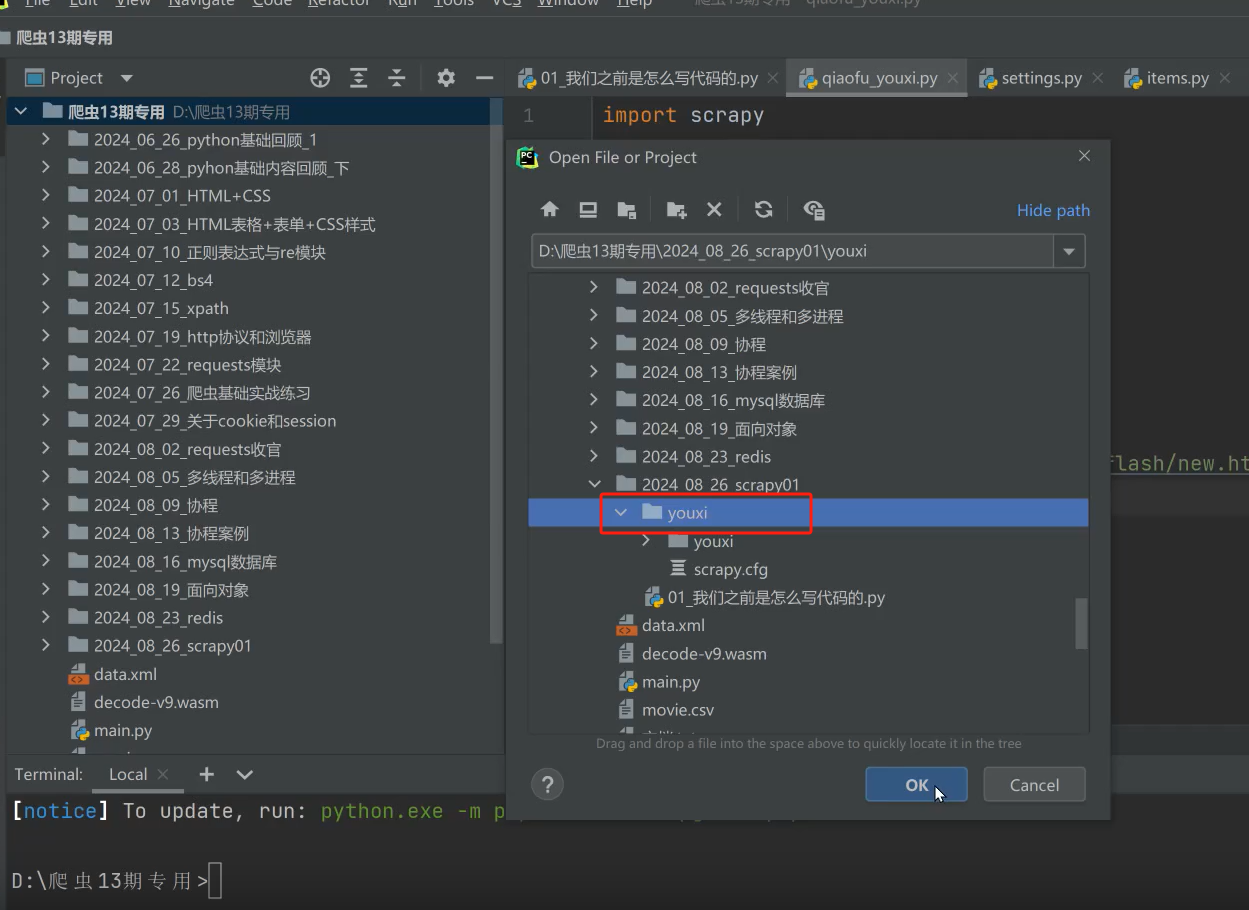
(四)、进入项目根目录
最后我们要进入项目目录去open打开才行,左上角菜单open project重新打开
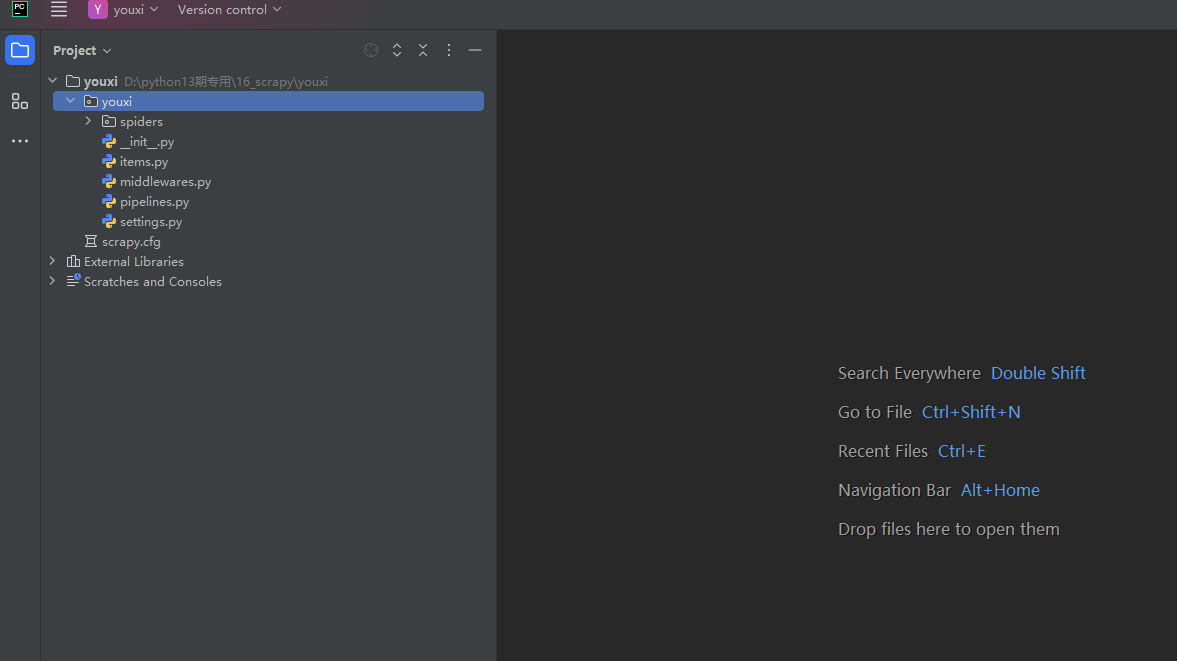
注意点:这里的代码,from youxi.items import YouxiItem并不会报错。
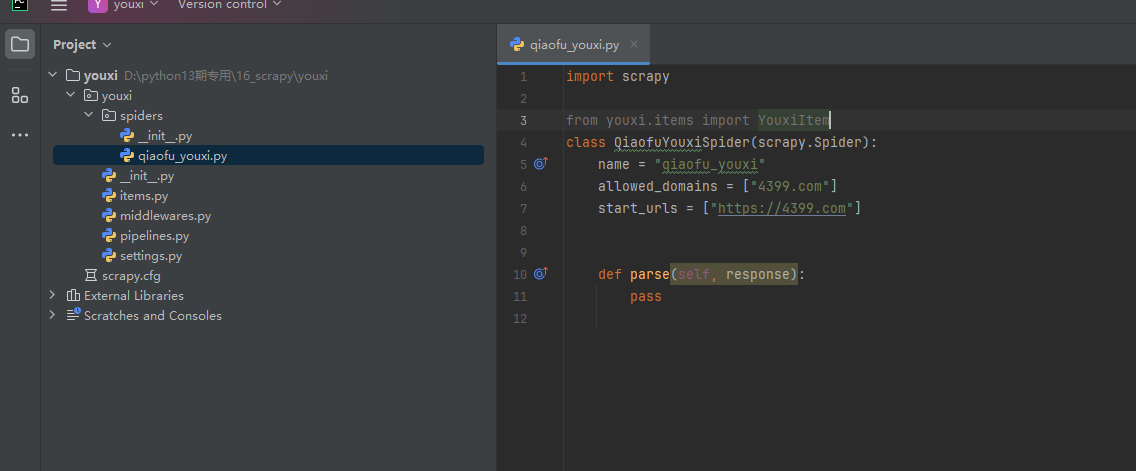
注意点1:如果我们不进入目录打开,这里就会报错,注意这个报错并不是真正的错误,而是pycharm误报而已。
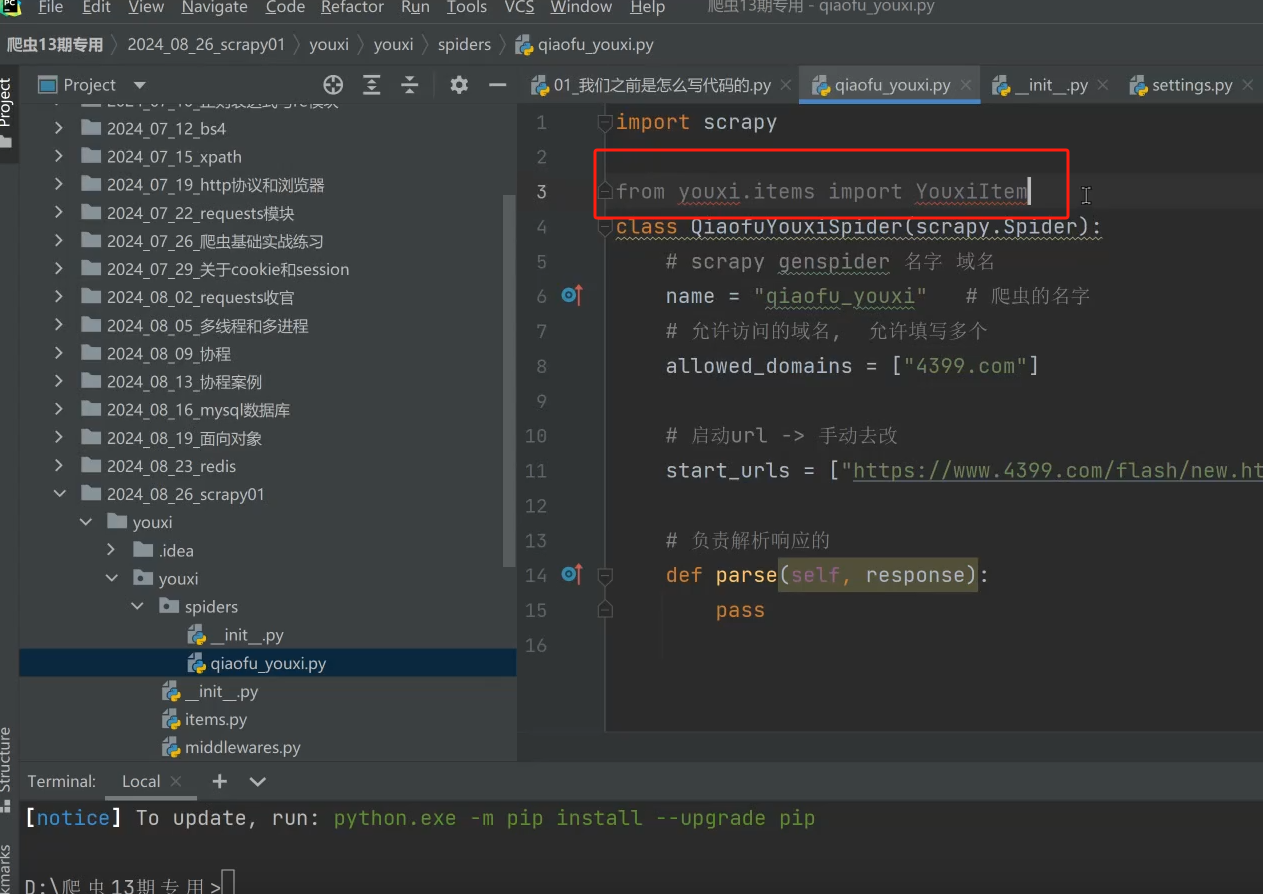
四、项目启动
方式一、命令行
命令: sracpy crawl 项目名
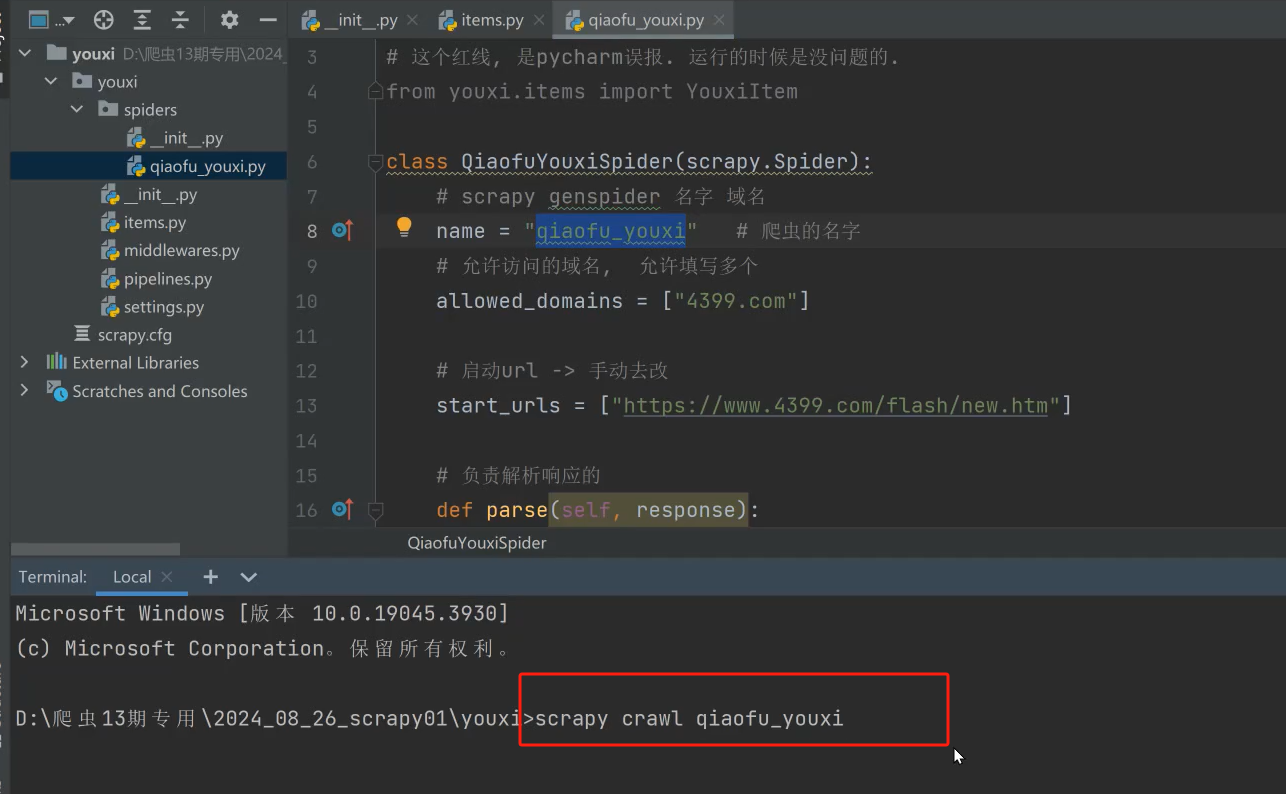
