



 博客提及解决问题的指令,强调遇到问题可通过google解决,注重debug能力。还列出了ssd中Makefile.config、makefile文件,以及/ssd/python/caffe/model_libs.py脚本内容,同时提到SSD文件下/examples/ssd/ssd_pascal_webcam.py文件内容。
博客提及解决问题的指令,强调遇到问题可通过google解决,注重debug能力。还列出了ssd中Makefile.config、makefile文件,以及/ssd/python/caffe/model_libs.py脚本内容,同时提到SSD文件下/examples/ssd/ssd_pascal_webcam.py文件内容。
以下是解决问题用到的指令.遇到问题可google解决,每台电脑的问题不一样,总得折腾,重要的是debug能力.
1.
nvidia-smi
cat /usr/local/cuda/version.txt
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
sudo apt-get install libprotobuf-dev libleveldb-dev libsnappy-dev libopencv-dev libhdf5-serial-dev protobuf-compiler libgflags-dev libgoogle-glog-dev liblmdb-dev libatlas-base-dev git
sudo apt-get install --no-install-recommends libboost-all-dev
sudo apt-get install gcc-5
sudo apt-get install g++-5
sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-5 50
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-5 50
wget https://raw.githubusercontent.com/opencv/opencv_3rdparty/ippicv/master_20151201/ippicv/ippicv_linux_20151201.tgz
cmake ..
cmake -D WITH_CUDA=OFF ..
make -j22
sudo apt-get install liblapacke-dev checkinstall
make clean
make -j22
sudo make install
git clone https://github.com/opencv/opencv.git
5
cd /usr/local/lib
which python
wget https://dl.bintray.com/boostorg/release/1.68.0/source/boost_1_68_0.tar.gz
tar zxvf boost_1_68_0.tar.gz
cd boost_1_68_0/
./bootstrap.sh --with-libraries=all --with-toolset=gcc
./b2 toolset=gcc
./b2 install --prefix=/usr
sudo ./b2 install --prefix=/usr
sudo ldconfig
sudo mv libboost_python.so libboost_python.so.back
sudo ln -s libboost_python-py35.so libboost_python.so
sudo ln -s libboost_python-py35.so libboost_python3.so
export CXXFLAGS="$CXXFLAGS -fPIC"
make clean
make all -j33 && make pycaffe
source ~/.bashrc
export PYTHONPATH=/home/yuyang/ssd/python:$PYTHONPATH
sudo apt install 2to3
2to3
2to3 --help
cd ssd
2to3 examples/ssd/ssd_pascal_webcam.py -w
make clean
make all -j33 && make pycaffe
python3
import caffe 不报错
export PYTHONPATH=/home/yuyang/ssd/python:$PYTHONPATH
python3 examples/ssd/ssd_pascal_webcam.py
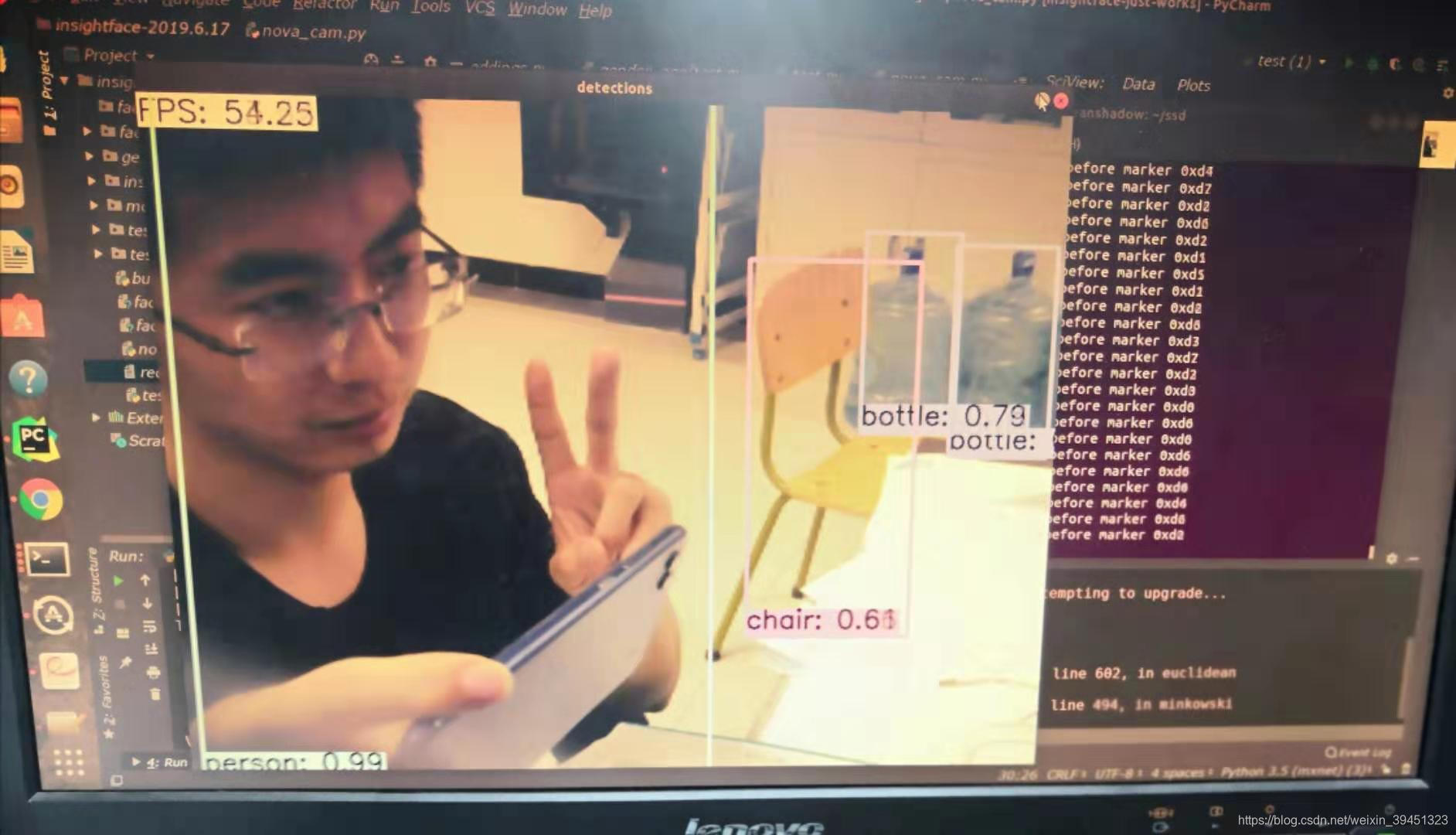
结果:
- ssd中Makefile.config内容
## Refer to http://caffe.berkeleyvision.org/installation.html
# Contributions simplifying and improving our build system are welcome!
# cuDNN acceleration switch (uncomment to build with cuDNN).
USE_CUDNN := 1
# CPU-only switch (uncomment to build without GPU support).
# CPU_ONLY := 1
# uncomment to disable IO dependencies and corresponding data layers
# USE_OPENCV := 0
# USE_LEVELDB := 0
# USE_LMDB := 0
# This code is taken from https://github.com/sh1r0/caffe-android-lib
# USE_HDF5 := 0
# uncomment to allow MDB_NOLOCK when reading LMDB files (only if necessary)
# You should not set this flag if you will be reading LMDBs with any
# possibility of simultaneous read and write
# ALLOW_LMDB_NOLOCK := 1
# Uncomment if you're using OpenCV 3
OPENCV_VERSION := 3
# To customize your choice of compiler, uncomment and set the following.
# N.B. the default for Linux is g++ and the default for OSX is clang++
# CUSTOM_CXX := g++
# CUDA directory contains bin/ and lib/ directories that we need.
CUDA_DIR := /usr/local/cuda
# On Ubuntu 14.04, if cuda tools are installed via
# "sudo apt-get install nvidia-cuda-toolkit" then use this instead:
# CUDA_DIR := /usr
# CUDA architecture setting: going with all of them.
# For CUDA < 6.0, comment the *_50 through *_61 lines for compatibility.
# For CUDA < 8.0, comment the *_60 and *_61 lines for compatibility.
# For CUDA >= 9.0, comment the *_20 and *_21 lines for compatibility.
CUDA_ARCH := -gencode arch=compute_61,code=sm_61 \
-gencode arch=compute_61,code=compute_61
# BLAS choice:
# atlas for ATLAS (default)
# mkl for MKL
# open for OpenBlas
BLAS := atlas
# Custom (MKL/ATLAS/OpenBLAS) include and lib directories.
# Leave commented to accept the defaults for your choice of BLAS
# (which should work)!
# BLAS_INCLUDE := /path/to/your/blas
# BLAS_LIB := /path/to/your/blas
# Homebrew puts openblas in a directory that is not on the standard search path
# BLAS_INCLUDE := $(shell brew --prefix openblas)/include
# BLAS_LIB := $(shell brew --prefix openblas)/lib
# This is required only if you will compile the matlab interface.
# MATLAB directory should contain the mex binary in /bin.
# MATLAB_DIR := /usr/local
# MATLAB_DIR := /Applications/MATLAB_R2012b.app
# NOTE: this is required only if you will compile the python interface.
# We need to be able to find Python.h and numpy/arrayobject.h.
#PYTHON_INCLUDE := /usr/include/python2.7 \
# /usr/lib/python2.7/dist-packages/numpy/core/include
# Anaconda Python distribution is quite popular. Include path:
# Verify anaconda location, sometimes it's in root.
#ANACONDA_HOME := /home/yuyang/anaconda3/envs/caffe
#PYTHON_LIBRARIES := boost_python3 python3.5m
#PYTHON_INCLUDE := $(ANACONDA_HOME)/include \
# $(ANACONDA_HOME)/include/python3.5m \
# $(ANACONDA_HOME)/lib/python3.5/site-packages/numpy/core/include
#
# Uncomment to use Python 3 (default is Python 2)
PYTHON_LIBRARIES := boost_python-py36 python3.6m
PYTHON_INCLUDE := /usr/include/python3.6m \
/usr/local/lib/python3.6/dist-packages/numpy/core/include
# We need to be able to find libpythonX.X.so or .dylib.
PYTHON_LIB := /usr/lib
#PYTHON_LIB := $(ANACONDA_HOME)/lib
# Homebrew installs numpy in a non standard path (keg only)
# PYTHON_INCLUDE += $(dir $(shell python -c 'import numpy.core; print(numpy.core.__file__)'))/include
# PYTHON_LIB += $(shell brew --prefix numpy)/lib
# Uncomment to support layers written in Python (will link against Python libs)
WITH_PYTHON_LAYER := 1
# Whatever else you find you need goes here.
INCLUDE_DIRS := $(PYTHON_INCLUDE) /usr/local/include /usr/include/hdf5/serial
LIBRARY_DIRS := $(PYTHON_LIB) /usr/local/lib /usr/lib /usr/lib/x86_64-linux-gnu /usr/lib/x86_64-linux-gnu/hdf5/serial
# If Homebrew is installed at a non standard location (for example your home directory) and you use it for general dependencies
# INCLUDE_DIRS += $(shell brew --prefix)/include
# LIBRARY_DIRS += $(shell brew --prefix)/lib
# NCCL acceleration switch (uncomment to build with NCCL)
# https://github.com/NVIDIA/nccl (last tested version: v1.2.3-1+cuda8.0)
# USE_NCCL := 1
# Uncomment to use `pkg-config` to specify OpenCV library paths.
# (Usually not necessary -- OpenCV libraries are normally installed in one of the above $LIBRARY_DIRS.)
# USE_PKG_CONFIG := 1
# N.B. both build and distribute dirs are cleared on `make clean`
BUILD_DIR := build
DISTRIBUTE_DIR := distribute
# Uncomment for debugging. Does not work on OSX due to https://github.com/BVLC/caffe/issues/171
# DEBUG := 1
# The ID of the GPU that 'make runtest' will use to run unit tests.
TEST_GPUID := 0
# enable pretty build (comment to see full commands)
Q ?= @
- ssd中makefile文件
PROJECT := caffe
CONFIG_FILE := Makefile.config
# Explicitly check for the config file, otherwise make -k will proceed anyway.
ifeq ($(wildcard $(CONFIG_FILE)),)
$(error $(CONFIG_FILE) not found. See $(CONFIG_FILE).example.)
