







 本文详细介绍了使用Pandas进行数据分组和聚合的基本操作,包括如何通过不同方式分组数据,应用多种函数进行数据聚合,以及如何利用迭代、透视表和交叉表等高级功能。通过实例展示了如何提升数据分析效率。
本文详细介绍了使用Pandas进行数据分组和聚合的基本操作,包括如何通过不同方式分组数据,应用多种函数进行数据聚合,以及如何利用迭代、透视表和交叉表等高级功能。通过实例展示了如何提升数据分析效率。
基本操作
np.random.seed(123)
df=pd.DataFrame({'key1':['a','a','b','b','a'],
'key2':['one','two','one','two','one'],
'data1':np.random.randn(5),
'data2':np.random.randn(5)})
df['data1'].groupby(df['key1']).mean() #分组键会作为返回数组的键
df.groupby(['key1','key2'])['data1'].mean()
df.groupby(['key1','key2'])[['data1']].mean() #返回DataFrame形式
df.groupby(['key1','key2'],as_index=False)['data1'].mean() #无索引形式返回
states=np.array(['ohio','calif','calif','ohio','ohio'])
years=np.array(['2005','2005','2006','2005','2006'])
df['data1'].groupby([states,years]).mean() #先把数组join到df里面再执行分组
df.groupby(['key1','key2']).size()
对分组进行迭代
for name,group in df.groupby('key1'):
print(name)
print(group)
for (k1,k2),group in df.groupby(['key1','key2']):
print(k1,k2)
print(group)
pieces=dict(list(df.groupby('key1'))) #list返回元组元素的序列
print(pieces['b'])
dict(list(df.groupby(df.dtypes,axis=1))) #按列分组
通过字典或Series进行分组
people=pd.DataFrame(np.random.randn(5,5),
columns=list('abcde'),
index=['joe','steve','wes','jim','travis'])
people.ix[2:3,['b','c']]=np.nan
mapping={'a':'red','b':'red','c':'blue','d':'blue','e':'red','f':'orange'}
people.groupby(mapping,axis=1).sum()
map_series=pd.Series(mapping)
people.groupby(map_series,axis=1).count()
通过函数对索引操作进行分组
people.groupby(len).sum() #在各个索引值上调用len,按返回值分组
key_list=['one','one','one','two','two']
people.groupby([len,key_list]).sum() #先把数组join到df里面再执行分组
根据索引级别分组

数据聚合
def peak_to_peak(arr):
return arr.max()-arr.min()
grouped.agg(peak_to_peak) #每个分组放入自定义函数,聚合所有的返回数组
grouped.describe() #打印每个分组情况
经过优化的groupby的方法
| 函数名 | groupby |
|---|---|
| count | 计算分组中非NA值数量 |
| sum | 非NA值的和 |
| mean | 非NA值的平均值 |
| median | 非NA值得中位数 |
| std,var | 无偏(分母位n-1)标准差和方差 |
| min,max | 非NA值得最小值和最大值 |
| prod | 非NA的乘积 |
| first,last | 首个或未个非NA值 |
| quantile | 计算分位数 |
多函数应用
grouped['tip_pct'].agg(['mean','std',peak_topeak])
grouped.agg([('foo','mean'),('bar',np.std)])
grouped.agg({'tip_pct':['min','max',np.mean],'size':'sum'})
分组级运算和转换
# 把分组计算数据链接在原表上
k1_means=df.groupby('key1').mean().add_prefix('mean_')
pd.merge(df,k1_means,left_on='key1',right_index=True)
transform把函数应用到分组上,再把数据替换在people上并返回,符合广播原则

apply应用
- apply把分组放入定义函数并返回经过处理的分组df,可传入定义额参数
- 传入额函数可以返回df或dict

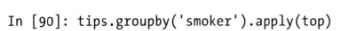
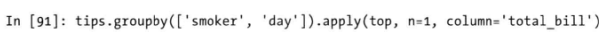
- 相当于执行2条
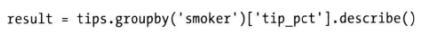
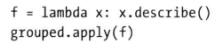
- 禁止分组键group_keys
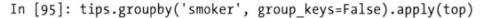
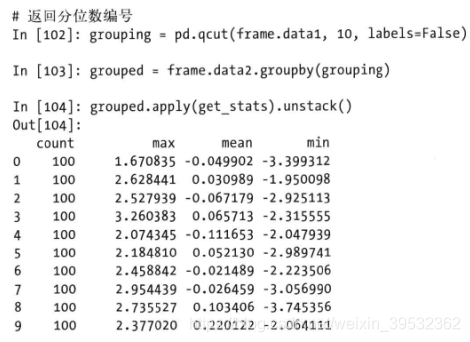
分位数和桶分析


返回相等数量的桶用labels
透视表
pivot_table的参数
| 参数 | 说明 |
|---|---|
| values | 待聚合的列名称,默认聚合所有列 |
| rows | 用作分组的列名,结果的行坐标 |
| cols | 用作分组的列名,结果的列坐标 |
| aggfunc | 聚合函数,默认‘mean’ |
| fill_value | 用作替换结果NA值 |
| margins | 添加行列小计/总和 |
交叉表
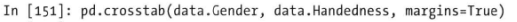

















 1833
1833

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