方式二、创建run模板
点run在控制台输出,而不是cmd命令行窗口输出。这个下面教怎么创建这个run模板
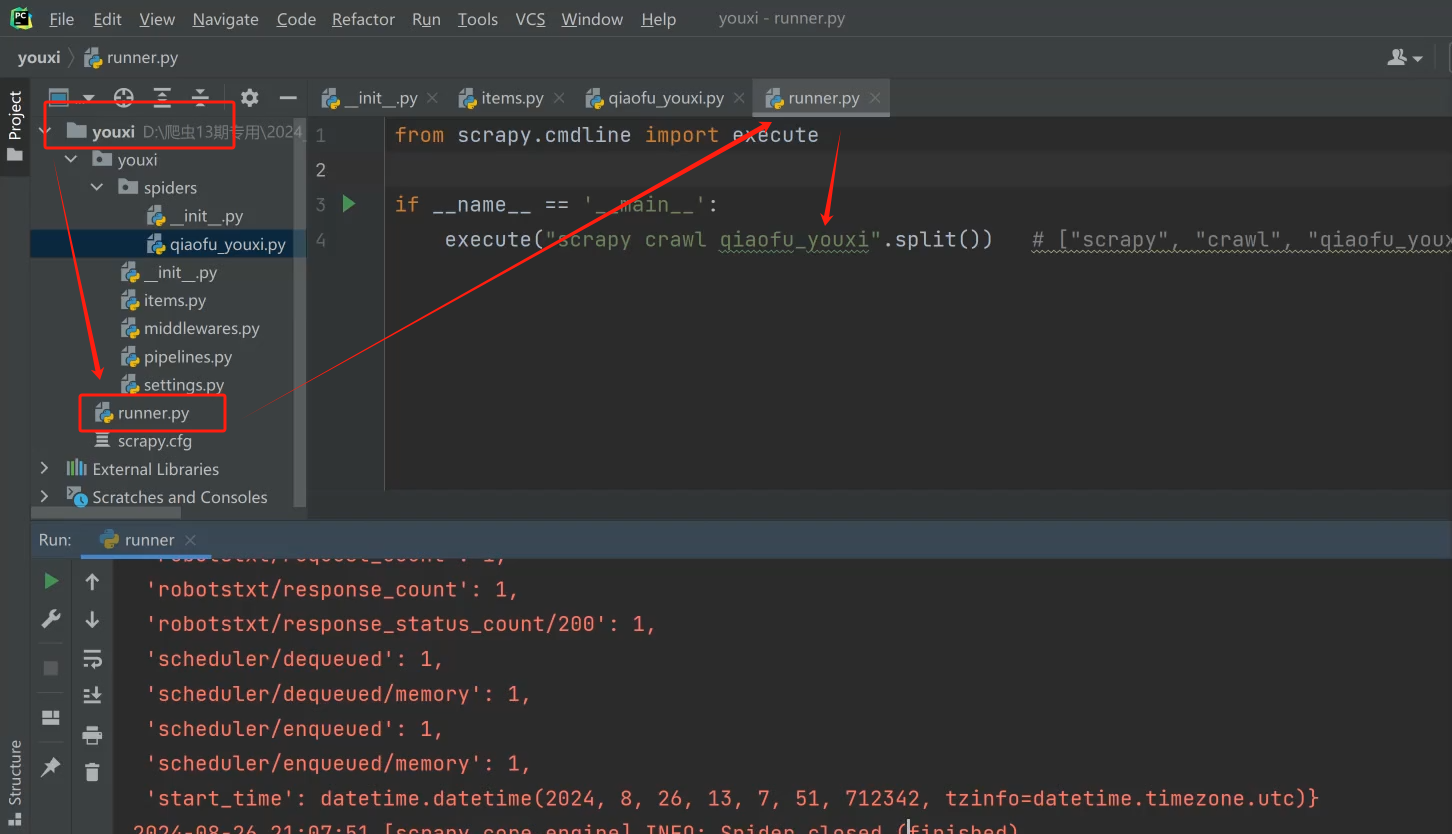
想要下次自动生成run代码,可以这样操作:
步骤:
第一、ctrl进入这个crapy的包进入源码,然后溯源找到目录template
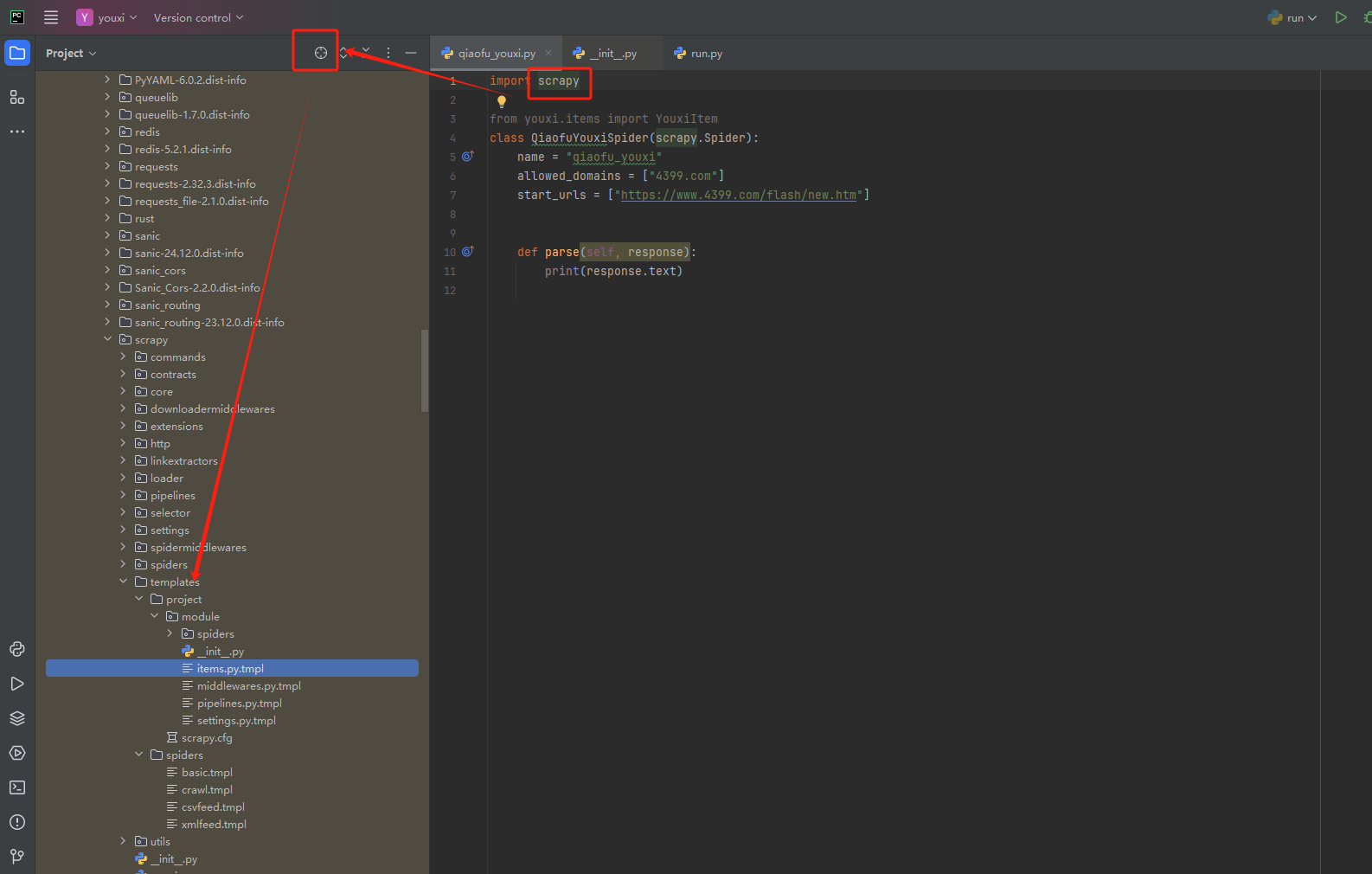
然后随便复制module文件夹下的文件(我这里复制items.py.tmpl),复制后将如下模版替换进去:
from scrapy.cmdline import execute
if __name__ == '__main__':
execute("scrapy crawl qiaofu_youxi".split())
注意复制到project的目录下:
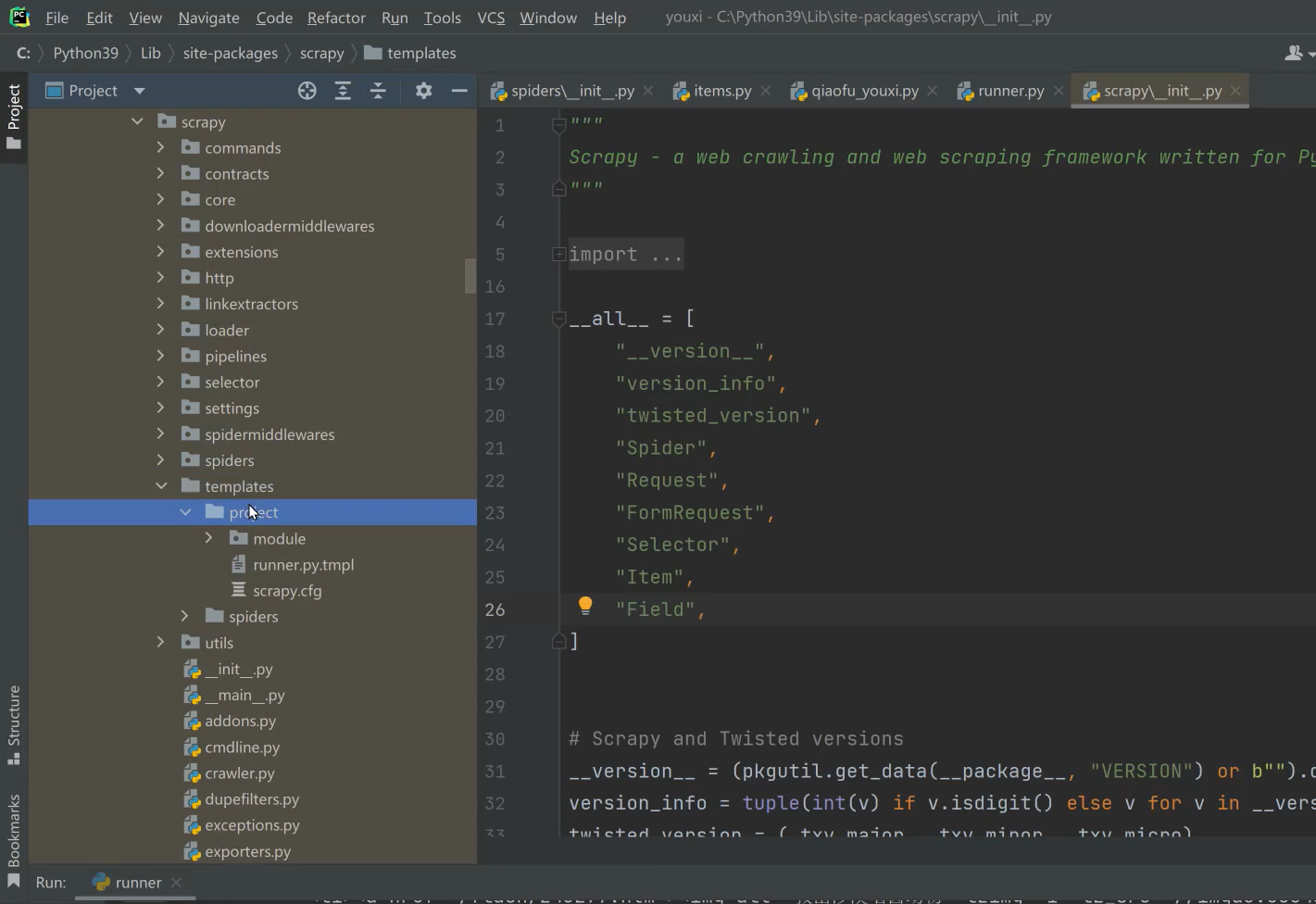
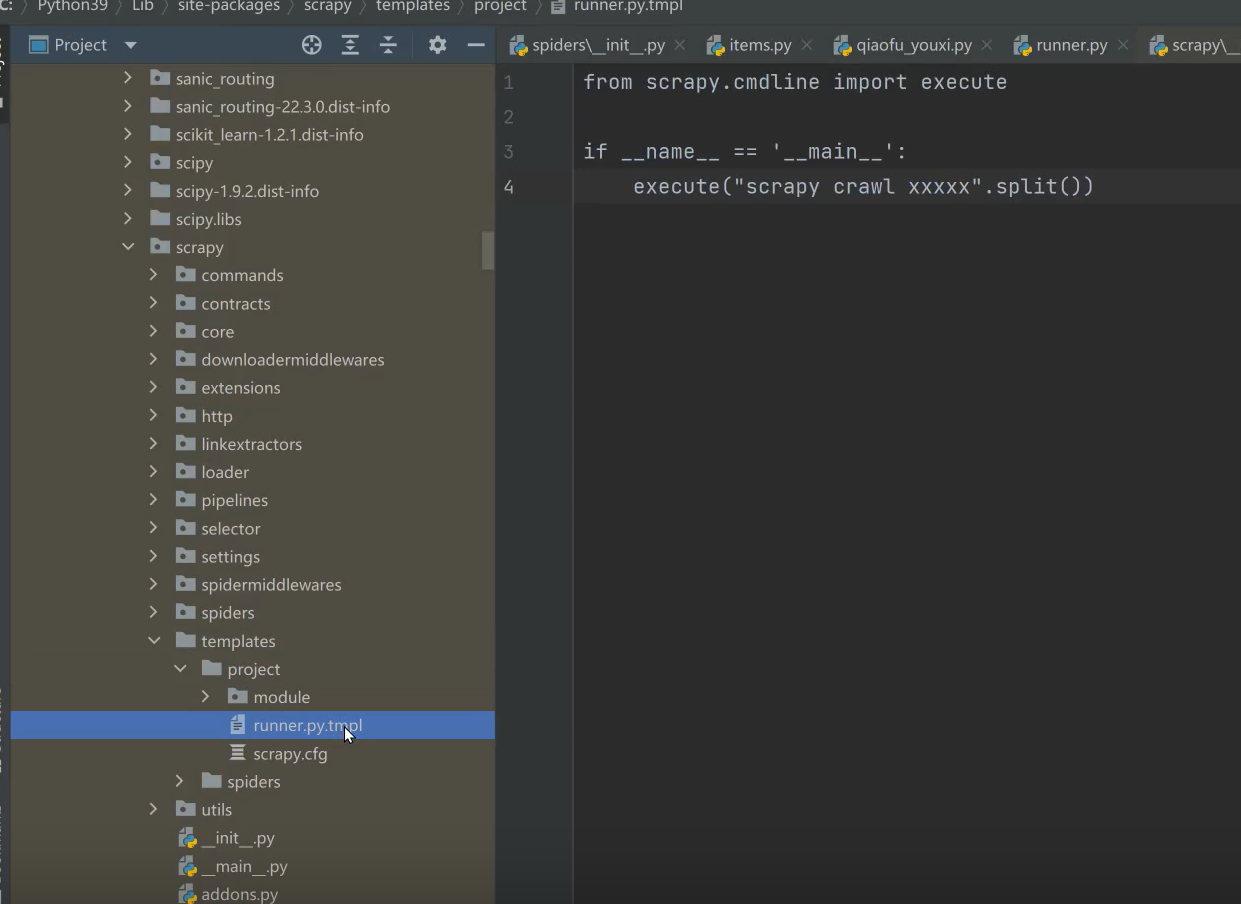
备注:当然你可以直接复制成py文件,因为tmpl文件的话,每次生成都会提示你,scrapy crawl xxxxx…的xxxx 要改回spider名称
五、修改日志信息
只保留warning以上的日志,不保留
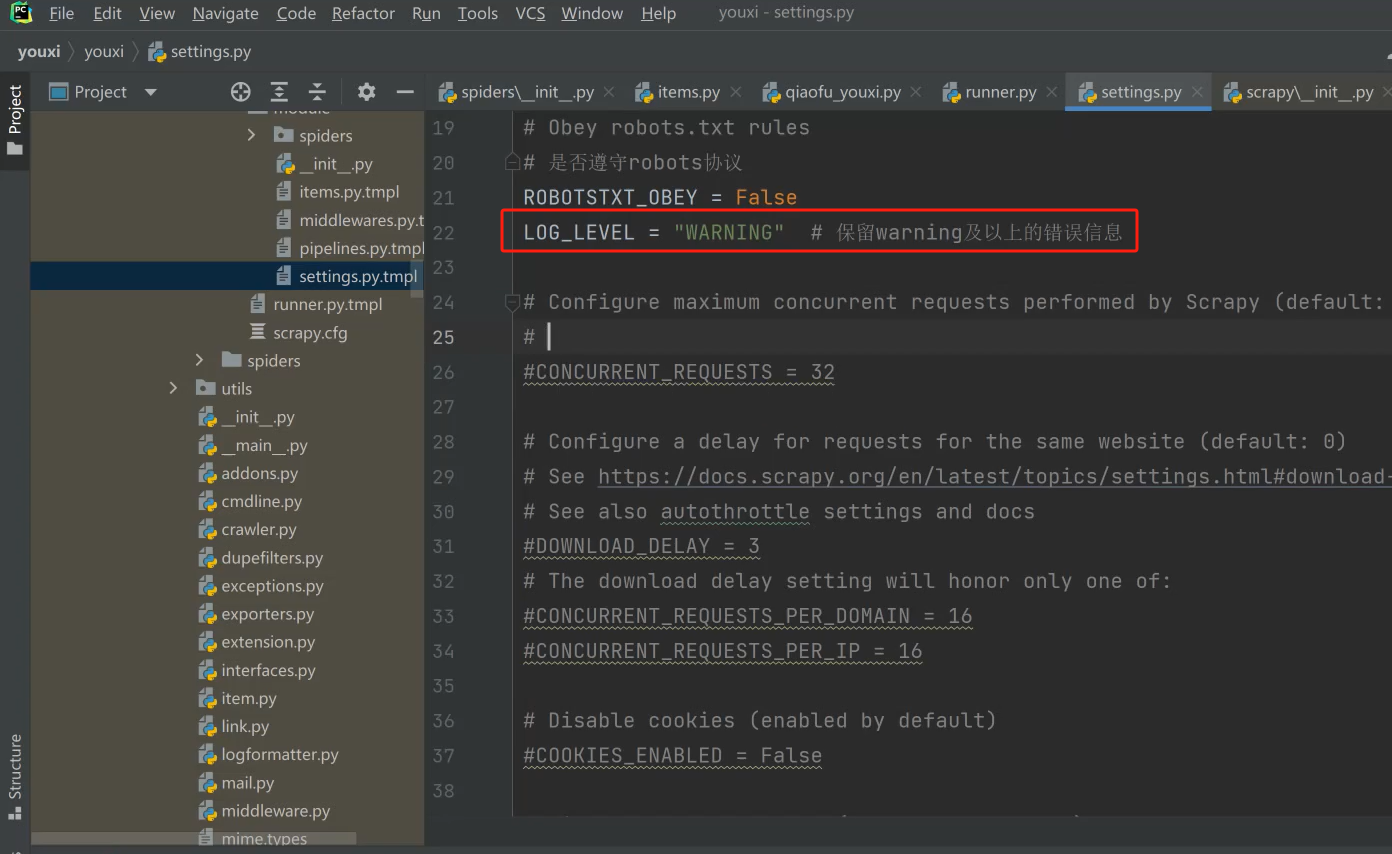
六、spider解析提取数据
我们再也不用这样导入,from lxml import etree 。然后etree.xpath()了,只需要response.xpath()即可
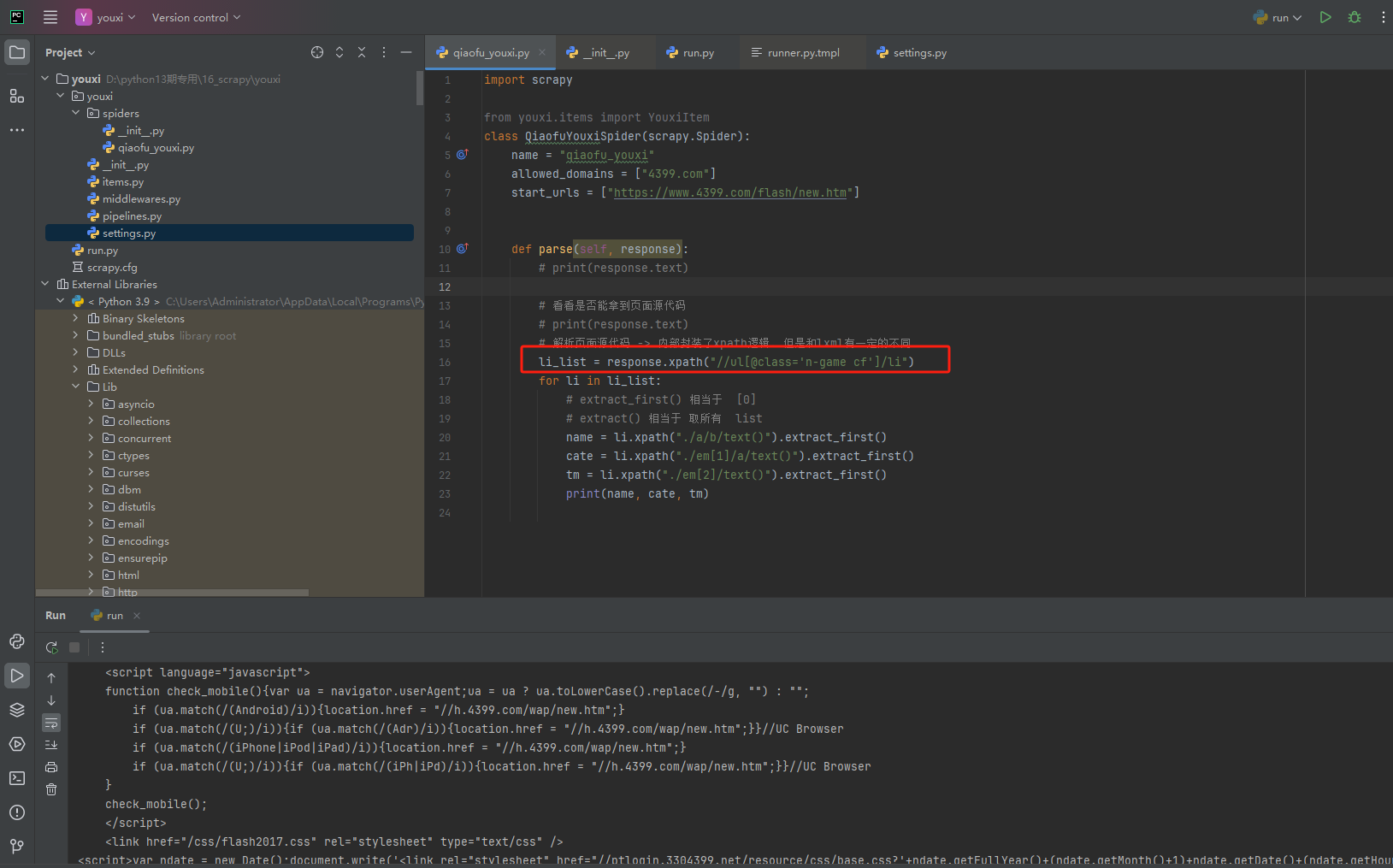
“extract_first”就是取列表中的第一个意思,和list[0]意思一样的