endif
include $(CONFIG_FILE)
BUILD_DIR_LINK := $(BUILD_DIR)
ifeq ($(RELEASE_BUILD_DIR),)
RELEASE_BUILD_DIR := .$(BUILD_DIR)_release
endif
ifeq ($(DEBUG_BUILD_DIR),)
DEBUG_BUILD_DIR := .$(BUILD_DIR)_debug
endif
DEBUG ?= 0
ifeq ($(DEBUG), 1)
BUILD_DIR := $(DEBUG_BUILD_DIR)
OTHER_BUILD_DIR := $(RELEASE_BUILD_DIR)
else
BUILD_DIR := $(RELEASE_BUILD_DIR)
OTHER_BUILD_DIR := $(DEBUG_BUILD_DIR)
endif
# All of the directories containing code.
SRC_DIRS := $(shell find * -type d -exec bash -c "find {} -maxdepth 1 \
\( -name '*.cpp' -o -name '*.proto' \) | grep -q ." \; -print)
# The target shared library name
LIBRARY_NAME := $(PROJECT)
LIB_BUILD_DIR := $(BUILD_DIR)/lib
STATIC_NAME := $(LIB_BUILD_DIR)/lib$(LIBRARY_NAME).a
DYNAMIC_VERSION_MAJOR := 1
DYNAMIC_VERSION_MINOR := 0
DYNAMIC_VERSION_REVISION := 0
DYNAMIC_NAME_SHORT := lib$(LIBRARY_NAME).so
#DYNAMIC_SONAME_SHORT := $(DYNAMIC_NAME_SHORT).$(DYNAMIC_VERSION_MAJOR)
DYNAMIC_VERSIONED_NAME_SHORT := $(DYNAMIC_NAME_SHORT).$(DYNAMIC_VERSION_MAJOR).$(DYNAMIC_VERSION_MINOR).$(DYNAMIC_VERSION_REVISION)
DYNAMIC_NAME := $(LIB_BUILD_DIR)/$(DYNAMIC_VERSIONED_NAME_SHORT)
COMMON_FLAGS += -DCAFFE_VERSION=$(DYNAMIC_VERSION_MAJOR).$(DYNAMIC_VERSION_MINOR).$(DYNAMIC_VERSION_REVISION)
##############################
# Get all source files
##############################
# CXX_SRCS are the source files excluding the test ones.
CXX_SRCS := $(shell find src/$(PROJECT) ! -name "test_*.cpp" -name "*.cpp")
# CU_SRCS are the cuda source files
CU_SRCS := $(shell find src/$(PROJECT) ! -name "test_*.cu" -name "*.cu")
# TEST_SRCS are the test source files
TEST_MAIN_SRC := src/$(PROJECT)/test/test_caffe_main.cpp
TEST_SRCS := $(shell find src/$(PROJECT) -name "test_*.cpp")
TEST_SRCS := $(filter-out $(TEST_MAIN_SRC), $(TEST_SRCS))
TEST_CU_SRCS := $(shell find src/$(PROJECT) -name "test_*.cu")
GTEST_SRC := src/gtest/gtest-all.cpp
# TOOL_SRCS are the source files for the tool binaries
TOOL_SRCS := $(shell find tools -name "*.cpp")
# EXAMPLE_SRCS are the source files for the example binaries
EXAMPLE_SRCS := $(shell find examples -name "*.cpp")
# BUILD_INCLUDE_DIR contains any generated header files we want to include.
BUILD_INCLUDE_DIR := $(BUILD_DIR)/src
# PROTO_SRCS are the protocol buffer definitions
PROTO_SRC_DIR := src/$(PROJECT)/proto
PROTO_SRCS := $(wildcard $(PROTO_SRC_DIR)/*.proto)
# PROTO_BUILD_DIR will contain the .cc and obj files generated from
# PROTO_SRCS; PROTO_BUILD_INCLUDE_DIR will contain the .h header files
PROTO_BUILD_DIR := $(BUILD_DIR)/$(PROTO_SRC_DIR)
PROTO_BUILD_INCLUDE_DIR := $(BUILD_INCLUDE_DIR)/$(PROJECT)/proto
# NONGEN_CXX_SRCS includes all source/header files except those generated
# automatically (e.g., by proto).
NONGEN_CXX_SRCS := $(shell find \
src/$(PROJECT) \
include/$(PROJECT) \
python/$(PROJECT) \
matlab/+$(PROJECT)/private \
examples \
tools \
-name "*.cpp" -or -name "*.hpp" -or -name "*.cu" -or -name "*.cuh")
LINT_SCRIPT := scripts/cpp_lint.py
LINT_OUTPUT_DIR := $(BUILD_DIR)/.lint
LINT_EXT := lint.txt
LINT_OUTPUTS := $(addsuffix .$(LINT_EXT), $(addprefix $(LINT_OUTPUT_DIR)/, $(NONGEN_CXX_SRCS)))
EMPTY_LINT_REPORT := $(BUILD_DIR)/.$(LINT_EXT)
NONEMPTY_LINT_REPORT := $(BUILD_DIR)/$(LINT_EXT)
# PY$(PROJECT)_SRC is the python wrapper for $(PROJECT)
PY$(PROJECT)_SRC := python/$(PROJECT)/_$(PROJECT).cpp
PY$(PROJECT)_SO := python/$(PROJECT)/_$(PROJECT).so
PY$(PROJECT)_HXX := include/$(PROJECT)/layers/python_layer.hpp
# MAT$(PROJECT)_SRC is the mex entrance point of matlab package for $(PROJECT)
MAT$(PROJECT)_SRC := matlab/+$(PROJECT)/private/$(PROJECT)_.cpp
ifneq ($(MATLAB_DIR),)
MAT_SO_EXT := $(shell $(MATLAB_DIR)/bin/mexext)
endif
MAT$(PROJECT)_SO := matlab/+$(PROJECT)/private/$(PROJECT)_.$(MAT_SO_EXT)
##############################
# Derive generated files
##############################
# The generated files for protocol buffers
PROTO_GEN_HEADER_SRCS := $(addprefix $(PROTO_BUILD_DIR)/, \
$(notdir ${PROTO_SRCS:.proto=.pb.h}))
PROTO_GEN_HEADER := $(addprefix $(PROTO_BUILD_INCLUDE_DIR)/, \
$(notdir ${PROTO_SRCS:.proto=.pb.h}))
PROTO_GEN_CC := $(addprefix $(BUILD_DIR)/, ${PROTO_SRCS:.proto=.pb.cc})
PY_PROTO_BUILD_DIR := python/$(PROJECT)/proto
PY_PROTO_INIT := python/$(PROJECT)/proto/__init__.py
PROTO_GEN_PY := $(foreach file,${PROTO_SRCS:.proto=_pb2.py}, \
$(PY_PROTO_BUILD_DIR)/$(notdir $(file)))
# The objects corresponding to the source files
# These objects will be linked into the final shared library, so we
# exclude the tool, example, and test objects.
CXX_OBJS := $(addprefix $(BUILD_DIR)/, ${CXX_SRCS:.cpp=.o})
CU_OBJS := $(addprefix $(BUILD_DIR)/cuda/, ${CU_SRCS:.cu=.o})
PROTO_OBJS := ${PROTO_GEN_CC:.cc=.o}
OBJS := $(PROTO_OBJS) $(CXX_OBJS) $(CU_OBJS)
# tool, example, and test objects
TOOL_OBJS := $(addprefix $(BUILD_DIR)/, ${TOOL_SRCS:.cpp=.o})
TOOL_BUILD_DIR := $(BUILD_DIR)/tools
TEST_CXX_BUILD_DIR := $(BUILD_DIR)/src/$(PROJECT)/test
TEST_CU_BUILD_DIR := $(BUILD_DIR)/cuda/src/$(PROJECT)/test
TEST_CXX_OBJS := $(addprefix $(BUILD_DIR)/, ${TEST_SRCS:.cpp=.o})
TEST_CU_OBJS := $(addprefix $(BUILD_DIR)/cuda/, ${TEST_CU_SRCS:.cu=.o})
TEST_OBJS := $(TEST_CXX_OBJS) $(TEST_CU_OBJS)
GTEST_OBJ := $(addprefix $(BUILD_DIR)/, ${GTEST_SRC:.cpp=.o})
EXAMPLE_OBJS := $(addprefix $(BUILD_DIR)/, ${EXAMPLE_SRCS:.cpp=.o})
# Output files for automatic dependency generation
DEPS := ${CXX_OBJS:.o=.d} ${CU_OBJS:.o=.d} ${TEST_CXX_OBJS:.o=.d} \
${TEST_CU_OBJS:.o=.d} $(BUILD_DIR)/${MAT$(PROJECT)_SO:.$(MAT_SO_EXT)=.d}
# tool, example, and test bins
TOOL_BINS := ${TOOL_OBJS:.o=.bin}
EXAMPLE_BINS := ${EXAMPLE_OBJS:.o=.bin}
# symlinks to tool bins without the ".bin" extension
TOOL_BIN_LINKS := ${TOOL_BINS:.bin=}
# Put the test binaries in build/test for convenience.
TEST_BIN_DIR := $(BUILD_DIR)/test
TEST_CU_BINS := $(addsuffix .testbin,$(addprefix $(TEST_BIN_DIR)/, \
$(foreach obj,$(TEST_CU_OBJS),$(basename $(notdir $(obj))))))
TEST_CXX_BINS := $(addsuffix .testbin,$(addprefix $(TEST_BIN_DIR)/, \
$(foreach obj,$(TEST_CXX_OBJS),$(basename $(notdir $(obj))))))
TEST_BINS := $(TEST_CXX_BINS) $(TEST_CU_BINS)
# TEST_ALL_BIN is the test binary that links caffe dynamically.
TEST_ALL_BIN := $(TEST_BIN_DIR)/test_all.testbin
##############################
# Derive compiler warning dump locations
##############################
WARNS_EXT := warnings.txt
CXX_WARNS := $(addprefix $(BUILD_DIR)/, ${CXX_SRCS:.cpp=.o.$(WARNS_EXT)})
CU_WARNS := $(addprefix $(BUILD_DIR)/cuda/, ${CU_SRCS:.cu=.o.$(WARNS_EXT)})
TOOL_WARNS := $(addprefix $(BUILD_DIR)/, ${TOOL_SRCS:.cpp=.o.$(WARNS_EXT)})
EXAMPLE_WARNS := $(addprefix $(BUILD_DIR)/, ${EXAMPLE_SRCS:.cpp=.o.$(WARNS_EXT)})
TEST_WARNS := $(addprefix $(BUILD_DIR)/, ${TEST_SRCS:.cpp=.o.$(WARNS_EXT)})
TEST_CU_WARNS := $(addprefix $(BUILD_DIR)/cuda/, ${TEST_CU_SRCS:.cu=.o.$(WARNS_EXT)})
ALL_CXX_WARNS := $(CXX_WARNS) $(TOOL_WARNS) $(EXAMPLE_WARNS) $(TEST_WARNS)
ALL_CU_WARNS := $(CU_WARNS) $(TEST_CU_WARNS)
ALL_WARNS := $(ALL_CXX_WARNS) $(ALL_CU_WARNS)
EMPTY_WARN_REPORT := $(BUILD_DIR)/.$(WARNS_EXT)
NONEMPTY_WARN_REPORT := $(BUILD_DIR)/$(WARNS_EXT)
##############################
# Derive include and lib directories
##############################
CUDA_INCLUDE_DIR := $(CUDA_DIR)/include
CUDA_LIB_DIR :=
# add <cuda>/lib64 only if it exists
ifneq ("$(wildcard $(CUDA_DIR)/lib64)","")
CUDA_LIB_DIR += $(CUDA_DIR)/lib64
endif
CUDA_LIB_DIR += $(CUDA_DIR)/lib
INCLUDE_DIRS += $(BUILD_INCLUDE_DIR) ./src ./include
ifneq ($(CPU_ONLY), 1)
INCLUDE_DIRS += $(CUDA_INCLUDE_DIR)
LIBRARY_DIRS += $(CUDA_LIB_DIR)
LIBRARIES := cudart cublas curand
endif
LIBRARIES += glog gflags protobuf boost_system boost_filesystem m
# handle IO dependencies
USE_LEVELDB ?= 1
USE_LMDB ?= 1
# This code is taken from https://github.com/sh1r0/caffe-android-lib
USE_HDF5 ?= 1
USE_OPENCV ?= 1
ifeq ($(USE_LEVELDB), 1)
LIBRARIES += leveldb snappy
endif
ifeq ($(USE_LMDB), 1)
LIBRARIES += lmdb
endif
# This code is taken from https://github.com/sh1r0/caffe-android-lib
ifeq ($(USE_HDF5), 1)
LIBRARIES += hdf5_hl hdf5
endif
ifeq ($(USE_OPENCV), 1)
LIBRARIES += opencv_core opencv_highgui opencv_imgproc opencv_videoio opencv_imgcodecs
ifeq ($(OPENCV_VERSION), 3)
LIBRARIES += opencv_imgcodecs
endif
endif
PYTHON_LIBRARIES ?= boost_python python2.7
WARNINGS := -Wall -Wno-sign-compare
##############################
# Set build directories
##############################
DISTRIBUTE_DIR ?= distribute
DISTRIBUTE_SUBDIRS := $(DISTRIBUTE_DIR)/bin $(DISTRIBUTE_DIR)/lib
DIST_ALIASES := dist
ifneq ($(strip $(DISTRIBUTE_DIR)),distribute)
DIST_ALIASES += distribute
endif
ALL_BUILD_DIRS := $(sort $(BUILD_DIR) $(addprefix $(BUILD_DIR)/, $(SRC_DIRS)) \
$(addprefix $(BUILD_DIR)/cuda/, $(SRC_DIRS)) \
$(LIB_BUILD_DIR) $(TEST_BIN_DIR) $(PY_PROTO_BUILD_DIR) $(LINT_OUTPUT_DIR) \
$(DISTRIBUTE_SUBDIRS) $(PROTO_BUILD_INCLUDE_DIR))
##############################
# Set directory for Doxygen-generated documentation
##############################
DOXYGEN_CONFIG_FILE ?= ./.Doxyfile
# should be the same as OUTPUT_DIRECTORY in the .Doxyfile
DOXYGEN_OUTPUT_DIR ?= ./doxygen
DOXYGEN_COMMAND ?= doxygen
# All the files that might have Doxygen documentation.
DOXYGEN_SOURCES := $(shell find \
src/$(PROJECT) \
include/$(PROJECT) \
python/ \
matlab/ \
examples \
tools \
-name "*.cpp" -or -name "*.hpp" -or -name "*.cu" -or -name "*.cuh" -or \
-name "*.py" -or -name "*.m")
DOXYGEN_SOURCES += $(DOXYGEN_CONFIG_FILE)
##############################
# Configure build
##############################
# Determine platform
UNAME := $(shell uname -s)
ifeq ($(UNAME), Linux)
LINUX := 1
else ifeq ($(UNAME), Darwin)
OSX := 1
OSX_MAJOR_VERSION := $(shell sw_vers -productVersion | cut -f 1 -d .)
