







 本文笔记整理自相关书籍,介绍了Hadoop与MySQL之间的数据导入导出过程。导入有分步和一步导入两种方式,需确保节点对MySQL数据库有访问权限,数据从MySQL表到HDFS再到Hive;导出需先在MySQL创建表,再执行命令将数据从Hive到MySQL。
本文笔记整理自相关书籍,介绍了Hadoop与MySQL之间的数据导入导出过程。导入有分步和一步导入两种方式,需确保节点对MySQL数据库有访问权限,数据从MySQL表到HDFS再到Hive;导出需先在MySQL创建表,再执行命令将数据从Hive到MySQL。
------------本文笔记整理自《Hadoop海量数据处理:技术详解与项目实战》范东来
**导入导出时出现的问题处理链接:Sqoop安装及相关问题笔记(持续更新)
一、导入过程
1.导入过程图解:
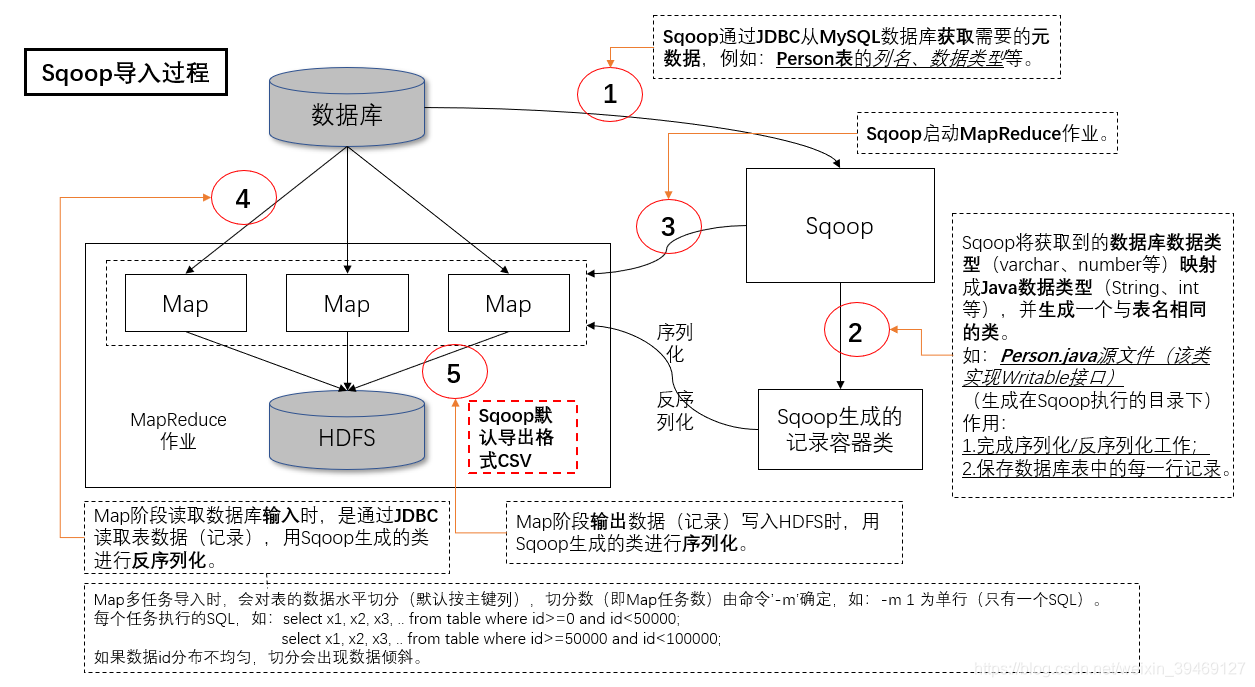
2.导入命令:(两种方式:分步导入和一步导入)
2.1.首先确保集群中的所有节点对MySQL服务器的数据库hive有访问权限
(参看之前整理:导入数据访问MySQL时被拒的处理)
2.2.分步导入:(3步) MySQL表数据 ---> HDFS ---> Hive
1.步骤1:MySQL ---> HDFS
1.1.连接MySQL将hive数据库中的DBS表数据导入到HDFS中
$ sqoop import --connect jdbc:mysql://master:3306/hive -table DBS -username root -P -m 1
1.2.成功导入后,结果将输出到MapReduce作业输出文件夹中
:查看在HDFS中创建的DBS的表目录
$ hadoop fs -ls /user/root/DBS/;
/user/root/DBS/_SUCCESS
/user/root/DBS/part-m-00000 --表数据
2.步骤2:在Hive中创建表
2.1.将导入到HDFS中的数据导入到Hive中,执行sqoop创建Hive表命令
$ sqoop create-hive-table
--connect jdbc:mysql://master:3306/hive
--table DBS --fields-terminated-by ','
--username root -P
注:由于Sqoop默认导出格式为CSV(逗号分隔),
故建表时指定 --fields-terminated-by ','
2.2.执行成功后,查询Hive中的DBS表目录
$ hadoop fs -ls /user/hive/warehouse/;
/user/hive/warehouse/dbs --dbs文件夹下为空,无数据
或者执行hive查询:
hive> select * from dbs; (默认default数据库)