解析过程如下:
我们这里不能用return,因为会自动结束for循环。而且return给管道的话,管道又得for循环一条条拿取。如果result很大十几万条的话,效率就会降低。我们希望的是一条条json数据返回。故用yield生成器
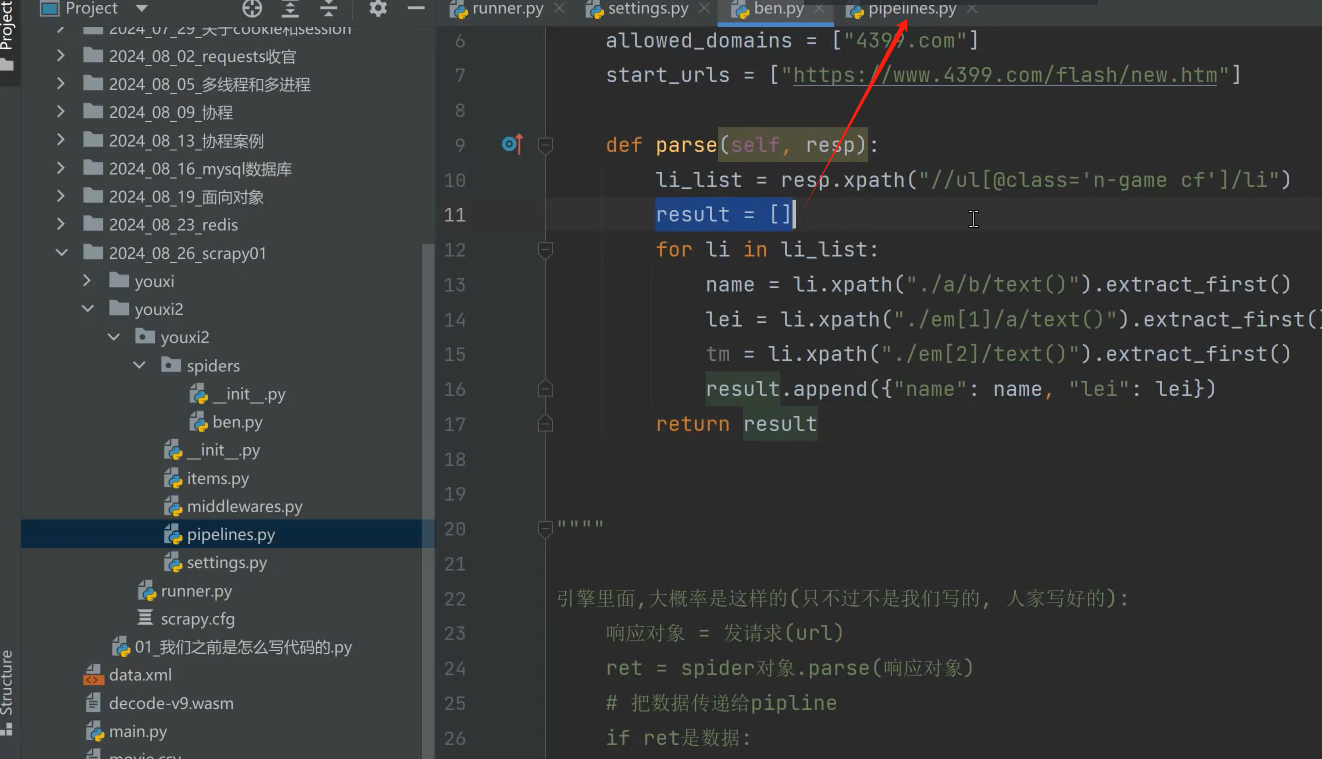
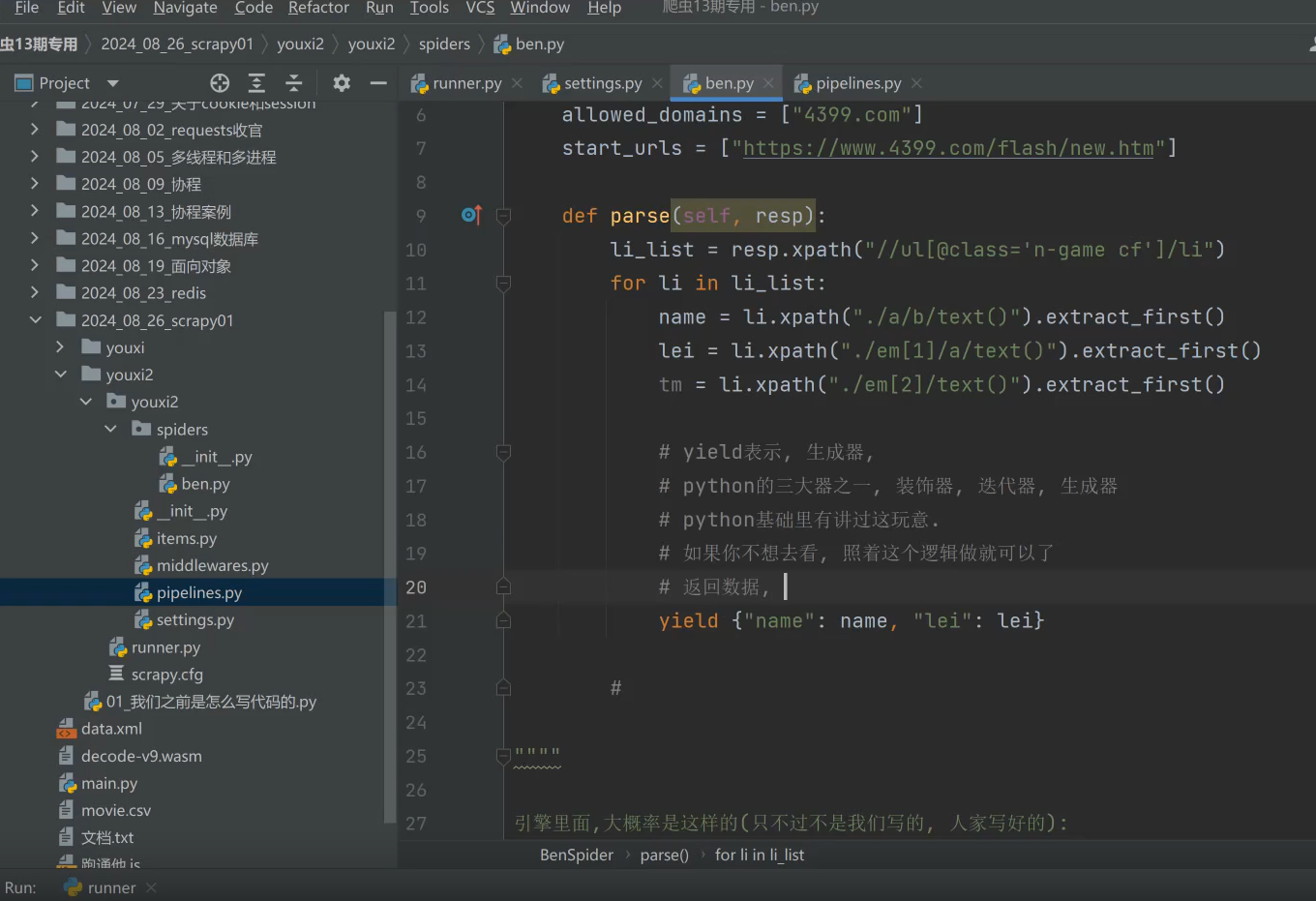
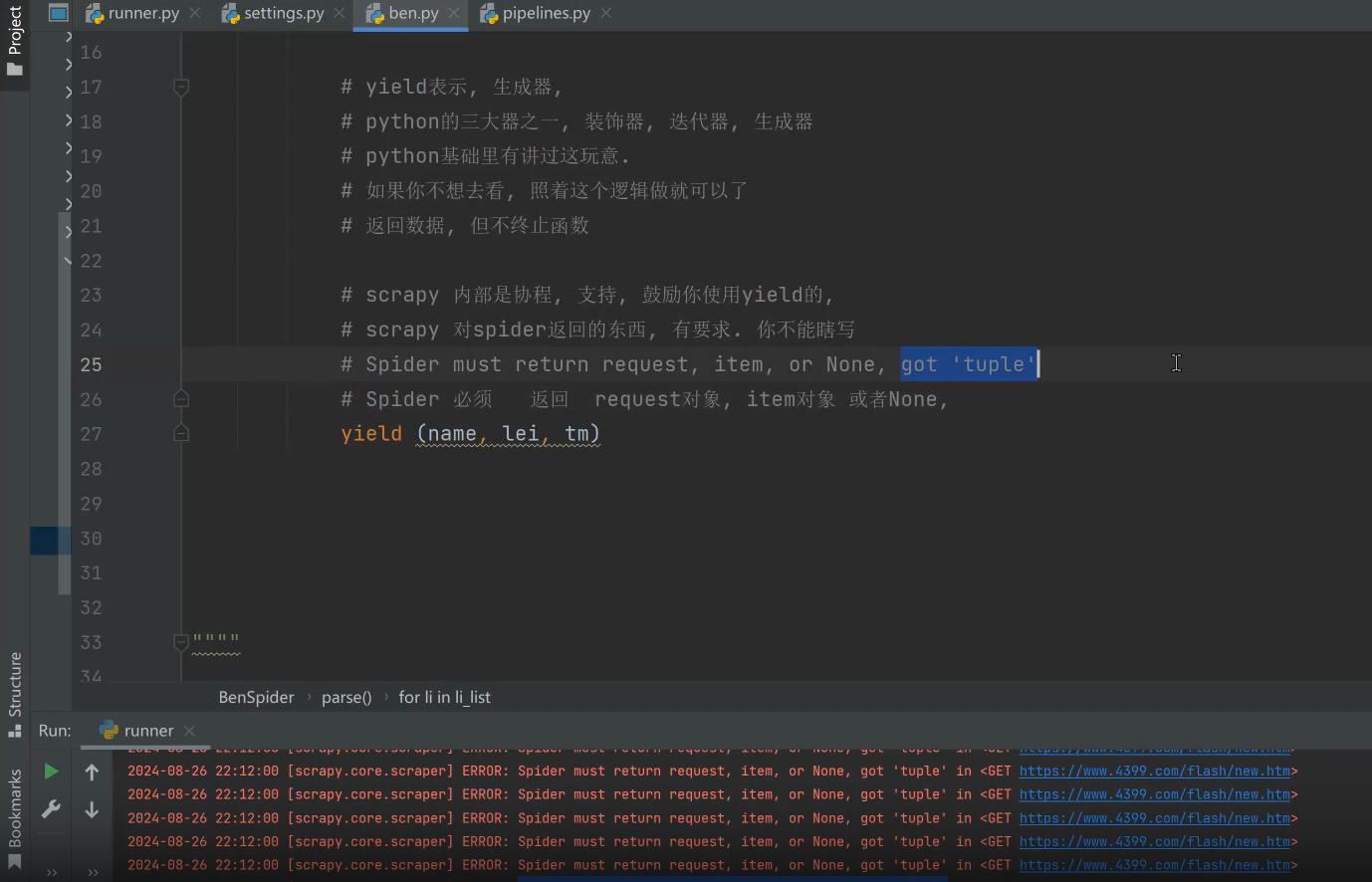
注意点:spider返回对象必须是request, item, None。也可以是字典(json)
七、item数据格式
那么item可以这里定义:
回到parse,就是返回数据有两种写法,建议如下这样写。
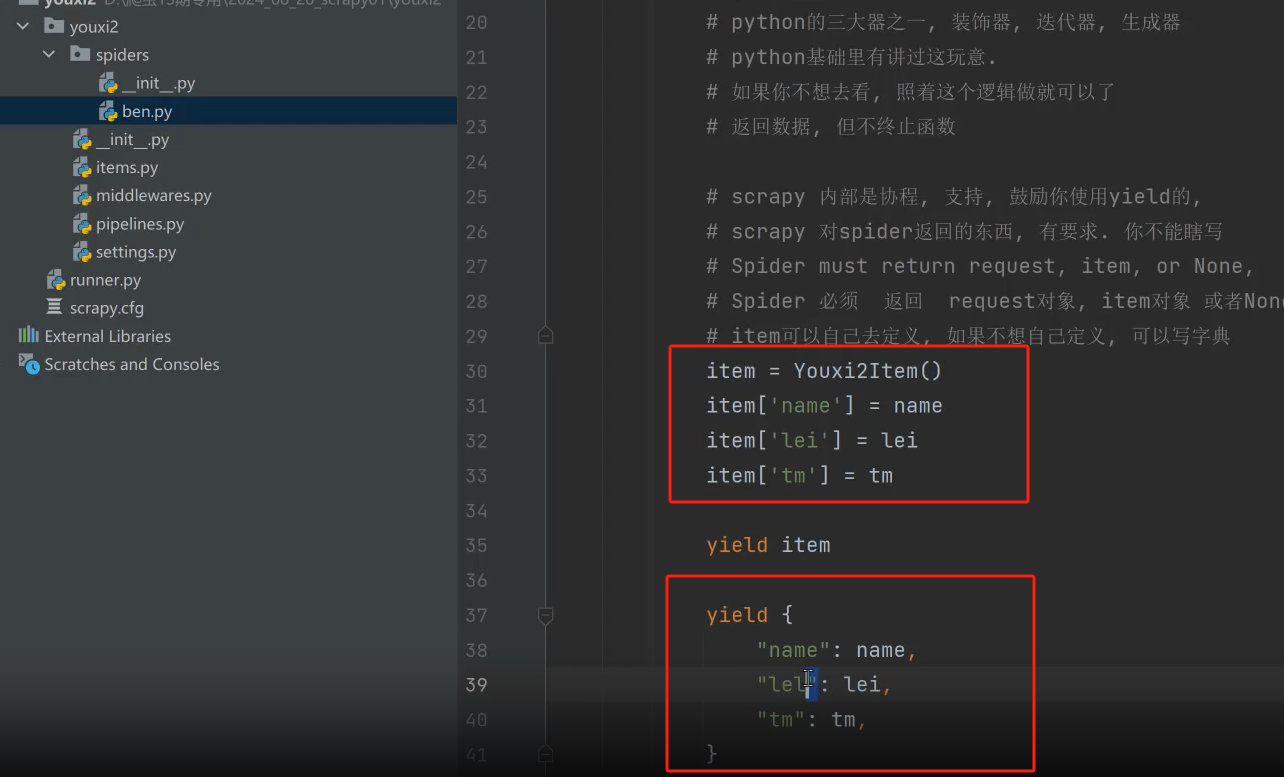