OSX_MINOR_VERSION := $(shell sw_vers -productVersion | cut -f 2 -d .)
endif
# Linux
ifeq ($(LINUX), 1)
CXX ?= /usr/bin/g++
GCCVERSION := $(shell $(CXX) -dumpversion | cut -f1,2 -d.)
# older versions of gcc are too dumb to build boost with -Wuninitalized
ifeq ($(shell echo | awk '{exit $(GCCVERSION) < 4.6;}'), 1)
WARNINGS += -Wno-uninitialized
endif
# boost::thread is reasonably called boost_thread (compare OS X)
# We will also explicitly add stdc++ to the link target.
LIBRARIES += boost_thread stdc++
VERSIONFLAGS += -Wl,-soname,$(DYNAMIC_VERSIONED_NAME_SHORT) -Wl,-rpath,$(ORIGIN)/../lib
endif
# OS X:
# clang++ instead of g++
# libstdc++ for NVCC compatibility on OS X >= 10.9 with CUDA < 7.0
ifeq ($(OSX), 1)
CXX := /usr/bin/clang++
ifneq ($(CPU_ONLY), 1)
CUDA_VERSION := $(shell $(CUDA_DIR)/bin/nvcc -V | grep -o 'release [0-9.]*' | tr -d '[a-z ]')
ifeq ($(shell echo | awk '{exit $(CUDA_VERSION) < 7.0;}'), 1)
CXXFLAGS += -stdlib=libstdc++
LINKFLAGS += -stdlib=libstdc++
endif
# clang throws this warning for cuda headers
WARNINGS += -Wno-unneeded-internal-declaration
# 10.11 strips DYLD_* env vars so link CUDA (rpath is available on 10.5+)
OSX_10_OR_LATER := $(shell [ $(OSX_MAJOR_VERSION) -ge 10 ] && echo true)
OSX_10_5_OR_LATER := $(shell [ $(OSX_MINOR_VERSION) -ge 5 ] && echo true)
ifeq ($(OSX_10_OR_LATER),true)
ifeq ($(OSX_10_5_OR_LATER),true)
LDFLAGS += -Wl,-rpath,$(CUDA_LIB_DIR)
endif
endif
endif
# gtest needs to use its own tuple to not conflict with clang
COMMON_FLAGS += -DGTEST_USE_OWN_TR1_TUPLE=1
# boost::thread is called boost_thread-mt to mark multithreading on OS X
LIBRARIES += boost_thread-mt
# we need to explicitly ask for the rpath to be obeyed
ORIGIN := @loader_path
VERSIONFLAGS += -Wl,-install_name,@rpath/$(DYNAMIC_VERSIONED_NAME_SHORT) -Wl,-rpath,$(ORIGIN)/../../build/lib
else
ORIGIN := \$$ORIGIN
endif
# Custom compiler
ifdef CUSTOM_CXX
CXX := $(CUSTOM_CXX)
endif
# Static linking
ifneq (,$(findstring clang++,$(CXX)))
STATIC_LINK_COMMAND := -Wl,-force_load $(STATIC_NAME)
else ifneq (,$(findstring g++,$(CXX)))
STATIC_LINK_COMMAND := -Wl,--whole-archive $(STATIC_NAME) -Wl,--no-whole-archive
else
# The following line must not be indented with a tab, since we are not inside a target
$(error Cannot static link with the $(CXX) compiler)
endif
# Debugging
ifeq ($(DEBUG), 1)
COMMON_FLAGS += -DDEBUG -g -O0
NVCCFLAGS += -G
else
COMMON_FLAGS += -DNDEBUG -O2
endif
# cuDNN acceleration configuration.
ifeq ($(USE_CUDNN), 1)
LIBRARIES += cudnn
COMMON_FLAGS += -DUSE_CUDNN
endif
# NCCL acceleration configuration
ifeq ($(USE_NCCL), 1)
LIBRARIES += nccl
COMMON_FLAGS += -DUSE_NCCL
endif
# configure IO libraries
ifeq ($(USE_OPENCV), 1)
COMMON_FLAGS += -DUSE_OPENCV
endif
ifeq ($(USE_LEVELDB), 1)
COMMON_FLAGS += -DUSE_LEVELDB
endif
ifeq ($(USE_LMDB), 1)
COMMON_FLAGS += -DUSE_LMDB
ifeq ($(ALLOW_LMDB_NOLOCK), 1)
COMMON_FLAGS += -DALLOW_LMDB_NOLOCK
endif
endif
# This code is taken from https://github.com/sh1r0/caffe-android-lib
ifeq ($(USE_HDF5), 1)
COMMON_FLAGS += -DUSE_HDF5
endif
# CPU-only configuration
ifeq ($(CPU_ONLY), 1)
OBJS := $(PROTO_OBJS) $(CXX_OBJS)
TEST_OBJS := $(TEST_CXX_OBJS)
TEST_BINS := $(TEST_CXX_BINS)
ALL_WARNS := $(ALL_CXX_WARNS)
TEST_FILTER := --gtest_filter="-*GPU*"
COMMON_FLAGS += -DCPU_ONLY
endif
# Python layer support
ifeq ($(WITH_PYTHON_LAYER), 1)
COMMON_FLAGS += -DWITH_PYTHON_LAYER
LIBRARIES += $(PYTHON_LIBRARIES)
endif
# BLAS configuration (default = ATLAS)
BLAS ?= atlas
ifeq ($(BLAS), mkl)
# MKL
LIBRARIES += mkl_rt
COMMON_FLAGS += -DUSE_MKL
MKLROOT ?= /opt/intel/mkl
BLAS_INCLUDE ?= $(MKLROOT)/include
BLAS_LIB ?= $(MKLROOT)/lib $(MKLROOT)/lib/intel64
else ifeq ($(BLAS), open)
# OpenBLAS
LIBRARIES += openblas
else
# ATLAS
ifeq ($(LINUX), 1)
ifeq ($(BLAS), atlas)
# Linux simply has cblas and atlas
LIBRARIES += cblas atlas
endif
else ifeq ($(OSX), 1)
# OS X packages atlas as the vecLib framework
LIBRARIES += cblas
# 10.10 has accelerate while 10.9 has veclib
XCODE_CLT_VER := $(shell pkgutil --pkg-info=com.apple.pkg.CLTools_Executables | grep 'version' | sed 's/[^0-9]*\([0-9]\).*/\1/')
XCODE_CLT_GEQ_7 := $(shell [ $(XCODE_CLT_VER) -gt 6 ] && echo 1)
XCODE_CLT_GEQ_6 := $(shell [ $(XCODE_CLT_VER) -gt 5 ] && echo 1)
ifeq ($(XCODE_CLT_GEQ_7), 1)
BLAS_INCLUDE ?= /Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/$(shell ls /Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/ | sort | tail -1)/System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/Headers
else ifeq ($(XCODE_CLT_GEQ_6), 1)
BLAS_INCLUDE ?= /System/Library/Frameworks/Accelerate.framework/Versions/Current/Frameworks/vecLib.framework/Headers/
LDFLAGS += -framework Accelerate
else
BLAS_INCLUDE ?= /System/Library/Frameworks/vecLib.framework/Versions/Current/Headers/
LDFLAGS += -framework vecLib
endif
endif
endif
INCLUDE_DIRS += $(BLAS_INCLUDE)
LIBRARY_DIRS += $(BLAS_LIB)
LIBRARY_DIRS += $(LIB_BUILD_DIR)
# Automatic dependency generation (nvcc is handled separately)
CXXFLAGS += -MMD -MP
# Complete build flags.
COMMON_FLAGS += $(foreach includedir,$(INCLUDE_DIRS),-I$(includedir))
CXXFLAGS += -pthread -fPIC $(COMMON_FLAGS) $(WARNINGS)
NVCCFLAGS += -ccbin=$(CXX) -Xcompiler -fPIC $(COMMON_FLAGS)
# mex may invoke an older gcc that is too liberal with -Wuninitalized
MATLAB_CXXFLAGS := $(CXXFLAGS) -Wno-uninitialized
LINKFLAGS += -pthread -fPIC $(COMMON_FLAGS) $(WARNINGS)
USE_PKG_CONFIG ?= 0
ifeq ($(USE_PKG_CONFIG), 1)
PKG_CONFIG := $(shell pkg-config opencv --libs)
else
PKG_CONFIG :=
endif
LDFLAGS += $(foreach librarydir,$(LIBRARY_DIRS),-L$(librarydir)) $(PKG_CONFIG) \
$(foreach library,$(LIBRARIES),-l$(library))
PYTHON_LDFLAGS := $(LDFLAGS) $(foreach library,$(PYTHON_LIBRARIES),-l$(library))
# 'superclean' target recursively* deletes all files ending with an extension
# in $(SUPERCLEAN_EXTS) below. This may be useful if you've built older
# versions of Caffe that do not place all generated files in a location known
# to the 'clean' target.
#
# 'supercleanlist' will list the files to be deleted by make superclean.
#
# * Recursive with the exception that symbolic links are never followed, per the
# default behavior of 'find'.
SUPERCLEAN_EXTS := .so .a .o .bin .testbin .pb.cc .pb.h _pb2.py .cuo
# Set the sub-targets of the 'everything' target.
EVERYTHING_TARGETS := all py$(PROJECT) test warn lint
# Only build matcaffe as part of "everything" if MATLAB_DIR is specified.
ifneq ($(MATLAB_DIR),)
EVERYTHING_TARGETS += mat$(PROJECT)
endif
##############################
# Define build targets
##############################
.PHONY: all lib test clean docs linecount lint lintclean tools examples $(DIST_ALIASES) \
py mat py$(PROJECT) mat$(PROJECT) proto runtest \
superclean supercleanlist supercleanfiles warn everything
all: lib tools examples
lib: $(STATIC_NAME) $(DYNAMIC_NAME)
everything: $(EVERYTHING_TARGETS)
linecount:
cloc --read-lang-def=$(PROJECT).cloc \
src/$(PROJECT) include/$(PROJECT) tools examples \
python matlab
lint: $(EMPTY_LINT_REPORT)
lintclean:
@ $(RM) -r $(LINT_OUTPUT_DIR) $(EMPTY_LINT_REPORT) $(NONEMPTY_LINT_REPORT)
docs: $(DOXYGEN_OUTPUT_DIR)
@ cd ./docs ; ln -sfn ../$(DOXYGEN_OUTPUT_DIR)/html doxygen
$(DOXYGEN_OUTPUT_DIR): $(DOXYGEN_CONFIG_FILE) $(DOXYGEN_SOURCES)
$(DOXYGEN_COMMAND) $(DOXYGEN_CONFIG_FILE)
$(EMPTY_LINT_REPORT): $(LINT_OUTPUTS) | $(BUILD_DIR)
@ cat $(LINT_OUTPUTS) > $@
@ if [ -s "$@" ]; then \
cat $@; \
mv $@ $(NONEMPTY_LINT_REPORT); \
echo "Found one or more lint errors."; \
exit 1; \
fi; \
$(RM) $(NONEMPTY_LINT_REPORT); \
echo "No lint errors!";
$(LINT_OUTPUTS): $(LINT_OUTPUT_DIR)/%.lint.txt : % $(LINT_SCRIPT) | $(LINT_OUTPUT_DIR)
@ mkdir -p $(dir $@)
@ python $(LINT_SCRIPT) $< 2>&1 \
| grep -v "^Done processing " \
| grep -v "^Total errors found: 0" \
> $@ \
|| true
test: $(TEST_ALL_BIN) $(TEST_ALL_DYNLINK_BIN) $(TEST_BINS)
tools: $(TOOL_BINS) $(TOOL_BIN_LINKS)
examples: $(EXAMPLE_BINS)
py$(PROJECT): py
py: $(PY$(PROJECT)_SO) $(PROTO_GEN_PY)
$(PY$(PROJECT)_SO): $(PY$(PROJECT)_SRC) $(PY$(PROJECT)_HXX) | $(DYNAMIC_NAME)
@ echo CXX/LD -o $@ $<
$(Q)$(CXX) -shared -o $@ $(PY$(PROJECT)_SRC) \
-o $@ $(LINKFLAGS) -l$(LIBRARY_NAME) $(PYTHON_LDFLAGS) \
-Wl,-rpath,$(ORIGIN)/../../build/lib
mat$(PROJECT): mat
mat: $(MAT$(PROJECT)_SO)
$(MAT$(PROJECT)_SO): $(MAT$(PROJECT)_SRC) $(STATIC_NAME)
@ if [ -z "$(MATLAB_DIR)" ]; then \
echo "MATLAB_DIR must be specified in $(CONFIG_FILE)" \
"to build mat$(PROJECT)."; \
exit 1; \
fi
@ echo MEX $<
$(Q)$(MATLAB_DIR)/bin/mex $(MAT$(PROJECT)_SRC) \
CXX="$(CXX)" \
CXXFLAGS="\$$CXXFLAGS $(MATLAB_CXXFLAGS)" \
CXXLIBS="\$$CXXLIBS $(STATIC_LINK_COMMAND) $(LDFLAGS)" -output $@
@ if [ -f "$(PROJECT)_.d" ]; then \
mv -f $(PROJECT)_.d $(BUILD_DIR)/${MAT$(PROJECT)_SO:.$(MAT_SO_EXT)=.d}; \
fi
runtest: $(TEST_ALL_BIN)
$(TOOL_BUILD_DIR)/caffe
$(TEST_ALL_BIN) $(TEST_GPUID) --gtest_shuffle $(TEST_FILTER)
pytest: py
cd python; python -m unittest discover -s caffe/test
mattest: mat
cd matlab; $(MATLAB_DIR)/bin/matlab -nodisplay -r 'caffe.run_tests(), exit()'
warn: $(EMPTY_WARN_REPORT)
$(EMPTY_WARN_REPORT): $(ALL_WARNS) | $(BUILD_DIR)
@ cat $(ALL_WARNS) > $@
@ if [ -s "$@" ]; then \
cat $@; \
mv $@ $(NONEMPTY_WARN_REPORT); \
echo "Compiler produced one or more warnings."; \
exit 1; \
fi; \
$(RM) $(NONEMPTY_WARN_REPORT); \
echo "No compiler warnings!";