3.步骤3:HDFS ---> Hive
3.1.进入Hive导入数据(向表中追加数据)
hive> load data inpath '/user/root/DBS/part-m-00000' into table dbs;
3.2.查看数据
hive> select * from dbs;
<到此,导入成功>
2.3.一步导入:(只是命令只需执行一句,实际仍然为3步) MySQL表数据 ---> HDFS ---> Hive
$ sqoop import
--connect jdbc:mysql://master:3306/hive
--table DBS
--username root -P
-m 1
--hive-import
注:通过加上 --hive-import ,
Sqoop会根据数据库中的表结构自动生成Hive表结构
注:此过程中依然会在HDFS中生成MapReduce作业输出/user/root/DBS,
只是最后在将part-m-00000数据文件移动到Hive目录下后会自动删除。
二、导出过程
1.导出过程图解:
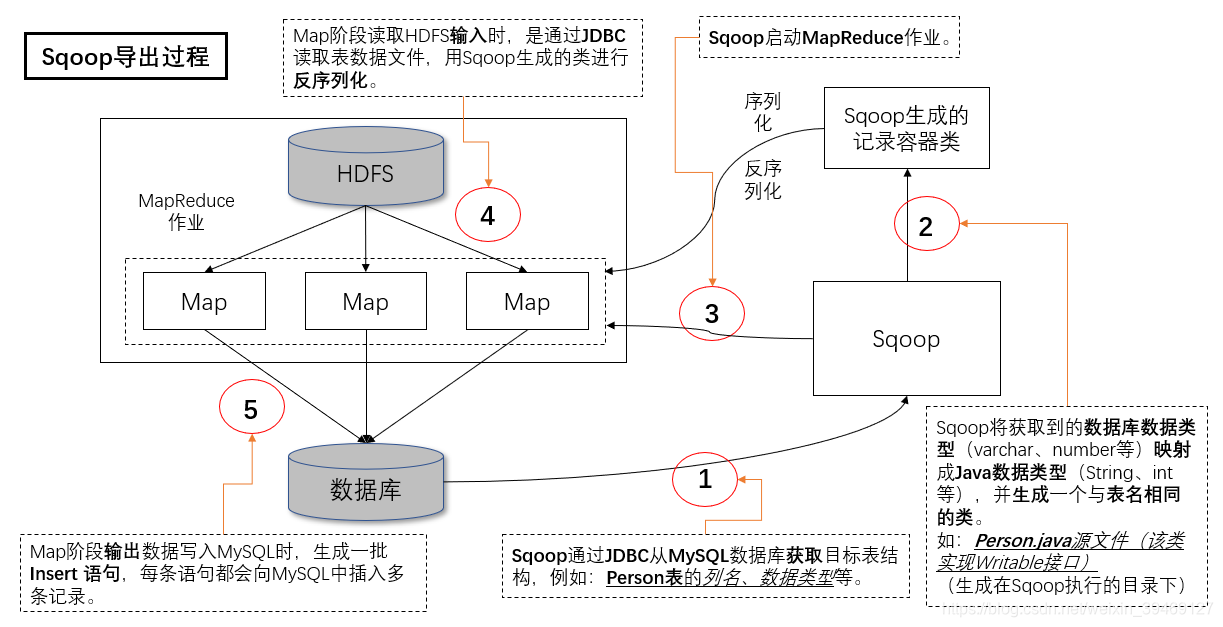
2. 导出方式:
2.1.首先需要在MySQL数据库中创建接受数据的表
1.查看Hive导出表的字段描述信息(包括分隔符)
hive> desc formatted data;
OK
id1 int
id2 int
...
Storage Desc parmas:
field.delim ,
注:如果分隔符显示空,直接查看表数据存储文件
注:Hive表默认的列分隔符为'\001'
2.创建MySQL数据库中接收数据的表
mysql> use test;
Database changed
mysql> create table data(id1 int, id2 int);
2.2.执行导出命令:Hive ---> MySQL
1.执行从Hive导出表到MySQL中
$ sqoop export
--connect jdbc:mysql://master:3306/test
--table data
--export-dir /user/hive/warehouse/test.db/data
--username root -P
-m 1
--fields-terminated-by ','
注:--fields-terminated-by ',' 是将Hive表data的列分隔符告知sqoop,以便读取
2.导出成功,进入MySQL查看
mysql> select * from test.data;
1,2
2,3
3,4

















 568
568

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