八、pipeline管道流保存数据
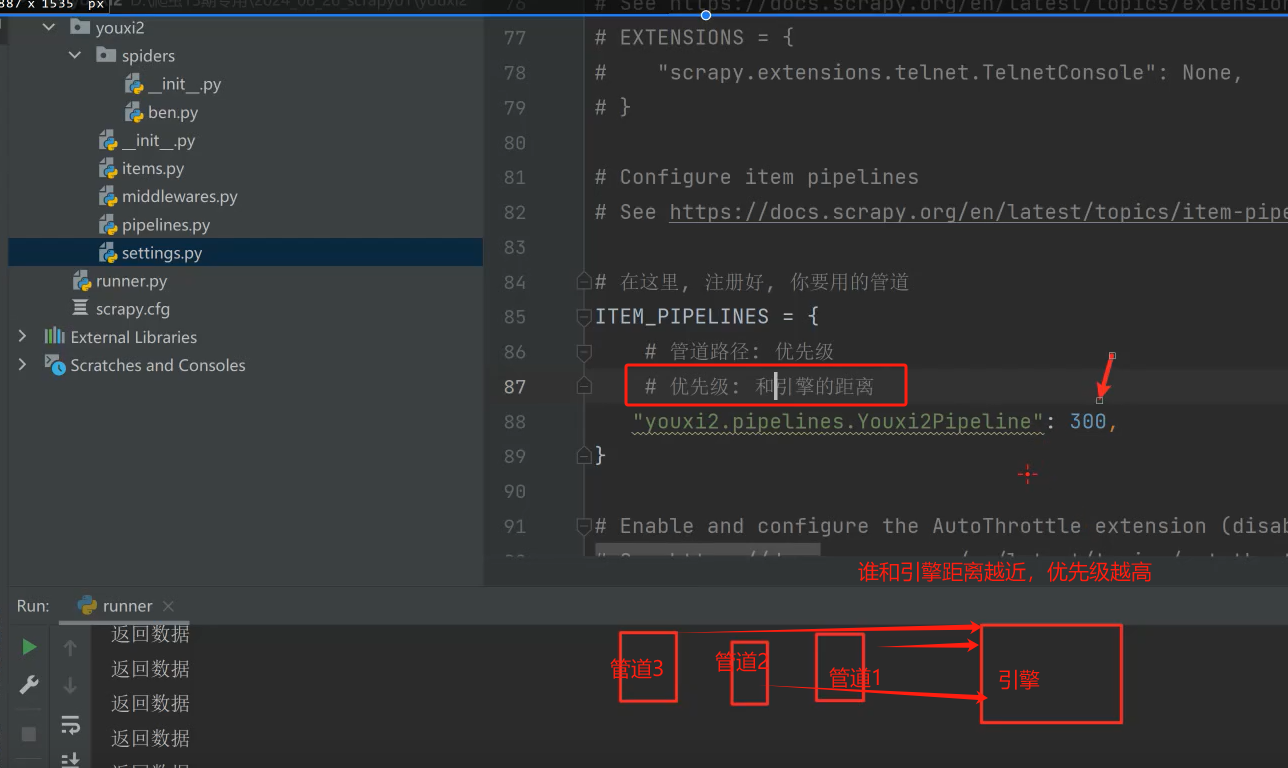
setting配置管道优先级
注意点:(1)要在setting中,打开注释,注册pipeline才能使用,才能在控制台输出数据。
(2)、图中只有一个pipelines,可以多添加几个,300是指优先级,越小优先级越高(理解为距离引擎的距离)
运行结果:
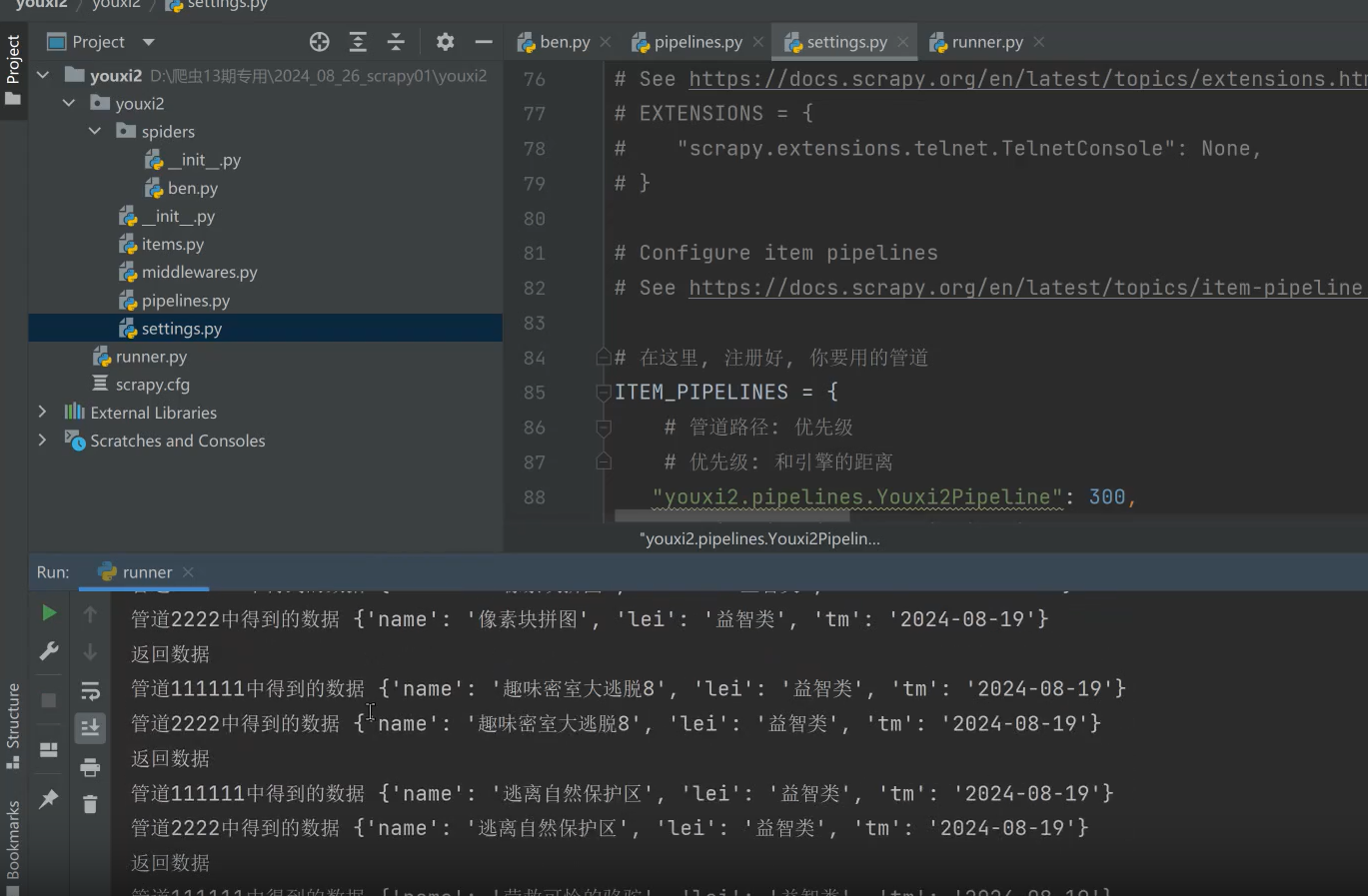
注意点:为什么我们不在process_item里面写这个open的操作。
分析:如果是a追加模式的话,要确保每次都是新的数据。w的话,每次都会覆盖,都不合理。
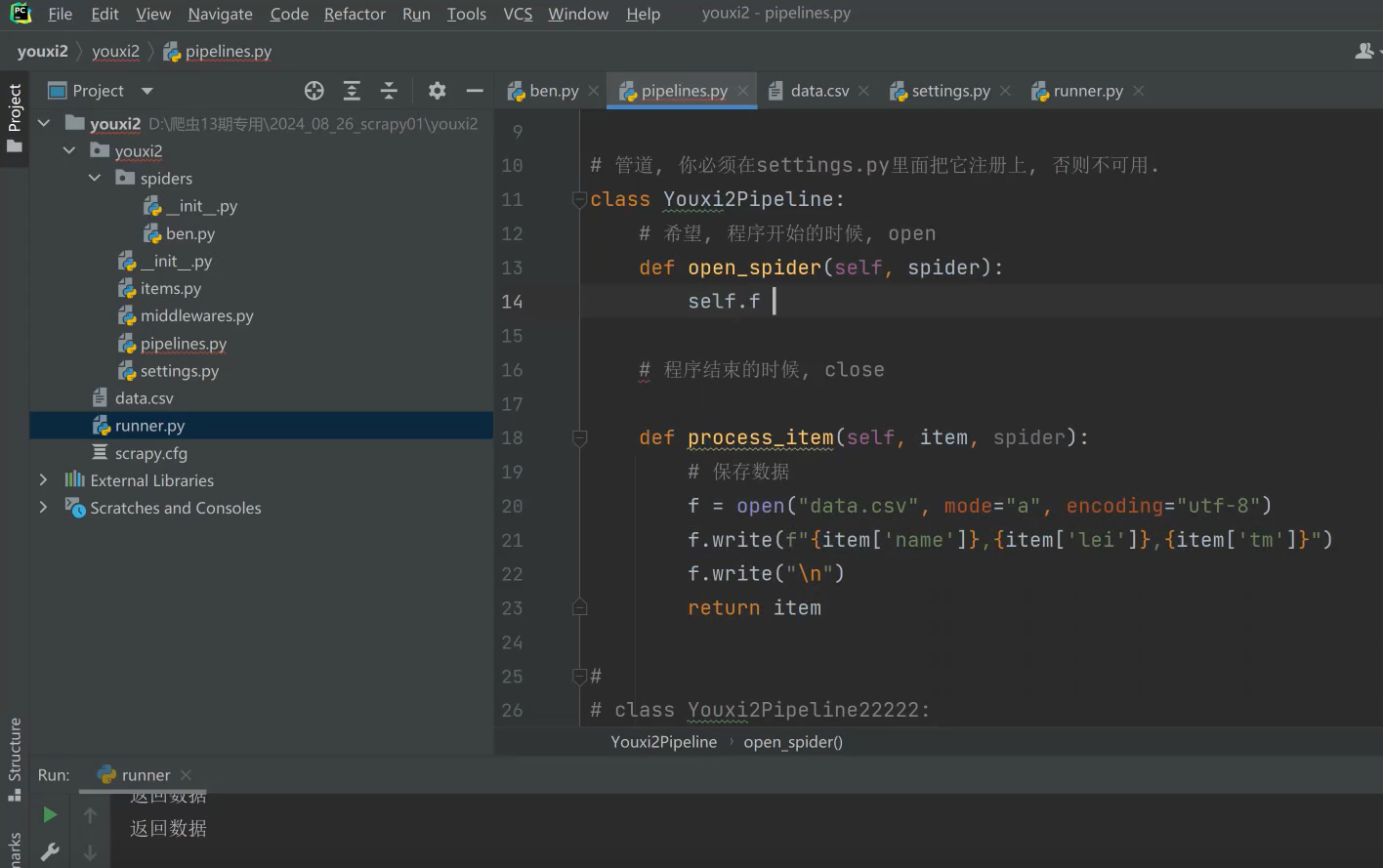
代码调整
通过爬虫官网,我们看到如下这么写:
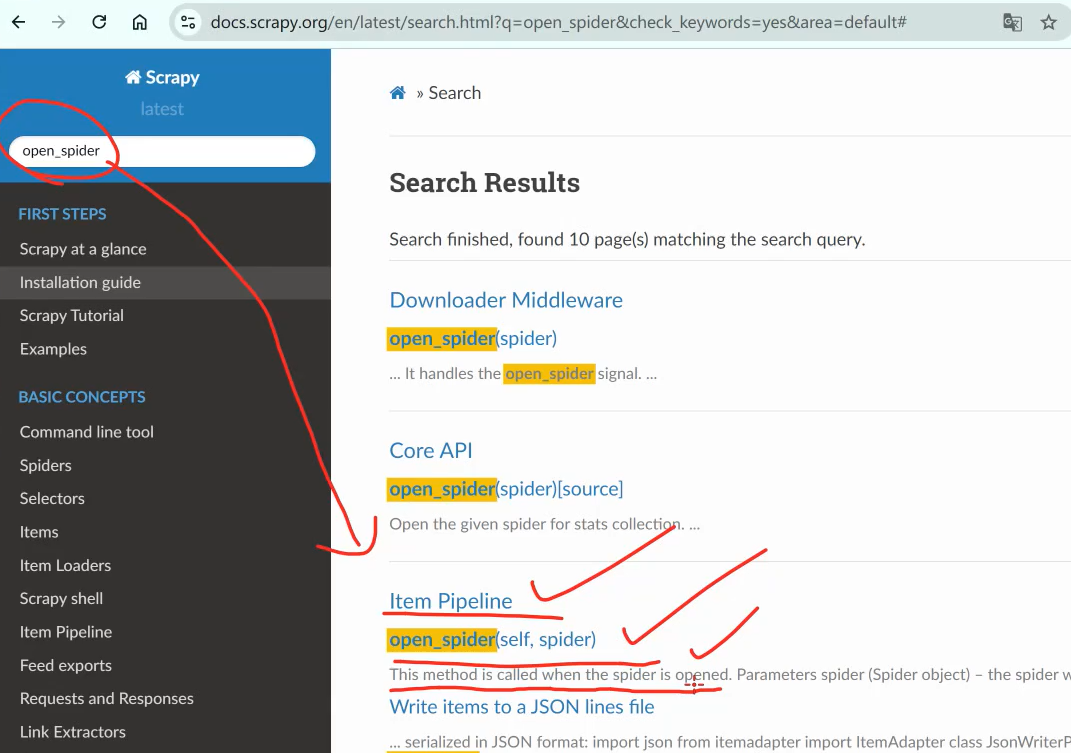
修改后如下:
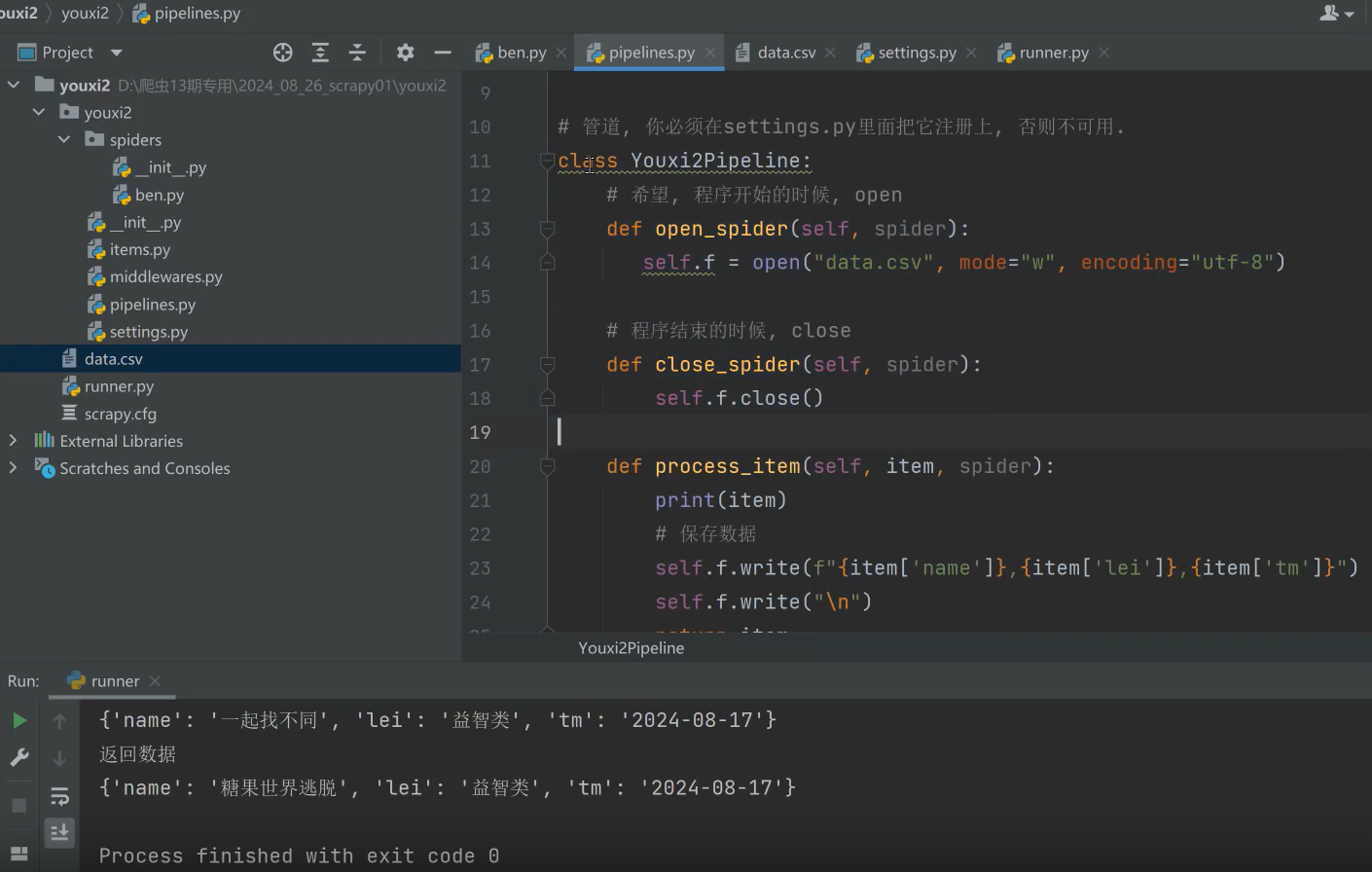
代码如下:
# 管道, 你必须在settings.py里面把它注册上, 否则不可用.
class Youxi2Pipeline:
# 希望, 程序开始的时候, open
def open_spider(self, spider):
self.f = open("data.csv", mode="w", encoding="utf-8")
# 程序结束的时候, close
def close_spider(self, spider):
self.f.close()
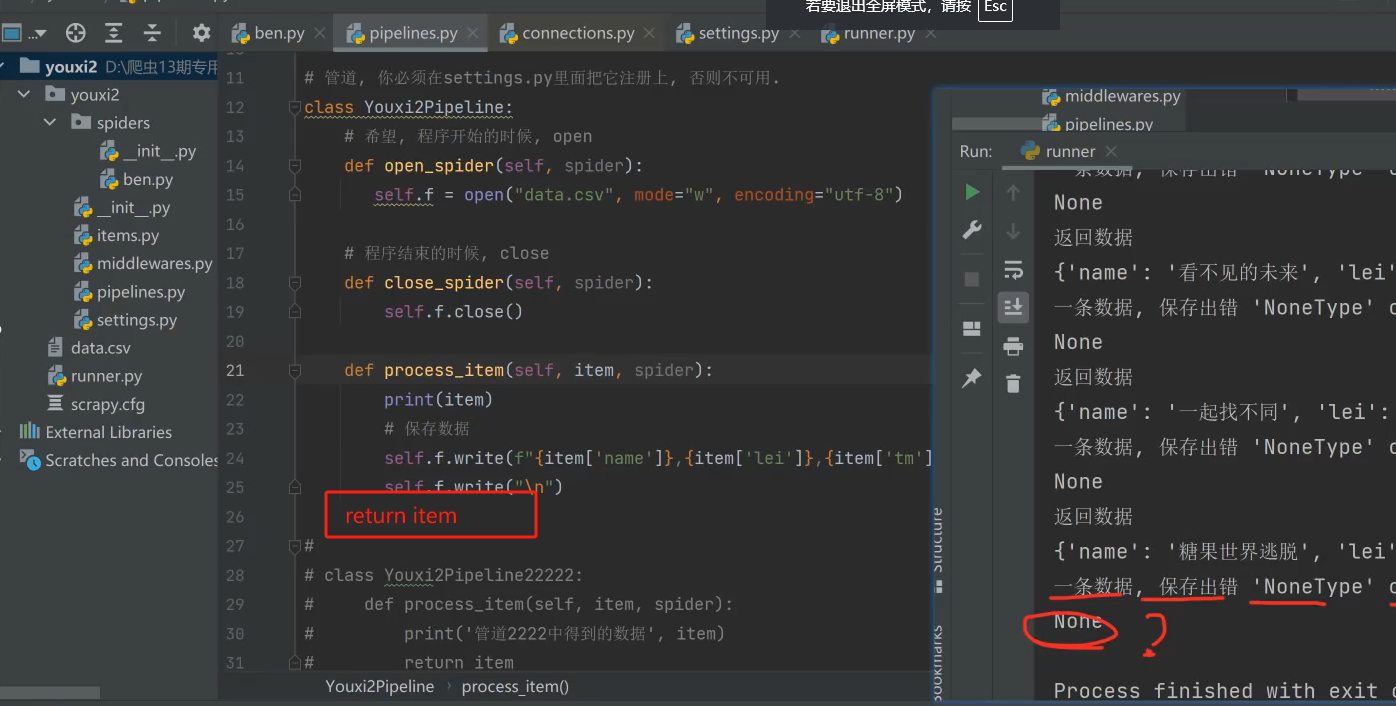
def process_item(self, item, spider):