$(ALL_WARNS): %.o.$(WARNS_EXT) : %.o
$(BUILD_DIR_LINK): $(BUILD_DIR)/.linked
# Create a target ".linked" in this BUILD_DIR to tell Make that the "build" link
# is currently correct, then delete the one in the OTHER_BUILD_DIR in case it
# exists and $(DEBUG) is toggled later.
$(BUILD_DIR)/.linked:
@ mkdir -p $(BUILD_DIR)
@ $(RM) $(OTHER_BUILD_DIR)/.linked
@ $(RM) -r $(BUILD_DIR_LINK)
@ ln -s $(BUILD_DIR) $(BUILD_DIR_LINK)
@ touch $@
$(ALL_BUILD_DIRS): | $(BUILD_DIR_LINK)
@ mkdir -p $@
$(DYNAMIC_NAME): $(OBJS) | $(LIB_BUILD_DIR)
@ echo LD -o $@
$(Q)$(CXX) -shared -o $@ $(OBJS) $(VERSIONFLAGS) $(LINKFLAGS) $(LDFLAGS)
@ cd $(BUILD_DIR)/lib; rm -f $(DYNAMIC_NAME_SHORT); ln -s $(DYNAMIC_VERSIONED_NAME_SHORT) $(DYNAMIC_NAME_SHORT)
$(STATIC_NAME): $(OBJS) | $(LIB_BUILD_DIR)
@ echo AR -o $@
$(Q)ar rcs $@ $(OBJS)
$(BUILD_DIR)/%.o: %.cpp $(PROTO_GEN_HEADER) | $(ALL_BUILD_DIRS)
@ echo CXX $<
$(Q)$(CXX) $< $(CXXFLAGS) -c -o $@ 2> $@.$(WARNS_EXT) \
|| (cat $@.$(WARNS_EXT); exit 1)
@ cat $@.$(WARNS_EXT)
$(PROTO_BUILD_DIR)/%.pb.o: $(PROTO_BUILD_DIR)/%.pb.cc $(PROTO_GEN_HEADER) \
| $(PROTO_BUILD_DIR)
@ echo CXX $<
$(Q)$(CXX) $< $(CXXFLAGS) -c -o $@ 2> $@.$(WARNS_EXT) \
|| (cat $@.$(WARNS_EXT); exit 1)
@ cat $@.$(WARNS_EXT)
$(BUILD_DIR)/cuda/%.o: %.cu | $(ALL_BUILD_DIRS)
@ echo NVCC $<
$(Q)$(CUDA_DIR)/bin/nvcc $(NVCCFLAGS) $(CUDA_ARCH) -M $< -o ${@:.o=.d} \
-odir $(@D)
$(Q)$(CUDA_DIR)/bin/nvcc $(NVCCFLAGS) $(CUDA_ARCH) -c $< -o $@ 2> $@.$(WARNS_EXT) \
|| (cat $@.$(WARNS_EXT); exit 1)
@ cat $@.$(WARNS_EXT)
$(TEST_ALL_BIN): $(TEST_MAIN_SRC) $(TEST_OBJS) $(GTEST_OBJ) \
| $(DYNAMIC_NAME) $(TEST_BIN_DIR)
@ echo CXX/LD -o $@ $<
$(Q)$(CXX) $(TEST_MAIN_SRC) $(TEST_OBJS) $(GTEST_OBJ) \
-o $@ $(LINKFLAGS) $(LDFLAGS) -l$(LIBRARY_NAME) -Wl,-rpath,$(ORIGIN)/../lib
$(TEST_CU_BINS): $(TEST_BIN_DIR)/%.testbin: $(TEST_CU_BUILD_DIR)/%.o \
$(GTEST_OBJ) | $(DYNAMIC_NAME) $(TEST_BIN_DIR)
@ echo LD $<
$(Q)$(CXX) $(TEST_MAIN_SRC) $< $(GTEST_OBJ) \
-o $@ $(LINKFLAGS) $(LDFLAGS) -l$(LIBRARY_NAME) -Wl,-rpath,$(ORIGIN)/../lib
$(TEST_CXX_BINS): $(TEST_BIN_DIR)/%.testbin: $(TEST_CXX_BUILD_DIR)/%.o \
$(GTEST_OBJ) | $(DYNAMIC_NAME) $(TEST_BIN_DIR)
@ echo LD $<
$(Q)$(CXX) $(TEST_MAIN_SRC) $< $(GTEST_OBJ) \
-o $@ $(LINKFLAGS) $(LDFLAGS) -l$(LIBRARY_NAME) -Wl,-rpath,$(ORIGIN)/../lib
# Target for extension-less symlinks to tool binaries with extension '*.bin'.
$(TOOL_BUILD_DIR)/%: $(TOOL_BUILD_DIR)/%.bin | $(TOOL_BUILD_DIR)
@ $(RM) $@
@ ln -s $(notdir $<) $@
$(TOOL_BINS): %.bin : %.o | $(DYNAMIC_NAME)
@ echo CXX/LD -o $@
$(Q)$(CXX) $< -o $@ $(LINKFLAGS) -l$(LIBRARY_NAME) $(LDFLAGS) \
-Wl,-rpath,$(ORIGIN)/../lib
$(EXAMPLE_BINS): %.bin : %.o | $(DYNAMIC_NAME)
@ echo CXX/LD -o $@
$(Q)$(CXX) $< -o $@ $(LINKFLAGS) -l$(LIBRARY_NAME) $(LDFLAGS) \
-Wl,-rpath,$(ORIGIN)/../../lib
proto: $(PROTO_GEN_CC) $(PROTO_GEN_HEADER)
$(PROTO_BUILD_DIR)/%.pb.cc $(PROTO_BUILD_DIR)/%.pb.h : \
$(PROTO_SRC_DIR)/%.proto | $(PROTO_BUILD_DIR)
@ echo PROTOC $<
$(Q)protoc --proto_path=$(PROTO_SRC_DIR) --cpp_out=$(PROTO_BUILD_DIR) $<
$(PY_PROTO_BUILD_DIR)/%_pb2.py : $(PROTO_SRC_DIR)/%.proto \
$(PY_PROTO_INIT) | $(PY_PROTO_BUILD_DIR)
@ echo PROTOC \(python\) $<
$(Q)protoc --proto_path=src --python_out=python $<
$(PY_PROTO_INIT): | $(PY_PROTO_BUILD_DIR)
touch $(PY_PROTO_INIT)
clean:
@- $(RM) -rf $(ALL_BUILD_DIRS)
@- $(RM) -rf $(OTHER_BUILD_DIR)
@- $(RM) -rf $(BUILD_DIR_LINK)
@- $(RM) -rf $(DISTRIBUTE_DIR)
@- $(RM) $(PY$(PROJECT)_SO)
@- $(RM) $(MAT$(PROJECT)_SO)
supercleanfiles:
$(eval SUPERCLEAN_FILES := $(strip \
$(foreach ext,$(SUPERCLEAN_EXTS), $(shell find . -name '*$(ext)' \
-not -path './data/*'))))
supercleanlist: supercleanfiles
@ \
if [ -z "$(SUPERCLEAN_FILES)" ]; then \
echo "No generated files found."; \
else \
echo $(SUPERCLEAN_FILES) | tr ' ' '\n'; \
fi
superclean: clean supercleanfiles
@ \
if [ -z "$(SUPERCLEAN_FILES)" ]; then \
echo "No generated files found."; \
else \
echo "Deleting the following generated files:"; \
echo $(SUPERCLEAN_FILES) | tr ' ' '\n'; \
$(RM) $(SUPERCLEAN_FILES); \
fi
$(DIST_ALIASES): $(DISTRIBUTE_DIR)
$(DISTRIBUTE_DIR): all py | $(DISTRIBUTE_SUBDIRS)
# add proto
cp -r src/caffe/proto $(DISTRIBUTE_DIR)/
# add include
cp -r include $(DISTRIBUTE_DIR)/
mkdir -p $(DISTRIBUTE_DIR)/include/caffe/proto
cp $(PROTO_GEN_HEADER_SRCS) $(DISTRIBUTE_DIR)/include/caffe/proto
# add tool and example binaries
cp $(TOOL_BINS) $(DISTRIBUTE_DIR)/bin
cp $(EXAMPLE_BINS) $(DISTRIBUTE_DIR)/bin
# add libraries
cp $(STATIC_NAME) $(DISTRIBUTE_DIR)/lib
install -m 644 $(DYNAMIC_NAME) $(DISTRIBUTE_DIR)/lib
cd $(DISTRIBUTE_DIR)/lib; rm -f $(DYNAMIC_NAME_SHORT); ln -s $(DYNAMIC_VERSIONED_NAME_SHORT) $(DYNAMIC_NAME_SHORT)
# add python - it's not the standard way, indeed...
cp -r python $(DISTRIBUTE_DIR)/
-include $(DEPS)
ssd文件中/ssd/python/caffe/model_libs.py脚本内容:
改的是
pad = int((kernel_size + (dilation - 1) * (kernel_size - 1)) - 1) // 2
因为python3整除用//
import os
import caffe
from caffe import layers as L
from caffe import params as P
from caffe.proto import caffe_pb2
def check_if_exist(path):
return os.path.exists(path)
def make_if_not_exist(path):
if not os.path.exists(path):
os.makedirs(path)
def UnpackVariable(var, num):
#assert len > 0
if type(var) is list and len(var) == num:
return var
else:
ret = []
if type(var) is list:
assert len(var) == 1
for i in range(0, num):
ret.append(var[0])
else:
for i in range(0, num):
ret.append(var)
return ret
def ConvBNLayer(net, from_layer, out_layer, use_bn, use_relu, num_output,
kernel_size, pad, stride, dilation=1, use_scale=True, lr_mult=1,
conv_prefix='', conv_postfix='', bn_prefix='', bn_postfix='_bn',
scale_prefix='', scale_postfix='_scale', bias_prefix='', bias_postfix='_bias',
**bn_params):
if use_bn:
# parameters for convolution layer with batchnorm.
kwargs = {
'param': [dict(lr_mult=lr_mult, decay_mult=1)],
'weight_filler': dict(type='gaussian', std=0.01),
'bias_term': False,
}
eps = bn_params.get('eps', 0.001)
moving_average_fraction = bn_params.get('moving_average_fraction', 0.999)
use_global_stats = bn_params.get('use_global_stats', False)
# parameters for batchnorm layer.
bn_kwargs = {
'param': [
dict(lr_mult=0, decay_mult=0),
dict(lr_mult=0, decay_mult=0),
dict(lr_mult=0, decay_mult=0)],
'eps': eps,
'moving_average_fraction': moving_average_fraction,
}
bn_lr_mult = lr_mult
if use_global_stats:
# only specify if use_global_stats is explicitly provided;
# otherwise, use_global_stats_ = this->phase_ == TEST;
bn_kwargs = {
'param': [
dict(lr_mult=0, decay_mult=0),
dict(lr_mult=0, decay_mult=0),
dict(lr_mult=0, decay_mult=0)],
'eps': eps,
'use_global_stats': use_global_stats,
}
# not updating scale/bias parameters
bn_lr_mult = 0
# parameters for scale bias layer after batchnorm.
if use_scale:
sb_kwargs = {
'bias_term': True,
'param': [
dict(lr_mult=bn_lr_mult, decay_mult=0),
dict(lr_mult=bn_lr_mult, decay_mult=0)],
'filler': dict(type='constant', value=1.0),
'bias_filler': dict(type='constant', value=0.0),
}
else:
bias_kwargs = {
'param': [dict(lr_mult=bn_lr_mult, decay_mult=0)],
'filler': dict(type='constant', value=0.0),
}
else:
kwargs = {
'param': [
dict(lr_mult=lr_mult, decay_mult=1),
dict(lr_mult=2 * lr_mult, decay_mult=0)],
'weight_filler': dict(type='xavier'),
'bias_filler': dict(type='constant', value=0)
}
conv_name = '{}{}{}'.format(conv_prefix, out_layer, conv_postfix)
[kernel_h, kernel_w] = UnpackVariable(kernel_size, 2)
[pad_h, pad_w] = UnpackVariable(pad, 2)
[stride_h, stride_w] = UnpackVariable(stride, 2)
if kernel_h == kernel_w:
net[conv_name] = L.Convolution(net[from_layer], num_output=num_output,
kernel_size=kernel_h, pad=pad_h, stride=stride_h, **kwargs)
else:
net[conv_name] = L.Convolution(net[from_layer], num_output=num_output,
kernel_h=kernel_h, kernel_w=kernel_w, pad_h=pad_h, pad_w=pad_w,
stride_h=stride_h, stride_w=stride_w, **kwargs)
if dilation > 1:
net.update(conv_name, {'dilation': dilation})
if use_bn:
bn_name = '{}{}{}'.format(bn_prefix, out_layer, bn_postfix)
net[bn_name] = L.BatchNorm(net[conv_name], in_place=True, **bn_kwargs)
if use_scale:
sb_name = '{}{}{}'.format(scale_prefix, out_layer, scale_postfix)
net[sb_name] = L.Scale(net[bn_name], in_place=True, **sb_kwargs)
else:
bias_name = '{}{}{}'.format(bias_prefix, out_layer, bias_postfix)
net[bias_name] = L.Bias(net[bn_name], in_place=True, **bias_kwargs)
if use_relu:
relu_name = '{}_relu'.format(conv_name)
net[relu_name] = L.ReLU(net[conv_name], in_place=True)
def ResBody(net, from_layer, block_name, out2a, out2b, out2c, stride, use_branch1, dilation=1, **bn_param):
# ResBody(net, 'pool1', '2a', 64, 64, 256, 1, True)
conv_prefix = 'res{}_'.format(block_name)
conv_postfix = ''
bn_prefix = 'bn{}_'.format(block_name)
bn_postfix = ''
scale_prefix = 'scale{}_'.format(block_name)
scale_postfix = ''
use_scale = True
if use_branch1:
branch_name = 'branch1'
ConvBNLayer(net, from_layer, branch_name, use_bn=True, use_relu=False,
num_output=out2c, kernel_size=1, pad=0, stride=stride, use_scale=use_scale,
conv_prefix=conv_prefix, conv_postfix=conv_postfix,
bn_prefix=bn_prefix, bn_postfix=bn_postfix,
scale_prefix=scale_prefix, scale_postfix=scale_postfix, **bn_param)
branch1 = '{}{}'.format(conv_prefix, branch_name)
else:
branch1 = from_layer
branch_name = 'branch2a'
ConvBNLayer(net, from_layer, branch_name, use_bn=True, use_relu=True,
num_output=out2a, kernel_size=1, pad=0, stride=stride, use_scale=use_scale,
conv_prefix=conv_prefix, conv_postfix=conv_postfix,
bn_prefix=bn_prefix, bn_postfix=bn_postfix,
scale_prefix=scale_prefix, scale_postfix=scale_postfix, **bn_param)
out_name = '{}{}'.format(conv_prefix, branch_name)
branch_name = 'branch2b'
if dilation == 1:
ConvBNLayer(net, out_name, branch_name, use_bn=True, use_relu=True,
num_output=out2b, kernel_size=3, pad=1, stride=1, use_scale=use_scale,
conv_prefix=conv_prefix, conv_postfix=conv_postfix,
bn_prefix=bn_prefix, bn_postfix=bn_postfix,
scale_prefix=scale_prefix, scale_postfix=scale_postfix, **bn_param)
else:
pad = int((3 + (dilation - 1) * 2) - 1) // 2
ConvBNLayer(net, out_name, branch_name, use_bn=True, use_relu=True,
num_output=out2b, kernel_size=3, pad=pad, stride=1, use_scale=use_scale,
dilation=dilation, conv_prefix=conv_prefix, conv_postfix=conv_postfix,
bn_prefix=bn_prefix, bn_postfix=bn_postfix,
scale_prefix=scale_prefix, scale_postfix=scale_postfix, **bn_param)
out_name = '{}{}'.format(conv_prefix, branch_name)
branch_name = 'branch2c'
ConvBNLayer(net, out_name, branch_name, use_bn=True, use_relu=False,
num_output=out2c, kernel_size=1, pad=0, stride=1, use_scale=use_scale,
conv_prefix=conv_prefix, conv_postfix=conv_postfix,
bn_prefix=bn_prefix, bn_postfix=bn_postfix,
scale_prefix=scale_prefix, scale_postfix=scale_postfix, **bn_param)
branch2 = '{}{}'.format(conv_prefix, branch_name)
res_name = 'res{}'.format(block_name)
net[res_name] = L.Eltwise(net[branch1], net[branch2])
relu_name = '{}_relu'.format(res_name)
net[relu_name] = L.ReLU(net[res_name], in_place=True)
def InceptionTower(net, from_layer, tower_name, layer_params, **bn_param):
use_scale = False
for param in layer_params:
tower_layer = '{}/{}'.format(tower_name, param['name'])
del param['name']
if 'pool' in tower_layer:
net[tower_layer] = L.Pooling(net[from_layer], **param)
else:
param.update(bn_param)
ConvBNLayer(net, from_layer, tower_layer, use_bn=True, use_relu=True,
use_scale=use_scale, **param)
from_layer = tower_layer
return net[from_layer]
def CreateAnnotatedDataLayer(source, batch_size=32, backend=P.Data.LMDB,
output_label=True, train=True, label_map_file='', anno_type=None,
transform_param={}, batch_sampler=[{}]):
if train:
kwargs = {
'include': dict(phase=caffe_pb2.Phase.Value('TRAIN')),
'transform_param': transform_param,
}
else:
kwargs = {
'include': dict(phase=caffe_pb2.Phase.Value('TEST')),
'transform_param': transform_param,
}
ntop = 1
if output_label:
ntop = 2
annotated_data_param = {
'label_map_file': label_map_file,
'batch_sampler': batch_sampler,
}
if anno_type is not None:
annotated_data_param.update({'anno_type': anno_type})
return L.AnnotatedData(name="data", annotated_data_param=annotated_data_param,
data_param=dict(batch_size=batch_size, backend=backend, source=source),
ntop=ntop, **kwargs)
def ZFNetBody(net, from_layer, need_fc=True, fully_conv=False, reduced=False,
dilated=False, dropout=True, need_fc8=False, freeze_layers=[]):
kwargs = {
'param': [dict(lr_mult=1, decay_mult=1), dict(lr_mult=2, decay_mult=0)],
'weight_filler': dict(type='xavier'),
'bias_filler': dict(type='constant', value=0)}
assert from_layer in net.keys()
net.conv1 = L.Convolution(net[from_layer], num_output=96, pad=3, kernel_size=7, stride=2, **kwargs)
net.relu1 = L.ReLU(net.conv1, in_place=True)
net.norm1 = L.LRN(net.relu1, local_size=3, alpha=0.00005, beta=0.75,
norm_region=P.LRN.WITHIN_CHANNEL, engine=P.LRN.CAFFE)
net.pool1 = L.Pooling(net.norm1, pool=P.Pooling.MAX, pad=1, kernel_size=3, stride=2)
net.conv2 = L.Convolution(net.pool1, num_output=256, pad=2, kernel_size=5, stride=2, **kwargs)
net.relu2 = L.ReLU(net.conv2, in_place=True)
net.norm2 = L.LRN(net.relu2, local_size=3, alpha=0.00005, beta=0.75,
norm_region=P.LRN.WITHIN_CHANNEL, engine=P.LRN.CAFFE)
net.pool2 = L.Pooling(net.norm2, pool=P.Pooling.MAX, pad=1, kernel_size=3, stride=2)
net.conv3 = L.Convolution(net.pool2, num_output=384, pad=1, kernel_size=3, **kwargs)
net.relu3 = L.ReLU(net.conv3, in_place=True)
net.conv4 = L.Convolution(net.relu3, num_output=384, pad=1, kernel_size=3, **kwargs)
net.relu4 = L.ReLU(net.conv4, in_place=True)
net.conv5 = L.Convolution(net.relu4, num_output=256, pad=1, kernel_size=3, **kwargs)
net.relu5 = L.ReLU(net.conv5, in_place=True)
if need_fc:
if dilated:
name = 'pool5'
net[name] = L.Pooling(net.relu5, pool=P.Pooling.MAX, pad=1, kernel_size=3, stride=1)
else:
name = 'pool5'
net[name] = L.Pooling(net.relu5, pool=P.Pooling.MAX, pad=1, kernel_size=3, stride=2)
if fully_conv:
if dilated:
if reduced:
net.fc6 = L.Convolution(net[name], num_output=1024, pad=5, kernel_size=3, dilation=5, **kwargs)
else:
net.fc6 = L.Convolution(net[name], num_output=4096, pad=5, kernel_size=6, dilation=2, **kwargs)
else:
if reduced:
net.fc6 = L.Convolution(net[name], num_output=1024, pad=2, kernel_size=3, dilation=2, **kwargs)
else:
net.fc6 = L.Convolution(net[name], num_output=4096, pad=2, kernel_size=6, **kwargs)
net.relu6 = L.ReLU(net.fc6, in_place=True)
if dropout:
net.drop6 = L.Dropout(net.relu6, dropout_ratio=0.5, in_place=True)
if reduced:
net.fc7 = L.Convolution(net.relu6, num_output=1024, kernel_size=1, **kwargs)
else:
net.fc7 = L.Convolution(net.relu6, num_output=4096, kernel_size=1, **kwargs)
net.relu7 = L.ReLU(net.fc7, in_place=True)
if dropout:
net.drop7 = L.Dropout(net.relu7, dropout_ratio=0.5, in_place=True)
else:
net.fc6 = L.InnerProduct(net.pool5, num_output=4096)
net.relu6 = L.ReLU(net.fc6, in_place=True)
if dropout:
net.drop6 = L.Dropout(net.relu6, dropout_ratio=0.5, in_place=True)
net.fc7 = L.InnerProduct(net.relu6, num_output=4096)
net.relu7 = L.ReLU(net.fc7, in_place=True)
if dropout:
net.drop7 = L.Dropout(net.relu7, dropout_ratio=0.5, in_place=True)
if need_fc8:
from_layer = net.keys()[-1]
if fully_conv:
net.fc8 = L.Convolution(net[from_layer], num_output=1000, kernel_size=1, **kwargs)
else:
net.fc8 = L.InnerProduct(net[from_layer], num_output=1000)
net.prob = L.Softmax(net.fc8)
# Update freeze layers.
kwargs['param'] = [dict(lr_mult=0, decay_mult=0), dict(lr_mult=0, decay_mult=0)]
layers = net.keys()
for freeze_layer in freeze_layers:
if freeze_layer in layers:
net.update(freeze_layer, kwargs)
return net
def VGGNetBody(net, from_layer, need_fc=True, fully_conv=False, reduced=False,
dilated=False, nopool=False, dropout=True, freeze_layers=[], dilate_pool4=False):
kwargs = {
'param': [dict(lr_mult=1, decay_mult=1), dict(lr_mult=2, decay_mult=0)],
'weight_filler': dict(type='xavier'),
'bias_filler': dict(type='constant', value=0)}
assert from_layer in net.keys()
net.conv1_1 = L.Convolution(net[from_layer], num_output=64, pad=1, kernel_size=3, **kwargs)
net.relu1_1 = L.ReLU(net.conv1_1, in_place=True)
net.conv1_2 = L.Convolution(net.relu1_1, num_output=64, pad=1, kernel_size=3, **kwargs)
net.relu1_2 = L.ReLU(net.conv1_2, in_place=True)
if nopool:
name = 'conv1_3'
net[name] = L.Convolution(net.relu1_2, num_output=64, pad=1, kernel_size=3, stride=2, **kwargs)
else:
name = 'pool1'
net.pool1 = L.Pooling(net.relu1_2, pool=P.Pooling.MAX, kernel_size=2, stride=2)
net.conv2_1 = L.Convolution(net[name], num_output=128, pad=1, kernel_size=3, **kwargs)
net.relu2_1 = L.ReLU(net.conv2_1, in_place=True)
net.conv2_2 = L.Convolution(net.relu2_1, num_output=128, pad=1, kernel_size=3, **kwargs)
net.relu2_2 = L.ReLU(net.conv2_2, in_place=True)
if nopool:
name = 'conv2_3'
net[name] = L.Convolution(net.relu2_2, num_output=128, pad=1, kernel_size=3, stride=2, **kwargs)
else:
name = 'pool2'
net[name] = L.Pooling(net.relu2_2, pool=P.Pooling.MAX, kernel_size=2, stride=2)
net.conv3_1 = L.Convolution(net[name], num_output=256, pad=1, kernel_size=3, **kwargs)
net.relu3_1 = L.ReLU(net.conv3_1, in_place=True)
net.conv3_2 = L.Convolution(net.relu3_1, num_output=256, pad=1, kernel_size=3, **kwargs)
net.relu3_2 = L.ReLU(net.conv3_2, in_place=True)
net.conv3_3 = L.Convolution(net.relu3_2, num_output=256, pad=1, kernel_size=3, **kwargs)
net.relu3_3 = L.ReLU(net.conv3_3, in_place=True)
if nopool:
name = 'conv3_4'
net[name] = L.Convolution(net.relu3_3, num_output=256, pad=1, kernel_size=3, stride=2, **kwargs)
else:
name = 'pool3'
net[name] = L.Pooling(net.relu3_3, pool=P.Pooling.MAX, kernel_size=2, stride=2)
net.conv4_1 = L.Convolution(net[name], num_output=512, pad=1, kernel_size=3, **kwargs)
net.relu4_1 = L.ReLU(net.conv4_1, in_place=True)
net.conv4_2 = L.Convolution(net.relu4_1, num_output=512, pad=1, kernel_size=3, **kwargs)
net.relu4_2 = L.ReLU(net.conv4_2, in_place=True)
net.conv4_3 = L.Convolution(net.relu4_2, num_output=512, pad=1, kernel_size=3, **kwargs)
net.relu4_3 = L.ReLU(net.conv4_3, in_place=True)
if nopool:
name = 'conv4_4'
net[name] = L.Convolution(net.relu4_3, num_output=512, pad=1, kernel_size=3, stride=2, **kwargs)
else:
name = 'pool4'
if dilate_pool4:
net[name] = L.Pooling(net.relu4_3, pool=P.Pooling.MAX, kernel_size=3, stride=1, pad=1)
dilation = 2
else:
net[name] = L.Pooling(net.relu4_3, pool=P.Pooling.MAX, kernel_size=2, stride=2)
dilation = 1
kernel_size = 3
pad = int((kernel_size + (dilation - 1) * (kernel_size - 1)) - 1) // 2
net.conv5_1 = L.Convolution(net[name], num_output=512, pad=pad, kernel_size=kernel_size, dilation=dilation, **kwargs)
net.relu5_1 = L.ReLU(net.conv5_1, in_place=True)
net.conv5_2 = L.Convolution(net.relu5_1, num_output=512, pad=pad, kernel_size=kernel_size, dilation=dilation, **kwargs)
net.relu5_2 = L.ReLU(net.conv5_2, in_place=True)
net.conv5_3 = L.Convolution(net.relu5_2, num_output=512, pad=pad, kernel_size=kernel_size, dilation=dilation, **kwargs)
net.relu5_3 = L.ReLU(net.conv5_3, in_place=True)
if need_fc:
if dilated:
if nopool:
name = 'conv5_4'
net[name] = L.Convolution(net.relu5_3, num_output=512, pad=1, kernel_size=3, stride=1, **kwargs)
else:
name = 'pool5'
net[name] = L.Pooling(net.relu5_3, pool=P.Pooling.MAX, pad=1, kernel_size=3, stride=1)
else:
if nopool:
name = 'conv5_4'
net[name] = L.Convolution(net.relu5_3, num_output=512, pad=1, kernel_size=3, stride=2, **kwargs)
else:
name = 'pool5'
net[name] = L.Pooling(net.relu5_3, pool=P.Pooling.MAX, kernel_size=2, stride=2)
if fully_conv:
if dilated:
if reduced:
dilation = dilation * 6
kernel_size = 3
num_output = 1024
else:
dilation = dilation * 2
kernel_size = 7
num_output = 4096
else:
if reduced:
dilation = dilation * 3
kernel_size = 3
num_output = 1024
else:
kernel_size = 7
num_output = 4096
pad = int((kernel_size + (dilation - 1) * (kernel_size - 1)) - 1) // 2
net.fc6 = L.Convolution(net[name], num_output=num_output, pad=pad, kernel_size=kernel_size, dilation=dilation, **kwargs)
net.relu6 = L.ReLU(net.fc6, in_place=True)
if dropout:
net.drop6 = L.Dropout(net.relu6, dropout_ratio=0.5, in_place=True)
if reduced:
net.fc7 = L.Convolution(net.relu6, num_output=1024, kernel_size=1, **kwargs)
else:
net.fc7 = L.Convolution(net.relu6, num_output=4096, kernel_size=1, **kwargs)
net.relu7 = L.ReLU(net.fc7, in_place=True)
if dropout:
net.drop7 = L.Dropout(net.relu7, dropout_ratio=0.5, in_place=True)
else:
net.fc6 = L.InnerProduct(net.pool5, num_output=4096)
net.relu6 = L.ReLU(net.fc6, in_place=True)
if dropout:
net.drop6 = L.Dropout(net.relu6, dropout_ratio=0.5, in_place=True)
net.fc7 = L.InnerProduct(net.relu6, num_output=4096)
net.relu7 = L.ReLU(net.fc7, in_place=True)
if dropout:
net.drop7 = L.Dropout(net.relu7, dropout_ratio=0.5, in_place=True)
# Update freeze layers.
kwargs['param'] = [dict(lr_mult=0, decay_mult=0), dict(lr_mult=0, decay_mult=0)]
layers = net.keys()
for freeze_layer in freeze_layers:
if freeze_layer in layers:
net.update(freeze_layer, kwargs)
return net
def ResNet101Body(net, from_layer, use_pool5=True, use_dilation_conv5=False, **bn_param):
conv_prefix = ''
conv_postfix = ''
bn_prefix = 'bn_'
bn_postfix = ''
scale_prefix = 'scale_'
scale_postfix = ''
ConvBNLayer(net, from_layer, 'conv1', use_bn=True, use_relu=True,
num_output=64, kernel_size=7, pad=3, stride=2,
conv_prefix=conv_prefix, conv_postfix=conv_postfix,
bn_prefix=bn_prefix, bn_postfix=bn_postfix,
scale_prefix=scale_prefix, scale_postfix=scale_postfix, **bn_param)
net.pool1 = L.Pooling(net.conv1, pool=P.Pooling.MAX, kernel_size=3, stride=2)
ResBody(net, 'pool1', '2a', out2a=64, out2b=64, out2c=256, stride=1, use_branch1=True, **bn_param)
ResBody(net, 'res2a', '2b', out2a=64, out2b=64, out2c=256, stride=1, use_branch1=False, **bn_param)
ResBody(net, 'res2b', '2c', out2a=64, out2b=64, out2c=256, stride=1, use_branch1=False, **bn_param)
ResBody(net, 'res2c', '3a', out2a=128, out2b=128, out2c=512, stride=2, use_branch1=True, **bn_param)
from_layer = 'res3a'
for i in range(1, 4):
block_name = '3b{}'.format(i)
ResBody(net, from_layer, block_name, out2a=128, out2b=128, out2c=512, stride=1, use_branch1=False, **bn_param)
from_layer = 'res{}'.format(block_name)
ResBody(net, from_layer, '4a', out2a=256, out2b=256, out2c=1024, stride=2, use_branch1=True, **bn_param)
from_layer = 'res4a'
for i in range(1, 23):
block_name = '4b{}'.format(i)
ResBody(net, from_layer, block_name, out2a=256, out2b=256, out2c=1024, stride=1, use_branch1=False, **bn_param)
from_layer = 'res{}'.format(block_name)
stride = 2
dilation = 1
if use_dilation_conv5:
stride = 1
dilation = 2
ResBody(net, from_layer, '5a', out2a=512, out2b=512, out2c=2048, stride=stride, use_branch1=True, dilation=dilation, **bn_param)
ResBody(net, 'res5a', '5b', out2a=512, out2b=512, out2c=2048, stride=1, use_branch1=False, dilation=dilation, **bn_param)
ResBody(net, 'res5b', '5c', out2a=512, out2b=512, out2c=2048, stride=1, use_branch1=False, dilation=dilation, **bn_param)
if use_pool5:
net.pool5 = L.Pooling(net.res5c, pool=P.Pooling.AVE, global_pooling=True)
return net
def ResNet152Body(net, from_layer, use_pool5=True, use_dilation_conv5=False, **bn_param):
conv_prefix = ''
conv_postfix = ''
bn_prefix = 'bn_'
bn_postfix = ''
scale_prefix = 'scale_'
scale_postfix = ''
ConvBNLayer(net, from_layer, 'conv1', use_bn=True, use_relu=True,
num_output=64, kernel_size=7, pad=3, stride=2,
conv_prefix=conv_prefix, conv_postfix=conv_postfix,
bn_prefix=bn_prefix, bn_postfix=bn_postfix,
scale_prefix=scale_prefix, scale_postfix=scale_postfix, **bn_param)
net.pool1 = L.Pooling(net.conv1, pool=P.Pooling.MAX, kernel_size=3, stride=2)
ResBody(net, 'pool1', '2a', out2a=64, out2b=64, out2c=256, stride=1, use_branch1=True, **bn_param)
ResBody(net, 'res2a', '2b', out2a=64, out2b=64, out2c=256, stride=1, use_branch1=False, **bn_param)
ResBody(net, 'res2b', '2c', out2a=64, out2b=64, out2c=256, stride=1, use_branch1=False, **bn_param)
ResBody(net, 'res2c', '3a', out2a=128, out2b=128, out2c=512, stride=2, use_branch1=True, **bn_param)
from_layer = 'res3a'
for i in range(1, 8):
block_name = '3b{}'.format(i)
ResBody(net, from_layer, block_name, out2a=128, out2b=128, out2c=512, stride=1, use_branch1=False, **bn_param)
from_layer = 'res{}'.format(block_name)
ResBody(net, from_layer, '4a', out2a=256, out2b=256, out2c=1024, stride=2, use_branch1=True, **bn_param)
from_layer = 'res4a'
for i in range(1, 36):
block_name = '4b{}'.format(i)
ResBody(net, from_layer, block_name, out2a=256, out2b=256, out2c=1024, stride=1, use_branch1=False, **bn_param)
from_layer = 'res{}'.format(block_name)
stride = 2
dilation = 1
if use_dilation_conv5:
stride = 1
dilation = 2
ResBody(net, from_layer, '5a', out2a=512, out2b=512, out2c=2048, stride=stride, use_branch1=True, dilation=dilation, **bn_param)
ResBody(net, 'res5a', '5b', out2a=512, out2b=512, out2c=2048, stride=1, use_branch1=False, dilation=dilation, **bn_param)
ResBody(net, 'res5b', '5c', out2a=512, out2b=512, out2c=2048, stride=1, use_branch1=False, dilation=dilation, **bn_param)
if use_pool5:
net.pool5 = L.Pooling(net.res5c, pool=P.Pooling.AVE, global_pooling=True)
return net
def InceptionV3Body(net, from_layer, output_pred=False, **bn_param):