print(item)
# 保存数据
self.f.write(f"{item['name']},{item['lei']},{item['tm']}")
self.f.write("\n")
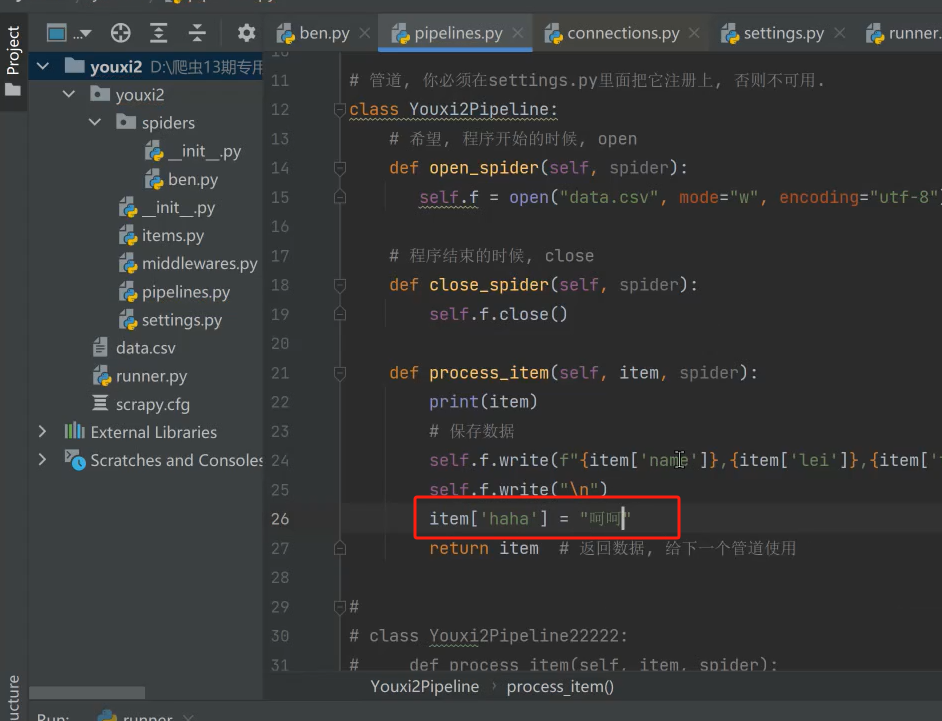
item['haha'] = "呵呵"
return item # 返回数据, 给下一个管道使用
保存到MySql
class Youxi2Pipeline_toMySQL:
# 希望, 程序开始的时候, open
def open_spider(self, spider):
self.conn = pymysql.connect(
host="localhost",
port=3306,
user="root",
password="root", # ???