# scale is fixed to 1, thus we ignore it.
use_scale = False
out_layer = 'conv'
ConvBNLayer(net, from_layer, out_layer, use_bn=True, use_relu=True,
num_output=32, kernel_size=3, pad=0, stride=2, use_scale=use_scale,
**bn_param)
from_layer = out_layer
out_layer = 'conv_1'
ConvBNLayer(net, from_layer, out_layer, use_bn=True, use_relu=True,
num_output=32, kernel_size=3, pad=0, stride=1, use_scale=use_scale,
**bn_param)
from_layer = out_layer
out_layer = 'conv_2'
ConvBNLayer(net, from_layer, out_layer, use_bn=True, use_relu=True,
num_output=64, kernel_size=3, pad=1, stride=1, use_scale=use_scale,
**bn_param)
from_layer = out_layer
out_layer = 'pool'
net[out_layer] = L.Pooling(net[from_layer], pool=P.Pooling.MAX,
kernel_size=3, stride=2, pad=0)
from_layer = out_layer
out_layer = 'conv_3'
ConvBNLayer(net, from_layer, out_layer, use_bn=True, use_relu=True,
num_output=80, kernel_size=1, pad=0, stride=1, use_scale=use_scale,
**bn_param)
from_layer = out_layer
out_layer = 'conv_4'
ConvBNLayer(net, from_layer, out_layer, use_bn=True, use_relu=True,
num_output=192, kernel_size=3, pad=0, stride=1, use_scale=use_scale,
**bn_param)
from_layer = out_layer
out_layer = 'pool_1'
net[out_layer] = L.Pooling(net[from_layer], pool=P.Pooling.MAX,
kernel_size=3, stride=2, pad=0)
from_layer = out_layer
# inceptions with 1x1, 3x3, 5x5 convolutions
for inception_id in range(0, 3):
if inception_id == 0:
out_layer = 'mixed'
tower_2_conv_num_output = 32
else:
out_layer = 'mixed_{}'.format(inception_id)
tower_2_conv_num_output = 64
towers = []
tower_name = '{}'.format(out_layer)
tower = InceptionTower(net, from_layer, tower_name, [
dict(name='conv', num_output=64, kernel_size=1, pad=0, stride=1),
], **bn_param)
towers.append(tower)
tower_name = '{}/tower'.format(out_layer)
tower = InceptionTower(net, from_layer, tower_name, [
dict(name='conv', num_output=48, kernel_size=1, pad=0, stride=1),
dict(name='conv_1', num_output=64, kernel_size=5, pad=2, stride=1),
], **bn_param)
towers.append(tower)
tower_name = '{}/tower_1'.format(out_layer)
tower = InceptionTower(net, from_layer, tower_name, [
dict(name='conv', num_output=64, kernel_size=1, pad=0, stride=1),
dict(name='conv_1', num_output=96, kernel_size=3, pad=1, stride=1),
dict(name='conv_2', num_output=96, kernel_size=3, pad=1, stride=1),
], **bn_param)
towers.append(tower)
tower_name = '{}/tower_2'.format(out_layer)
tower = InceptionTower(net, from_layer, tower_name, [
dict(name='pool', pool=P.Pooling.AVE, kernel_size=3, pad=1, stride=1),
dict(name='conv', num_output=tower_2_conv_num_output, kernel_size=1, pad=0, stride=1),
], **bn_param)
towers.append(tower)
out_layer = '{}/join'.format(out_layer)
net[out_layer] = L.Concat(*towers, axis=1)
from_layer = out_layer
# inceptions with 1x1, 3x3(in sequence) convolutions
out_layer = 'mixed_3'
towers = []
tower_name = '{}'.format(out_layer)
tower = InceptionTower(net, from_layer, tower_name, [
dict(name='conv', num_output=384, kernel_size=3, pad=0, stride=2),
], **bn_param)
towers.append(tower)
tower_name = '{}/tower'.format(out_layer)
tower = InceptionTower(net, from_layer, tower_name, [
dict(name='conv', num_output=64, kernel_size=1, pad=0, stride=1),
dict(name='conv_1', num_output=96, kernel_size=3, pad=1, stride=1),
dict(name='conv_2', num_output=96, kernel_size=3, pad=0, stride=2),
], **bn_param)
towers.append(tower)
tower_name = '{}'.format(out_layer)
tower = InceptionTower(net, from_layer, tower_name, [
dict(name='pool', pool=P.Pooling.MAX, kernel_size=3, pad=0, stride=2),
], **bn_param)
towers.append(tower)
out_layer = '{}/join'.format(out_layer)
net[out_layer] = L.Concat(*towers, axis=1)
from_layer = out_layer
# inceptions with 1x1, 7x1, 1x7 convolutions
for inception_id in range(4, 8):
if inception_id == 4:
num_output = 128
elif inception_id == 5 or inception_id == 6:
num_output = 160
elif inception_id == 7:
num_output = 192
out_layer = 'mixed_{}'.format(inception_id)
towers = []
tower_name = '{}'.format(out_layer)
tower = InceptionTower(net, from_layer, tower_name, [
dict(name='conv', num_output=192, kernel_size=1, pad=0, stride=1),
], **bn_param)
towers.append(tower)
tower_name = '{}/tower'.format(out_layer)
tower = InceptionTower(net, from_layer, tower_name, [
dict(name='conv', num_output=num_output, kernel_size=1, pad=0, stride=1),
dict(name='conv_1', num_output=num_output, kernel_size=[1, 7], pad=[0, 3], stride=[1, 1]),
dict(name='conv_2', num_output=192, kernel_size=[7, 1], pad=[3, 0], stride=[1, 1]),
], **bn_param)
towers.append(tower)
tower_name = '{}/tower_1'.format(out_layer)
tower = InceptionTower(net, from_layer, tower_name, [
dict(name='conv', num_output=num_output, kernel_size=1, pad=0, stride=1),
dict(name='conv_1', num_output=num_output, kernel_size=[7, 1], pad=[3, 0], stride=[1, 1]),
dict(name='conv_2', num_output=num_output, kernel_size=[1, 7], pad=[0, 3], stride=[1, 1]),
dict(name='conv_3', num_output=num_output, kernel_size=[7, 1], pad=[3, 0], stride=[1, 1]),
dict(name='conv_4', num_output=192, kernel_size=[1, 7], pad=[0, 3], stride=[1, 1]),
], **bn_param)
towers.append(tower)
tower_name = '{}/tower_2'.format(out_layer)
tower = InceptionTower(net, from_layer, tower_name, [
dict(name='pool', pool=P.Pooling.AVE, kernel_size=3, pad=1, stride=1),
dict(name='conv', num_output=192, kernel_size=1, pad=0, stride=1),
], **bn_param)
towers.append(tower)
out_layer = '{}/join'.format(out_layer)
net[out_layer] = L.Concat(*towers, axis=1)
from_layer = out_layer
# inceptions with 1x1, 3x3, 1x7, 7x1 filters
out_layer = 'mixed_8'
towers = []
tower_name = '{}/tower'.format(out_layer)
tower = InceptionTower(net, from_layer, tower_name, [
dict(name='conv', num_output=192, kernel_size=1, pad=0, stride=1),
dict(name='conv_1', num_output=320, kernel_size=3, pad=0, stride=2),
], **bn_param)
towers.append(tower)
tower_name = '{}/tower_1'.format(out_layer)
tower = InceptionTower(net, from_layer, tower_name, [
dict(name='conv', num_output=192, kernel_size=1, pad=0, stride=1),
dict(name='conv_1', num_output=192, kernel_size=[1, 7], pad=[0, 3], stride=[1, 1]),
dict(name='conv_2', num_output=192, kernel_size=[7, 1], pad=[3, 0], stride=[1, 1]),
dict(name='conv_3', num_output=192, kernel_size=3, pad=0, stride=2),
], **bn_param)
towers.append(tower)
tower_name = '{}'.format(out_layer)
tower = InceptionTower(net, from_layer, tower_name, [
dict(name='pool', pool=P.Pooling.MAX, kernel_size=3, pad=0, stride=2),
], **bn_param)
towers.append(tower)
out_layer = '{}/join'.format(out_layer)
net[out_layer] = L.Concat(*towers, axis=1)
from_layer = out_layer
for inception_id in range(9, 11):
num_output = 384
num_output2 = 448
if inception_id == 9:
pool = P.Pooling.AVE
else:
pool = P.Pooling.MAX
out_layer = 'mixed_{}'.format(inception_id)
towers = []
tower_name = '{}'.format(out_layer)
tower = InceptionTower(net, from_layer, tower_name, [
dict(name='conv', num_output=320, kernel_size=1, pad=0, stride=1),
], **bn_param)
towers.append(tower)
tower_name = '{}/tower'.format(out_layer)
tower = InceptionTower(net, from_layer, tower_name, [
dict(name='conv', num_output=num_output, kernel_size=1, pad=0, stride=1),
], **bn_param)
subtowers = []
subtower_name = '{}/mixed'.format(tower_name)
subtower = InceptionTower(net, '{}/conv'.format(tower_name), subtower_name, [
dict(name='conv', num_output=num_output, kernel_size=[1, 3], pad=[0, 1], stride=[1, 1]),
], **bn_param)
subtowers.append(subtower)
subtower = InceptionTower(net, '{}/conv'.format(tower_name), subtower_name, [
dict(name='conv_1', num_output=num_output, kernel_size=[3, 1], pad=[1, 0], stride=[1, 1]),
], **bn_param)
subtowers.append(subtower)
net[subtower_name] = L.Concat(*subtowers, axis=1)
towers.append(net[subtower_name])
tower_name = '{}/tower_1'.format(out_layer)
tower = InceptionTower(net, from_layer, tower_name, [
dict(name='conv', num_output=num_output2, kernel_size=1, pad=0, stride=1),
dict(name='conv_1', num_output=num_output, kernel_size=3, pad=1, stride=1),
], **bn_param)
subtowers = []
subtower_name = '{}/mixed'.format(tower_name)
subtower = InceptionTower(net, '{}/conv_1'.format(tower_name), subtower_name, [
dict(name='conv', num_output=num_output, kernel_size=[1, 3], pad=[0, 1], stride=[1, 1]),
], **bn_param)
subtowers.append(subtower)
subtower = InceptionTower(net, '{}/conv_1'.format(tower_name), subtower_name, [
dict(name='conv_1', num_output=num_output, kernel_size=[3, 1], pad=[1, 0], stride=[1, 1]),
], **bn_param)
subtowers.append(subtower)
net[subtower_name] = L.Concat(*subtowers, axis=1)
towers.append(net[subtower_name])
tower_name = '{}/tower_2'.format(out_layer)
tower = InceptionTower(net, from_layer, tower_name, [
dict(name='pool', pool=pool, kernel_size=3, pad=1, stride=1),
dict(name='conv', num_output=192, kernel_size=1, pad=0, stride=1),
], **bn_param)
towers.append(tower)
out_layer = '{}/join'.format(out_layer)
net[out_layer] = L.Concat(*towers, axis=1)
from_layer = out_layer
if output_pred:
net.pool_3 = L.Pooling(net[from_layer], pool=P.Pooling.AVE, kernel_size=8, pad=0, stride=1)
net.softmax = L.InnerProduct(net.pool_3, num_output=1008)
net.softmax_prob = L.Softmax(net.softmax)
return net
def CreateMultiBoxHead(net, data_layer="data", num_classes=[], from_layers=[],
use_objectness=False, normalizations=[], use_batchnorm=True, lr_mult=1,
use_scale=True, min_sizes=[], max_sizes=[], prior_variance = [0.1],
aspect_ratios=[], steps=[], img_height=0, img_width=0, share_location=True,
flip=True, clip=True, offset=0.5, inter_layer_depth=[], kernel_size=1, pad=0,
conf_postfix='', loc_postfix='', **bn_param):
assert num_classes, "must provide num_classes"
assert num_classes > 0, "num_classes must be positive number"
if normalizations:
assert len(from_layers) == len(normalizations), "from_layers and normalizations should have same length"
assert len(from_layers) == len(min_sizes), "from_layers and min_sizes should have same length"
if max_sizes:
assert len(from_layers) == len(max_sizes), "from_layers and max_sizes should have same length"
if aspect_ratios:
assert len(from_layers) == len(aspect_ratios), "from_layers and aspect_ratios should have same length"
if steps:
assert len(from_layers) == len(steps), "from_layers and steps should have same length"
net_layers = net.keys()
assert data_layer in net_layers, "data_layer is not in net's layers"
if inter_layer_depth:
assert len(from_layers) == len(inter_layer_depth), "from_layers and inter_layer_depth should have same length"
num = len(from_layers)
priorbox_layers = []
loc_layers = []
conf_layers = []
objectness_layers = []
for i in range(0, num):
from_layer = from_layers[i]
# Get the normalize value.
if normalizations:
if normalizations[i] != -1:
norm_name = "{}_norm".format(from_layer)
net[norm_name] = L.Normalize(net[from_layer], scale_filler=dict(type="constant", value=normalizations[i]),
across_spatial=False, channel_shared=False)
from_layer = norm_name
# Add intermediate layers.
if inter_layer_depth:
if inter_layer_depth[i] > 0:
inter_name = "{}_inter".format(from_layer)
ConvBNLayer(net, from_layer, inter_name, use_bn=use_batchnorm, use_relu=True, lr_mult=lr_mult,
num_output=inter_layer_depth[i], kernel_size=3, pad=1, stride=1, **bn_param)
from_layer = inter_name
# Estimate number of priors per location given provided parameters.
min_size = min_sizes[i]
if type(min_size) is not list:
min_size = [min_size]
aspect_ratio = []
if len(aspect_ratios) > i:
aspect_ratio = aspect_ratios[i]
if type(aspect_ratio) is not list:
aspect_ratio = [aspect_ratio]
max_size = []
if len(max_sizes) > i:
max_size = max_sizes[i]
if type(max_size) is not list:
max_size = [max_size]
if max_size:
assert len(max_size) == len(min_size), "max_size and min_size should have same length."
if max_size:
num_priors_per_location = (2 + len(aspect_ratio)) * len(min_size)
else:
num_priors_per_location = (1 + len(aspect_ratio)) * len(min_size)
if flip:
num_priors_per_location += len(aspect_ratio) * len(min_size)
step = []
if len(steps) > i:
step = steps[i]
# Create location prediction layer.
name = "{}_mbox_loc{}".format(from_layer, loc_postfix)
num_loc_output = num_priors_per_location * 4;
if not share_location:
num_loc_output *= num_classes
ConvBNLayer(net, from_layer, name, use_bn=use_batchnorm, use_relu=False, lr_mult=lr_mult,
num_output=num_loc_output, kernel_size=kernel_size, pad=pad, stride=1, **bn_param)
permute_name = "{}_perm".format(name)
net[permute_name] = L.Permute(net[name], order=[0, 2, 3, 1])
flatten_name = "{}_flat".format(name)
net[flatten_name] = L.Flatten(net[permute_name], axis=1)
loc_layers.append(net[flatten_name])
# Create confidence prediction layer.
name = "{}_mbox_conf{}".format(from_layer, conf_postfix)
num_conf_output = num_priors_per_location * num_classes;
ConvBNLayer(net, from_layer, name, use_bn=use_batchnorm, use_relu=False, lr_mult=lr_mult,
num_output=num_conf_output, kernel_size=kernel_size, pad=pad, stride=1, **bn_param)
permute_name = "{}_perm".format(name)
net[permute_name] = L.Permute(net[name], order=[0, 2, 3, 1])
flatten_name = "{}_flat".format(name)
net[flatten_name] = L.Flatten(net[permute_name], axis=1)
conf_layers.append(net[flatten_name])
# Create prior generation layer.
name = "{}_mbox_priorbox".format(from_layer)
net[name] = L.PriorBox(net[from_layer], net[data_layer], min_size=min_size,
clip=clip, variance=prior_variance, offset=offset)
if max_size:
net.update(name, {'max_size': max_size})
if aspect_ratio:
net.update(name, {'aspect_ratio': aspect_ratio, 'flip': flip})
if step:
net.update(name, {'step': step})
if img_height != 0 and img_width != 0:
if img_height == img_width:
net.update(name, {'img_size': img_height})
else:
net.update(name, {'img_h': img_height, 'img_w': img_width})
priorbox_layers.append(net[name])
# Create objectness prediction layer.
if use_objectness:
name = "{}_mbox_objectness".format(from_layer)
num_obj_output = num_priors_per_location * 2;
ConvBNLayer(net, from_layer, name, use_bn=use_batchnorm, use_relu=False, lr_mult=lr_mult,
num_output=num_obj_output, kernel_size=kernel_size, pad=pad, stride=1, **bn_param)
permute_name = "{}_perm".format(name)
net[permute_name] = L.Permute(net[name], order=[0, 2, 3, 1])
flatten_name = "{}_flat".format(name)
net[flatten_name] = L.Flatten(net[permute_name], axis=1)
objectness_layers.append(net[flatten_name])
# Concatenate priorbox, loc, and conf layers.
mbox_layers = []
name = "mbox_loc"
net[name] = L.Concat(*loc_layers, axis=1)
mbox_layers.append(net[name])
name = "mbox_conf"
net[name] = L.Concat(*conf_layers, axis=1)
mbox_layers.append(net[name])
name = "mbox_priorbox"
net[name] = L.Concat(*priorbox_layers, axis=2)
mbox_layers.append(net[name])
if use_objectness:
name = "mbox_objectness"
net[name] = L.Concat(*objectness_layers, axis=1)
mbox_layers.append(net[name])
return mbox_layers
SSD文件下:/examples/ssd/ssd_pascal_webcam.py文件内容
import sys
sys.path.insert(0,"/home/yuyuang/ssd/python")
import caffe
from caffe.model_libs import *
from google.protobuf import text_format
import math
import os
import shutil
import stat
import subprocess
import sys
# Add extra layers on top of a "base" network (e.g. VGGNet or Inception).
def AddExtraLayers(net, use_batchnorm=True, lr_mult=1):
use_relu = True
# Add additional convolutional layers.
# 19 x 19
from_layer = list(net.keys())[-1]
# TODO(weiliu89): Construct the name using the last layer to avoid duplication.
# 10 x 10
out_layer = "conv6_1"
ConvBNLayer(net, from_layer, out_layer, use_batchnorm, use_relu, 256, 1, 0, 1,
lr_mult=lr_mult)
from_layer = out_layer
out_layer = "conv6_2"
ConvBNLayer(net, from_layer, out_layer, use_batchnorm, use_relu, 512, 3, 1, 2,
lr_mult=lr_mult)
# 5 x 5
from_layer = out_layer
out_layer = "conv7_1"
ConvBNLayer(net, from_layer, out_layer, use_batchnorm, use_relu, 128, 1, 0, 1,
lr_mult=lr_mult)
from_layer = out_layer
out_layer = "conv7_2"
ConvBNLayer(net, from_layer, out_layer, use_batchnorm, use_relu, 256, 3, 1, 2,
lr_mult=lr_mult)
# 3 x 3
from_layer = out_layer
out_layer = "conv8_1"
ConvBNLayer(net, from_layer, out_layer, use_batchnorm, use_relu, 128, 1, 0, 1,
lr_mult=lr_mult)
from_layer = out_layer
out_layer = "conv8_2"
ConvBNLayer(net, from_layer, out_layer, use_batchnorm, use_relu, 256, 3, 0, 1,
lr_mult=lr_mult)
# 1 x 1
from_layer = out_layer
out_layer = "conv9_1"
ConvBNLayer(net, from_layer, out_layer, use_batchnorm, use_relu, 128, 1, 0, 1,
lr_mult=lr_mult)
from_layer = out_layer
out_layer = "conv9_2"
ConvBNLayer(net, from_layer, out_layer, use_batchnorm, use_relu, 256, 3, 0, 1,
lr_mult=lr_mult)
return net
### Modify the following parameters accordingly ###
# The directory which contains the caffe code.
# We assume you are running the script at the CAFFE_ROOT.
caffe_root = os.getcwd()
# Set true if you want to start training right after generating all files.
run_soon = True
# The device id for webcam
webcam_id = 0
# Number of frames to be skipped.
skip_frames = 0
# The parameters for the webcam demo
# Key parameters used in training
# If true, use batch norm for all newly added layers.
# Currently only the non batch norm version has been tested.
use_batchnorm = False
num_classes = 21
share_location = True
background_label_id=0
conf_loss_type = P.MultiBoxLoss.SOFTMAX
code_type = P.PriorBox.CENTER_SIZE
lr_mult = 1.
# Stores LabelMapItem.
label_map_file = "data/VOC0712/labelmap_voc.prototxt"
# The resized image size
resize_width = 300
resize_height = 300
# Parameters needed for test.
# Set the number of test iterations to the maximum integer number.
test_iter = int(math.pow(2, 29) - 1)
# Use GPU or CPU
solver_mode = P.Solver.GPU
# Defining which GPUs to use.
gpus = "0"
# Number of frames to be processed per batch.
test_batch_size = 1
# Only display high quality detections whose scores are higher than a threshold.
visualize_threshold = 0.6
# Size of webcam image.
webcam_width = 640
webcam_height = 480
# Scale the image size for display.
scale = 1.5
### Hopefully you don't need to change the following ###
resize = "{}x{}".format(resize_width, resize_height)
video_data_param = {
'video_type': P.VideoData.WEBCAM,
'device_id': webcam_id,
'skip_frames': skip_frames,
}
test_transform_param = {
'mean_value': [104, 117, 123],
'resize_param': {
'prob': 1,
'resize_mode': P.Resize.WARP,
'height': resize_height,
'width': resize_width,
'interp_mode': [P.Resize.LINEAR],
},
}
output_transform_param = {
'mean_value': [104, 117, 123],
'resize_param': {
'prob': 1,
'resize_mode': P.Resize.WARP,
'height': int(webcam_height * scale),
'width': int(webcam_width * scale),
'interp_mode': [P.Resize.LINEAR],
},
}
# parameters for generating detection output.
det_out_param = {
'num_classes': num_classes,
'share_location': share_location,
'background_label_id': background_label_id,
'nms_param': {'nms_threshold': 0.45, 'top_k': 400},
'save_output_param': {
'label_map_file': label_map_file,
},
'keep_top_k': 200,
'confidence_threshold': 0.01,
'code_type': code_type,
'visualize': True,
'visualize_threshold': visualize_threshold,
}
# The job name should be same as the name used in examples/ssd/ssd_pascal.py.
job_name = "SSD_{}".format(resize)
# The name of the model. Modify it if you want.
model_name = "VGG_VOC0712_{}".format(job_name)
# Directory which stores the model .prototxt file.
save_dir = "models/VGGNet/VOC0712/{}_webcam".format(job_name)
# Directory which stores the snapshot of trained models.
snapshot_dir = "models/VGGNet/VOC0712/{}".format(job_name)
# Directory which stores the job script and log file.
job_dir = "jobs/VGGNet/VOC0712/{}_webcam".format(job_name)
# model definition files.
test_net_file = "{}/test.prototxt".format(save_dir)
# snapshot prefix.
snapshot_prefix = "{}/{}".format(snapshot_dir, model_name)
# job script path.
job_file = "{}/{}.sh".format(job_dir, model_name)
# Find most recent snapshot.
max_iter = 0
for file in os.listdir(snapshot_dir):
if file.endswith(".caffemodel"):
basename = os.path.splitext(file)[0]
iter = int(basename.split("{}_iter_".format(model_name))[1])
if iter > max_iter:
max_iter = iter
if max_iter == 0:
print("Cannot find snapshot in {}".format(snapshot_dir))
sys.exit()
# The resume model.
pretrain_model = "{}_iter_{}.caffemodel".format(snapshot_prefix, max_iter)
# parameters for generating priors.
# minimum dimension of input image
min_dim = 300
# conv4_3 ==> 38 x 38
# fc7 ==> 19 x 19
# conv6_2 ==> 10 x 10
# conv7_2 ==> 5 x 5
# conv8_2 ==> 3 x 3
# conv9_2 ==> 1 x 1
mbox_source_layers = ['conv4_3', 'fc7', 'conv6_2', 'conv7_2', 'conv8_2', 'conv9_2']
# in percent %
min_ratio = 20
max_ratio = 90
step = int(math.floor((max_ratio - min_ratio) / (len(mbox_source_layers) - 2)))
min_sizes = []
max_sizes = []
for ratio in range(min_ratio, max_ratio + 1, step):
min_sizes.append(min_dim * ratio / 100.)
max_sizes.append(min_dim * (ratio + step) / 100.)
min_sizes = [min_dim * 10 / 100.] + min_sizes
max_sizes = [min_dim * 20 / 100.] + max_sizes
steps = [8, 16, 32, 64, 100, 300]
aspect_ratios = [[2], [2, 3], [2, 3], [2, 3], [2], [2]]
# L2 normalize conv4_3.
normalizations = [20, -1, -1, -1, -1, -1]
# variance used to encode/decode prior bboxes.
if code_type == P.PriorBox.CENTER_SIZE:
prior_variance = [0.1, 0.1, 0.2, 0.2]
else:
prior_variance = [0.1]
flip = True
clip = False
# Check file.
check_if_exist(label_map_file)
check_if_exist(pretrain_model)
make_if_not_exist(save_dir)
make_if_not_exist(job_dir)
make_if_not_exist(snapshot_dir)
# Create test net.
net = caffe.NetSpec()
net.data = L.VideoData(video_data_param=video_data_param,
data_param=dict(batch_size=test_batch_size),
transform_param=test_transform_param)
VGGNetBody(net, from_layer='data', fully_conv=True, reduced=True, dilated=True,
dropout=False)
AddExtraLayers(net, use_batchnorm, lr_mult=lr_mult)
mbox_layers = CreateMultiBoxHead(net, data_layer='data', from_layers=mbox_source_layers,
use_batchnorm=use_batchnorm, min_sizes=min_sizes, max_sizes=max_sizes,
aspect_ratios=aspect_ratios, steps=steps, normalizations=normalizations,
num_classes=num_classes, share_location=share_location, flip=flip, clip=clip,
prior_variance=prior_variance, kernel_size=3, pad=1, lr_mult=lr_mult)
conf_name = "mbox_conf"
if conf_loss_type == P.MultiBoxLoss.SOFTMAX:
reshape_name = "{}_reshape".format(conf_name)
net[reshape_name] = L.Reshape(net[conf_name], shape=dict(dim=[0, -1, num_classes]))
softmax_name = "{}_softmax".format(conf_name)
net[softmax_name] = L.Softmax(net[reshape_name], axis=2)
flatten_name = "{}_flatten".format(conf_name)
net[flatten_name] = L.Flatten(net[softmax_name], axis=1)
mbox_layers[1] = net[flatten_name]
elif conf_loss_type == P.MultiBoxLoss.LOGISTIC:
sigmoid_name = "{}_sigmoid".format(conf_name)
net[sigmoid_name] = L.Sigmoid(net[conf_name])
mbox_layers[1] = net[sigmoid_name]
mbox_layers.append(net.data)
net.detection_out = L.DetectionOutput(*mbox_layers,
detection_output_param=det_out_param,
transform_param=output_transform_param,
include=dict(phase=caffe_pb2.Phase.Value('TEST')))
net.slience = L.Silence(net.detection_out, ntop=0,
include=dict(phase=caffe_pb2.Phase.Value('TEST')))
with open(test_net_file, 'w') as f:
print('name: "{}_test"'.format(model_name), file=f)
print(net.to_proto(), file=f)
shutil.copy(test_net_file, job_dir)
# Create job file.
with open(job_file, 'w') as f:
f.write('cd {}\n'.format(caffe_root))
f.write('./build/tools/caffe test \\\n')
f.write('--model="{}" \\\n'.format(test_net_file))
f.write('--weights="{}" \\\n'.format(pretrain_model))
f.write('--iterations="{}" \\\n'.format(test_iter))
if solver_mode == P.Solver.GPU:
f.write('--gpu {}\n'.format(gpus))
# Copy the python script to job_dir.
py_file = os.path.abspath(__file__)
shutil.copy(py_file, job_dir)
# Run the job.
os.chmod(job_file, stat.S_IRWXU)
if run_soon:
subprocess.call(job_file, shell=True)

















 491
491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