database="qiaofu_ceshi"
)
self.cursor = self.conn.cursor()
def close_spider(self, spider):
try:
self.cursor.close()
self.conn.close()
except Exception as e:
print("关闭连接出错, 没关系")
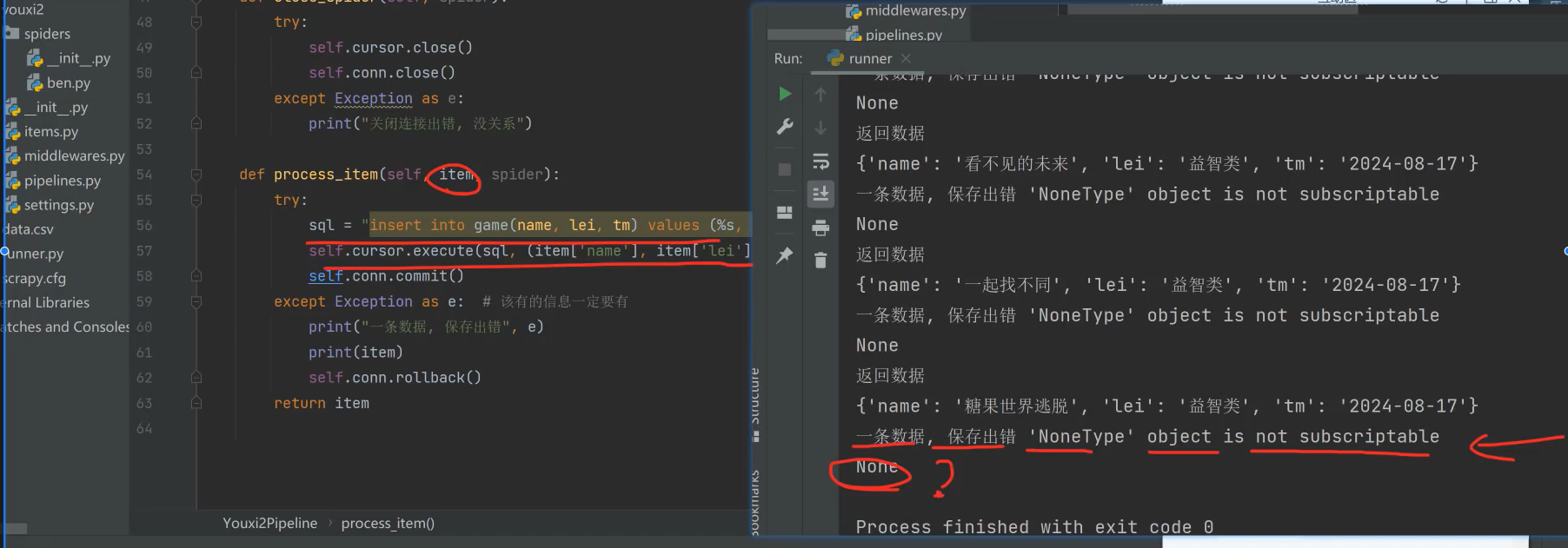
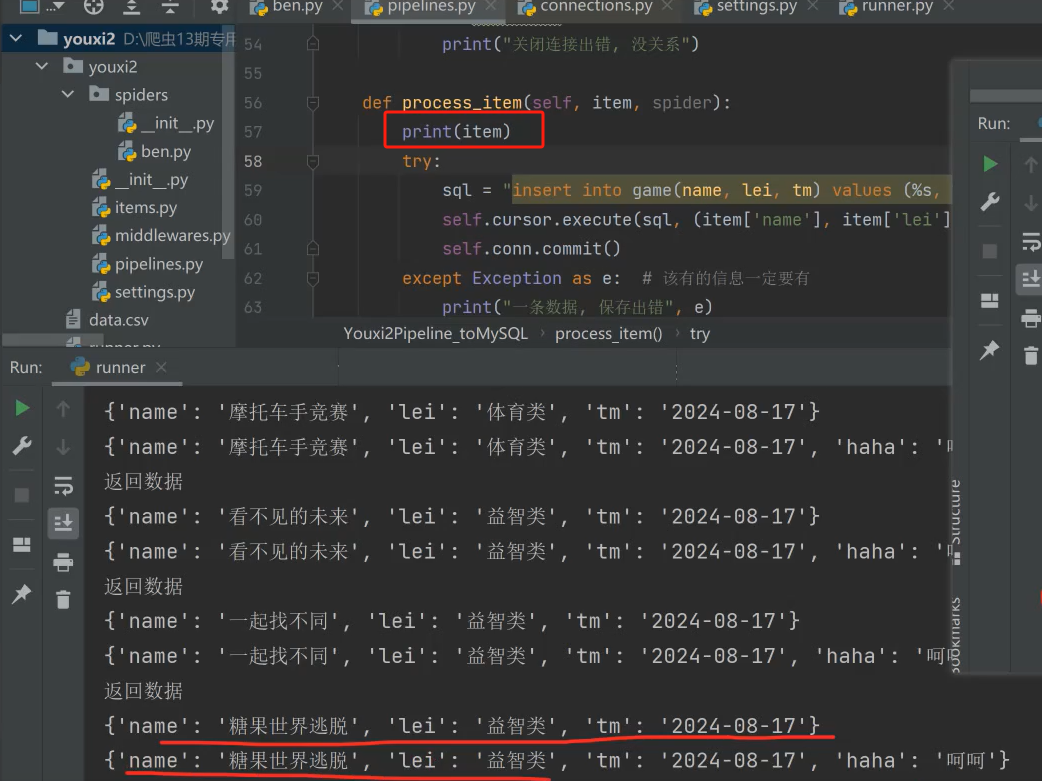
def process_item(self, item, spider):
print(item)
try:
sql = "insert into game(name, lei, tm) values (%s, %s, %s)"
self.cursor.execute(sql, (item['name'], item['lei'], item['tm']))
self.conn.commit()
except Exception as e: # 该有的信息一定要有
print("一条数据, 保存出错", e)
print(item)
self.conn.rollback()
return item
注意点:这里异常信息,该捕获的就捕获
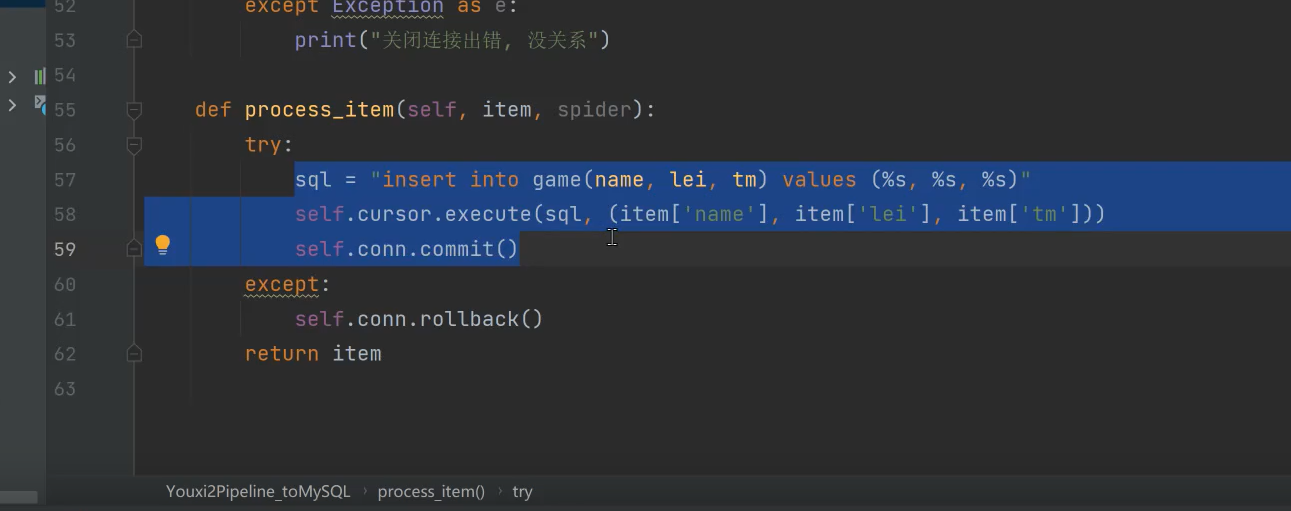
注意点:最后记得将这个方法在管道流注册才能保存!!
九、总结回顾scrapy流程
如果将上一个管道的return删除掉的话,如下:
你当然可以在上个管道加个代码
item[“haha”] = “呵呵”
第二个管道打印即可:
捕获的就捕获
[外链图片转存中…(img-mpiC1BIj-1743595432910)]
注意点:最后记得将这个方法在管道流注册才能保存!!
九、总结回顾scrapy流程
[外链图片转存中…(img-1QjVNZtC-1743595432910)]
如果将上一个管道的return删除掉的话,如下:
[外链图片转存中…(img-braJnzIG-1743595432910)]
[外链图片转存中…(img-MRgcynWa-1743595432910)]
你当然可以在上个管道加个代码
item[“haha”] = “呵呵”
[外链图片转存中…(img-lm0ey5zX-1743595432911)]
第二个管道打印即可:

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









